Zipkin 是一款开源的链路追踪系统,它是基于Dapper论文设计的,由 Twitter 公司开发贡献。我们先来看 Zipkin 的系统架构图,它展现了 Zipkin 的整体工作流程:
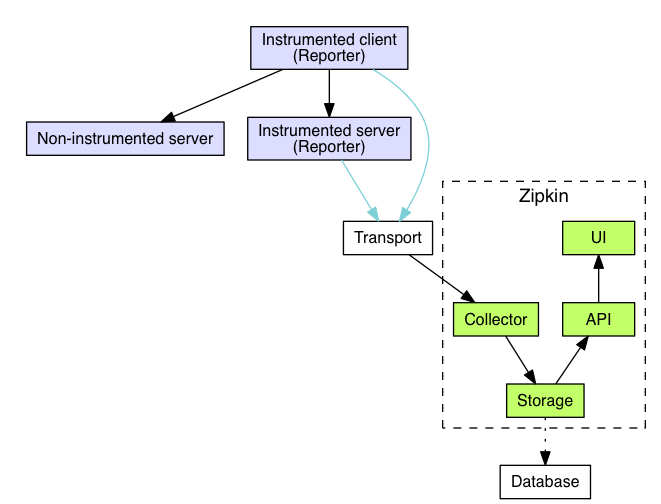
这一部分涉及到链路采集、数据收集和数据查看三个步骤,
- 链路采集。紫色的部分代表业务系统和组件,图中是以一个典型的 RPC 请求作为所需要追踪的链路,其中 client 为请求的发起方,分别请求了两个服务端。其中被观测的客户端和服务端会在启动的实例中增加数据上报的功能,这里的数据上报就是指从本实例中观测到的链路数据,一并上报到 Zipkin 中,传输工具常见的有 Kafka 或者 HTTP 请求。
- 数据传输到 Zipkin 的收集器后,会经过 Zipkin 的存储模块,存储到数据库中。目前支持的数据库有 MySQL、ElasticSearch、Cassandra 这几种类型,具体的数据库选择可以根据公司内部运维的实力评估出最适合的。
- 数据查看。Zipkin 提供了一套完整的 UI 界面来查询,这套 UI 界面依赖于一整套完整的 API 来处理请求。
在链路采集上,Zipkin 使用数据埋点的方式来进行观测。
1. Get Started
我们之间使用在Consul部分school和student代码来做测试。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
增加zipkin配置
spring:
zipkin:
baseUrl: http://192.168.159.131:9411
向schools发送请求后我们可以看到school的控制台打印了如下日志
2021-01-07 13:22:34.294 INFO [school-service,54e4379600572c35,54e4379600572c35,true] 14524 --- [nio-9001-exec-3] c.g.e.s.c.s.SchoolServiceController : Going to call student service to get data!
