本文直接复制的https://www.jianshu.com/p/055e4223d054,没有自己截图,不同的版本界面会有差异
1. 仪表盘
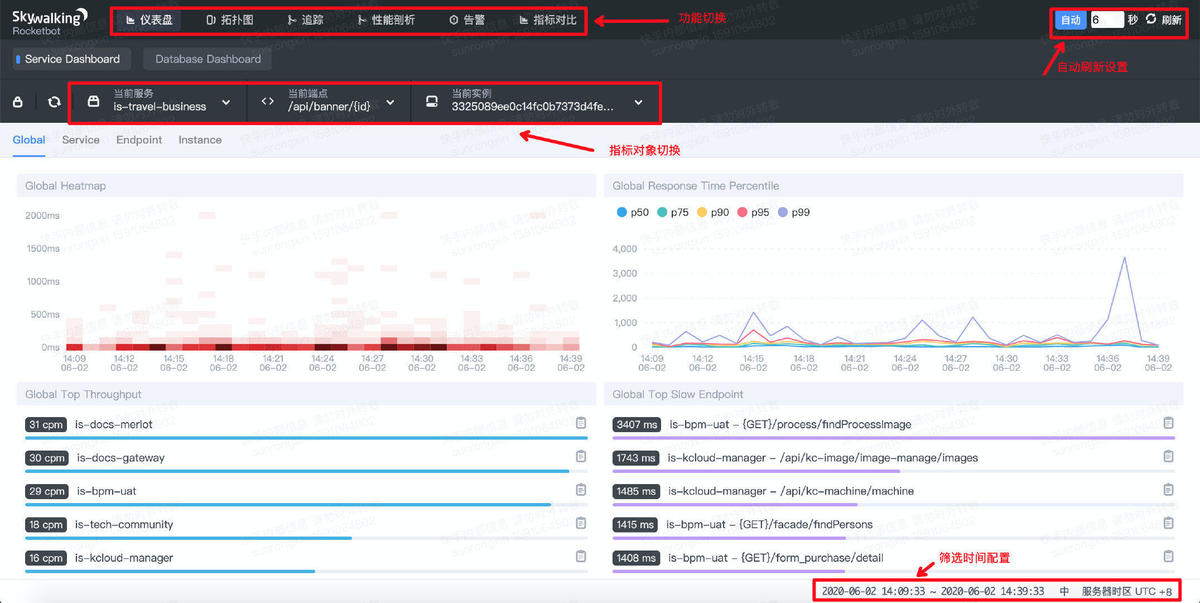
- 最上方为功能区,用来切换SW不同的功能
- 功能区下方为指标对象,SW的监控对象分为 服务、端点和实例三种;
- 右下角为时间区,用来设定统计指标的时间域(所有的指标展示都依赖与这个时间范围)。点击右上“自动”按钮可以开启自动刷新模式;
- 其余空间为指标盘展示区,用来展示各种指标信息。
这里着重介绍下 SkyWalking 中最重要的三个概念:
-
服务(Service) :表示对请求提供相同行为的一系列或一组工作负载。在使用 Agent 或 SDK 的时候,你可以定义服务的名字。如果不定义的话,SkyWalking 将会使用应用名称上定义的名字,为了和告警服务联动,这里推荐大家配置成应用中心中的应用名。