上面的日志括号内的内容包括了四段内容,即服务名称、TraceId、SpanId 和 Zipkin 标志位,它是格式如下所示:
[服务名称, TraceId, SpanId, Zipkin 标志位]
第一段中的 school-service代表着该服务的名称,使用的就是在 bootstrap.yml 中 spring.application.name 指定的服务名称。考虑到服务跟踪的需求,为服务指定一个统一而友好的名称是一项最佳实践。
第二段中的 TraceId 代表一次完整请求的唯一编号,上例中的 54e4379600572c35就是该次请求的唯一编号。可以通过 TraceId 查看完整的服务调用链路。
第三段中的SpanId代表一个服务之间的调用过程的唯一标识,TraceId 和 SpanId 是一对多的关系,即一个 TraceId 一般都会包含多个 SpanId,每一个 SpanId 都从属于特定的 TraceId。当然,也可以通过 SpanId 查看某一个服务调用过程的详细信息。
最后的第四段代表 Zipkin 标志位,该标志位用于识别是否将服务跟踪信息同步到 Zipkin。
我们可以在zipkin中找到对应的调用信息

根据这个traceId54e4379600572c35,我们在zipkin中看到调用时序
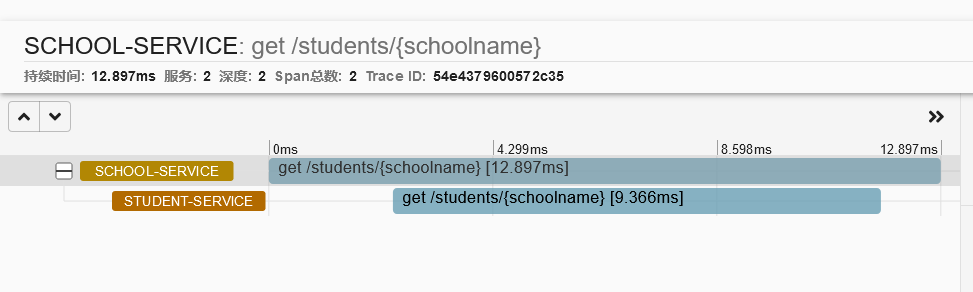
上图中最重要的就是各个 Span 信息。一个服务调用链路被分解成若干个 Span,每个 Span 代表完整调用链路中的一个可以衡量的部分。我们通过可视化的界面,可以看到整个访问链路的整体时长以及各个 Span 所花费的时间。每个 Span 的时延都已经被量化,并通过背景颜色的深浅来表示时延的大小。
在上图中,我们点击任何一个感兴趣的 Span 就可以获取该 Span 对应的各项服务调用数据明细。
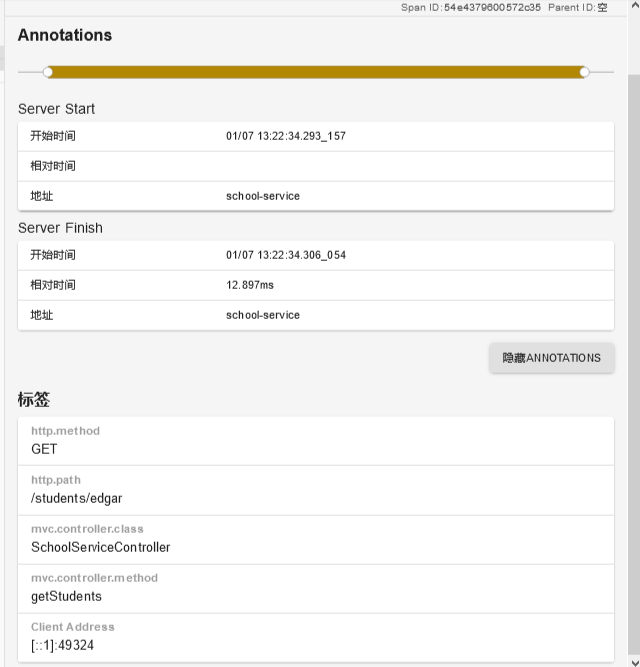
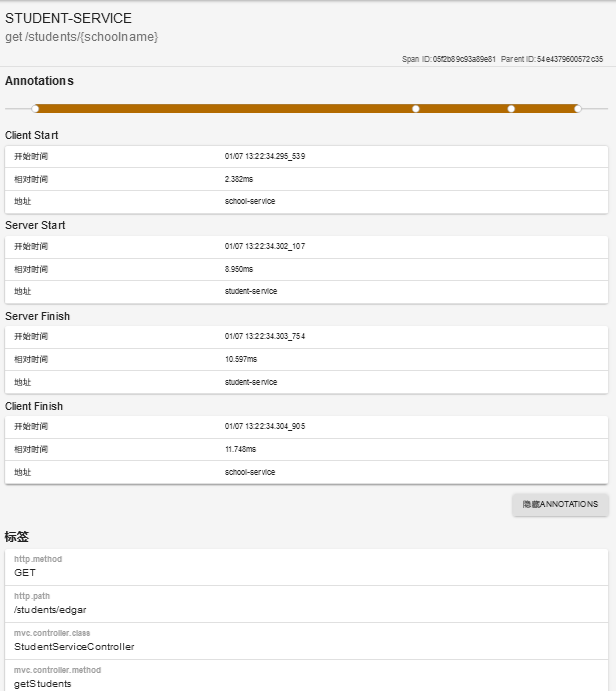
上图展示了针对该 Span 的 cs、sr、ss 和 cr 这四个关键事件数据,也可以看到这些数据包括 HTTP 请求相关的方法、路径等各项基础数据,也包括使用 Spring 构建 RESTful 风格调用时的 Controller 类以及端点信息。
最后,作为数据管理和展示的统一平台,Zipkin 还实现了更为低层的数据表现形式,也就是通过 JSON 数据提供对调用过程的详细描述。我们可以通过/zipkin/api/v2/trace/<traceId>来获取。