- 端点(Endpoint) :对于特定服务所接收的请求路径, 如 HTTP 的 URI 路径和 gRPC 服务的类名 + 方法签名。
- 服务实例(Service Instance) :上述的一组工作负载中的每一个工作负载称为一个实例。就像 Kubernetes 中的 pods 一样, 服务实例未必就是操作系统上的一个进程。但当你在使用 Agent 的时候, 一个服务实例实际就是操作系统上的一个真实进程。
SW所有的指标信息都是围绕三者展开的。
1.1. 服务指标
点击仪表盘,选择要查询的应用,如“is-file-store”, 再切换仪表盘为“Service”模式,即可查询对应服务的指标
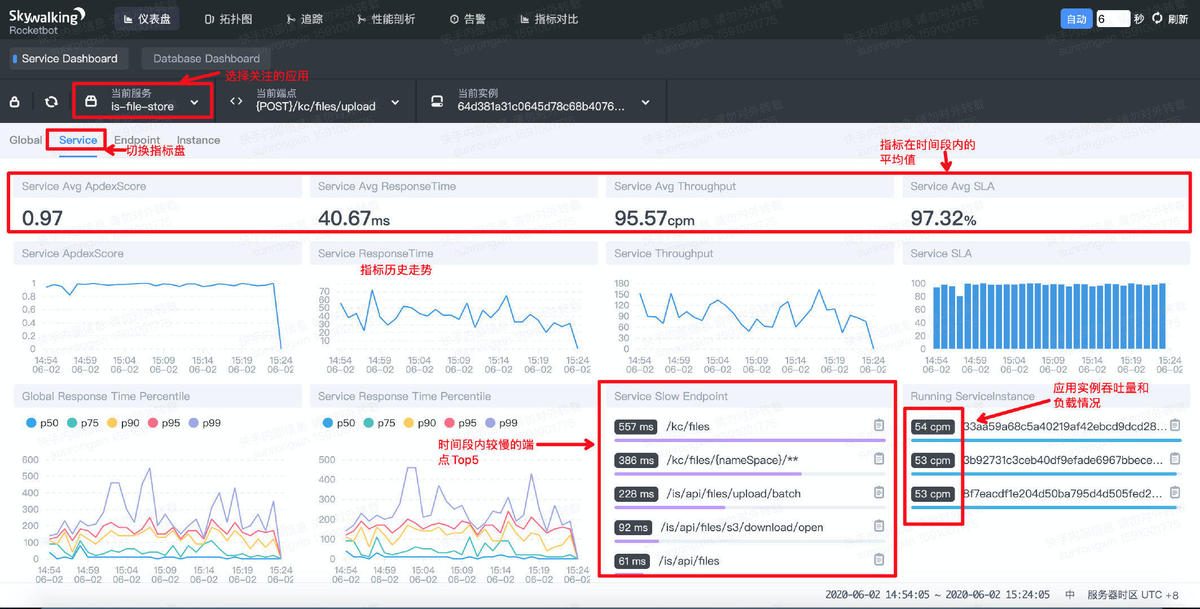
服务主要指标包括:
- ApdexScore : 性能指数,Apdex(Application Performance Index)是一个国际通用标准,Apdex 是用户对应用性能满意度的量化值。它提供了一个统一的测量和报告用户体验的方法,把最终用户的体验和应用性能作为一个完整的指标进行统一度量,其中最高为1最低为0;
- ResponseTime:响应时间,即在选定时间内,服务所有请求的平均响应时间(ms);
- Throughput: 吞吐量,即在选定时间内,每分钟服务响应的请求量(cpm)
- SLA: service level agreement,服务等级协议,SW中特指每分钟内响应成功请求的占比。
大盘中会列出以上指标的当前的平均值,和历史走势。
服务慢端点 Service Slow Endpoint
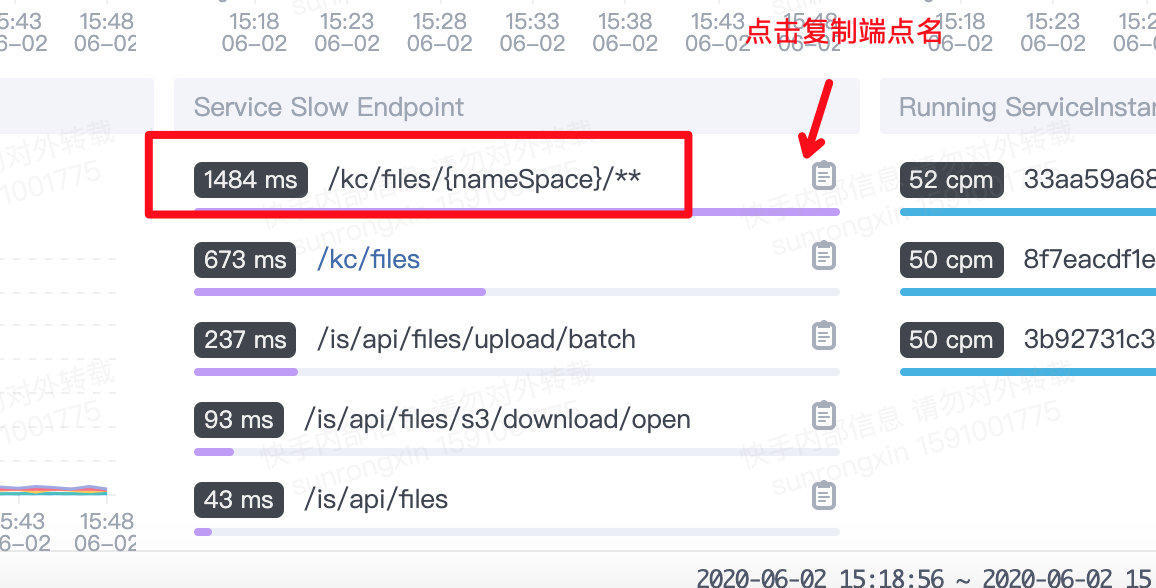
服务指标仪表盘会列举出当前服务响应时间最大的端点Top5,如果有端点的响应时间过高,则需要进一步关注其指标(点击可以复制端点名称)。
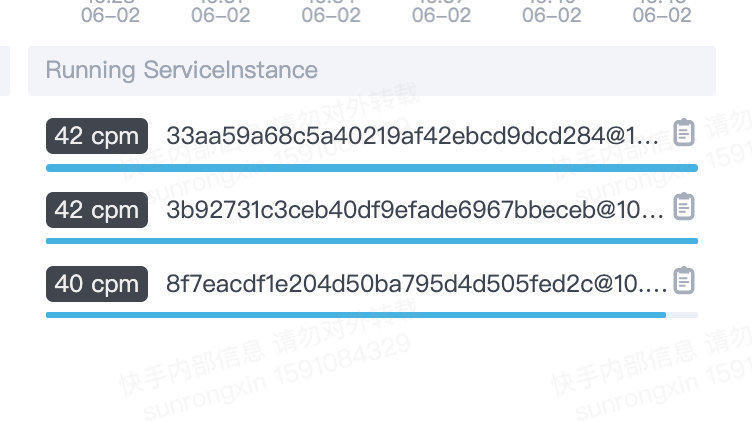
运行中的实例 Running ServiceInstance
该服务目前所有实例的吞吐量情况,通过此可以推断出实例之间的负载情况。如果发现某个实例吞吐量较低,就需要查询实例指标(如查询该实例是不是发生了GC,或则CPU利用率过高)