我们在student上抓取请求头,可以看到zipkin给请求加了4个请求头
x-b3-traceid : b96beae85a8baa87
x-b3-spanid : f70988295ef9c719
x-b3-parentspanid : b96beae85a8baa87
x-b3-sampled : 1
- x-b3-spanid:一个工作单元(rpc 调用)的唯一标识。
- x-b3-parentspanid:当前工作单元的上一个工作单元,Root Span(请求链路的第一个工作单元)的值为空。
- x-b3-traceid:一条请求链条(trace) 的唯一标识。
- x-b3-sampled:是否被抽样为输出的标志,1 为需要被输出,0 为不需要被输出。
2. 自定义span
虽然内置的日志埋点和采集功能已经能够满足日常开发的大多数场景需要,但如果我想在业务系统中重点监控某些业务操作时,我们需要创建自定义的 Span 并纳入可视化监控机制中。
Spring Cloud Sleuth 使用 Brave 作为其底层的服务跟踪实现框架,我们可以通过2种方式实现自定义Span功能:
- Brave 中的 Tracer 类
- 注解
2.1. Tracer 类
注入tracer
@Autowired
private Tracer tracer;
通过newTrace方法可以创建一个新的根 Span
public Span newTrace() {
return this._toSpan((TraceContext)null, this.newRootContext(0));
}
通过nextSpan方法可以添加新的 Span。这里获取当前 TraceContext,如果该上下文不存在,就通过 newTrace 方法来创建一个新的根 Span;如果存在,则基于这个上下文并调用 newChild 方法来创建一个子 Span。
public Span nextSpan() {
TraceContext parent = this.currentTraceContext.get();
return parent != null ? this.newChild(parent) : this.newTrace();
}
示例
// 创建一个新span
Span newSpan = tracer.nextSpan().name("db_query").start();
try {
...
} finally {
// 为tag打上标签
newSpan.tag("foo", "bar");
//指定类型以及时间
newSpan.annotate("myannotate");
newSpan.finish();
}
可以看到zipkin中的调用链中出现了我们创建的span
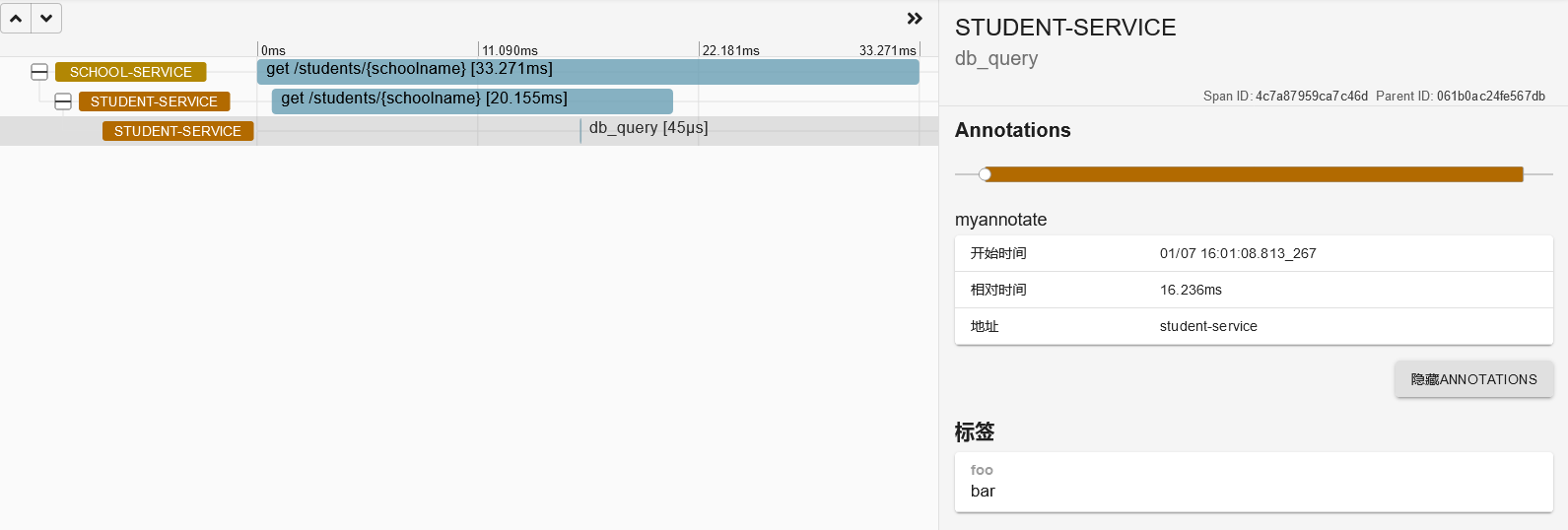
2.2. 注解
使用@NewSpan 注解,这个注解可以自动创建一个新的 Span,@SpanTag 注解用于自动为通过 @NewSpan 注解所创建的 Span 添加标签
@NewSpan("db_query")// 默认是方法名
public List<Student> getStudents(@PathVariable @SpanTag("school") String schoolname) {
}
3. 采样率
跟踪信息收集默认是 0.1(10%) 的采样比例,可通过 probability 属性修改;或可采用每秒速率来控制采集数据,属性是 rate。
# 跟踪信息收集采样比例,默认 0.1,为 1 是即 100%,收集所有
spring.sleuth.sampler.probability=1
# 每秒速率,即每秒最多能跟踪的请求,rate 优先
spring.sleuth.sampler.rate=50
4. 其他用法
In-process Tracing
ScopedSpan span = tracer.startScopedSpan("local");
span.tag("foo", "bar");
span.finish();
current span
SpanCustomizer span = CurrentSpanCustomizer.create(tracing);
获取traceId
tracing.currentTraceContext().get().traceId();
5. MySQL跟踪
前面我们已经了解了通过resttemplate发起远程调用的调用链跟踪,经过尝试使用RedisTemplate,KafkaTemplate均可以记录调用链,Spring Cloud Gateway也可以。但是JdbcTemplate却没有追踪。在网上找到了2个方法
使用brave-instrumentation-mysql的方法我用jdbctemplate没有成功,改用了p6spy成功了,后面再研究原因
5.1. brave-instrumentation-mysql
引入依赖
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-mysql</artifactId>
<version>5.13.3</version>
</dependency>
在jdbcurl中添加拦截器
url: jdbc:mysql://localhost:3306/ds0?statementInterceptors=brave.mysql.MySQLStatementInterceptor&zipkinServiceName=mysqlService
5.2. p6spy
引用依赖
<dependency>
<groupId>com.github.gavlyukovskiy</groupId>
<artifactId>p6spy-spring-boot-starter</artifactId>
<version>1.6.2</version>
</dependency>
再次测试我们可以看zipkin中多了JDBC的调用信息
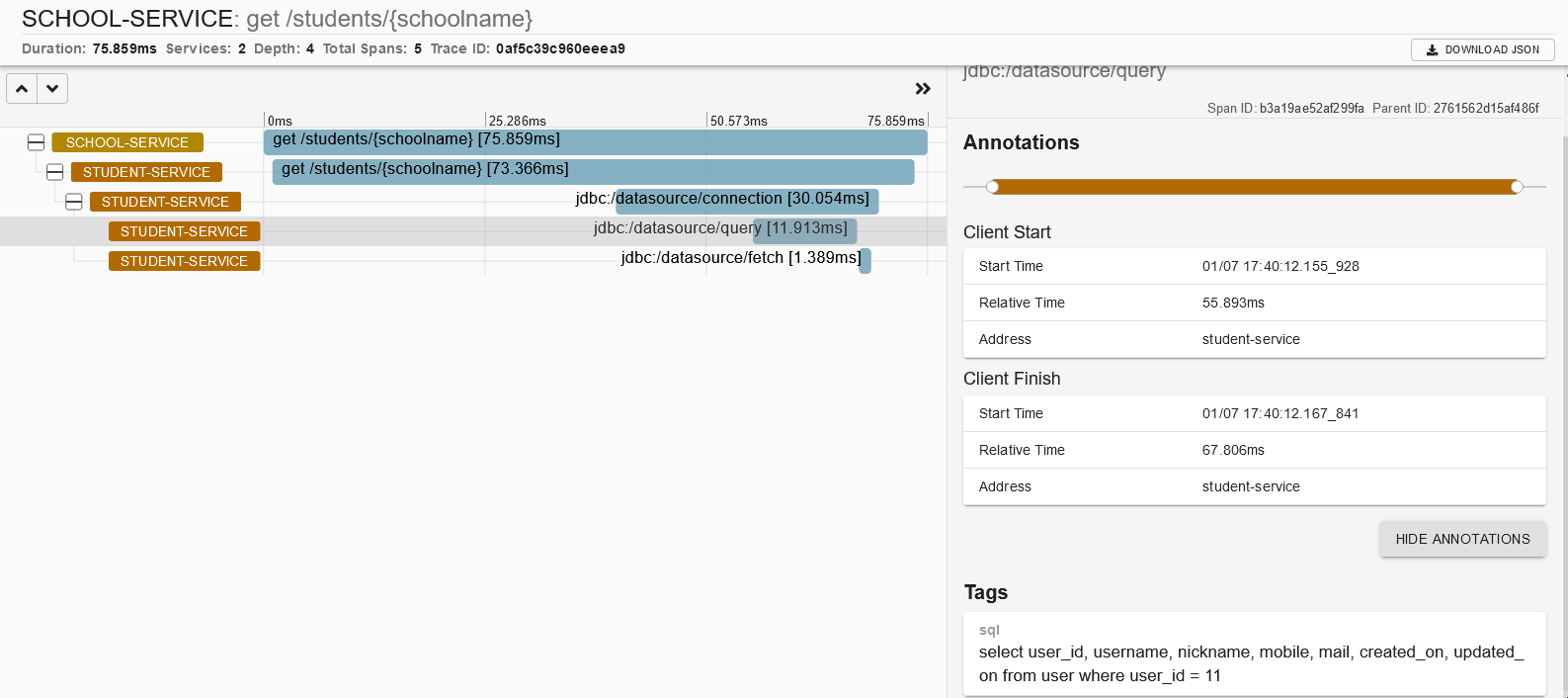
我们用可以调整跟踪参数
# Creates span for every connection and query. Works only with p6spy or datasource-proxy.
decorator.datasource.sleuth.enabled=true
# Specify traces that will be created in zipkin
decorator.datasource.sleuth.include=connection, query, fetch
更多信息参考https://github.com/gavlyukovskiy/spring-boot-data-source-decorator
6. 参考资料
《Spring Cloud 原理与实战 》