1.2. 端点指标
如果发现有端点的响应时间过高,可以进一步查询该端点的指标信息。和服务指标类似,端点指标也包括吞吐量、SLA、响应时间等指标,
端点仪表盘会有如下特有信息:
- Dependency Map: 依赖关系图,代表哪些服务在依赖(调用)该端点,如果是前端直接调用,会显示为用户(User)依赖中;
- Slow Traces: 即慢调用请求记录,SW会自动列出当前时间段内端点最慢的调用记录和TraceID,通过这个ID可以在追踪功能找到具体的调用链信息,便于定位。
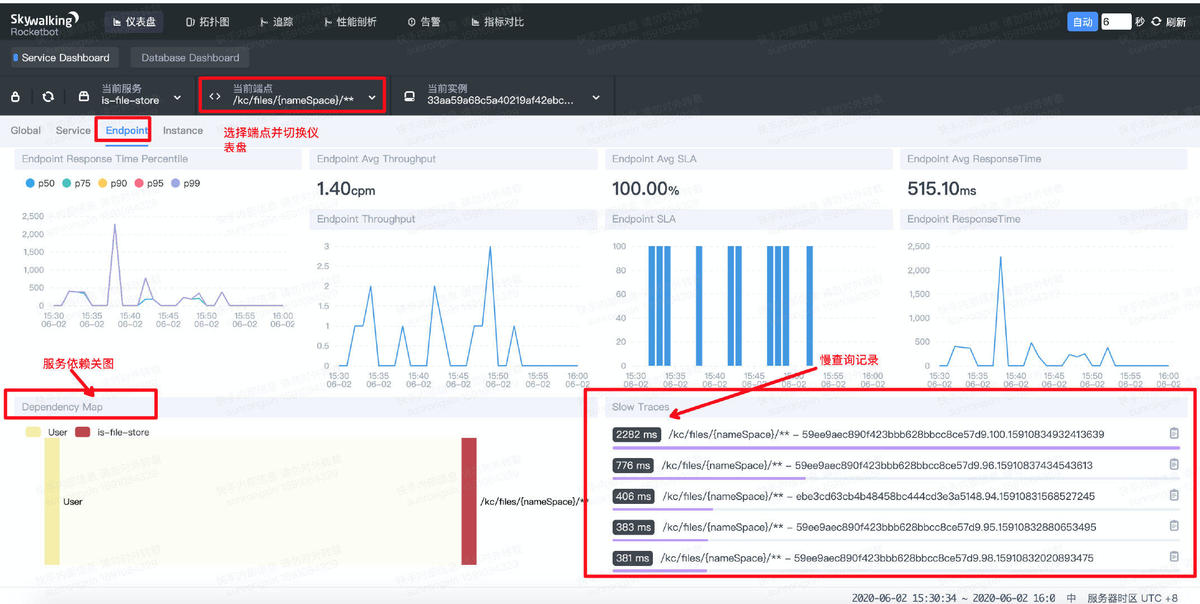
1.3. 服务实例指标
选择服务的实例并切换仪表盘,即可查看服务某个实例的指标数据。除了常规的吞吐量、SLA、响应时间等指标外,实例信息中还会给出JVM的信息,如堆栈使用量,GC耗时和次数等。
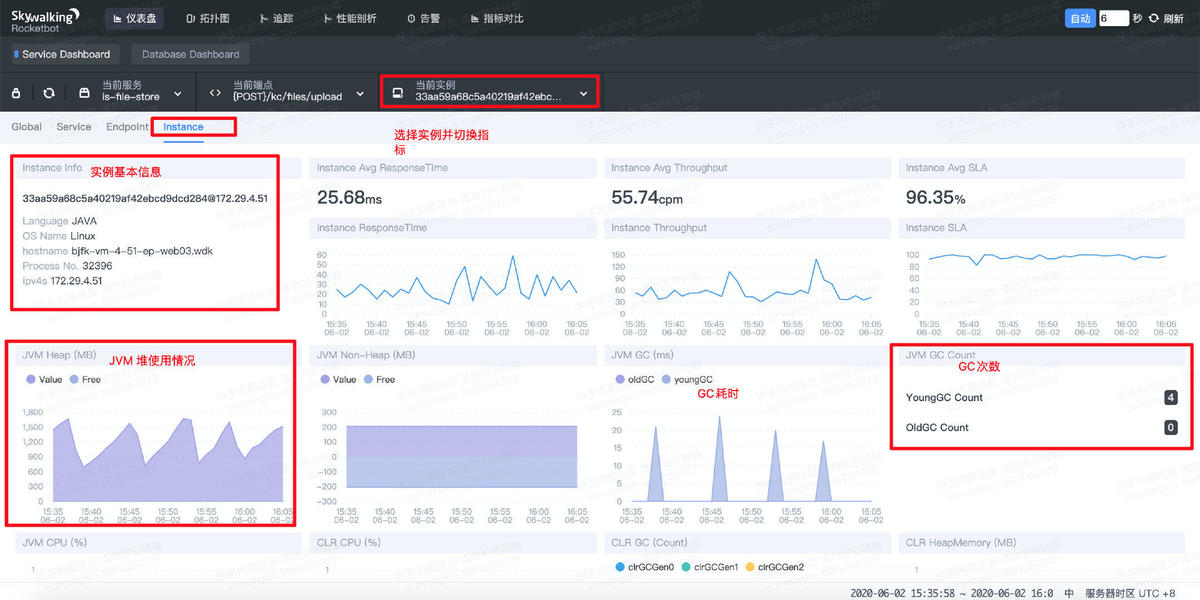
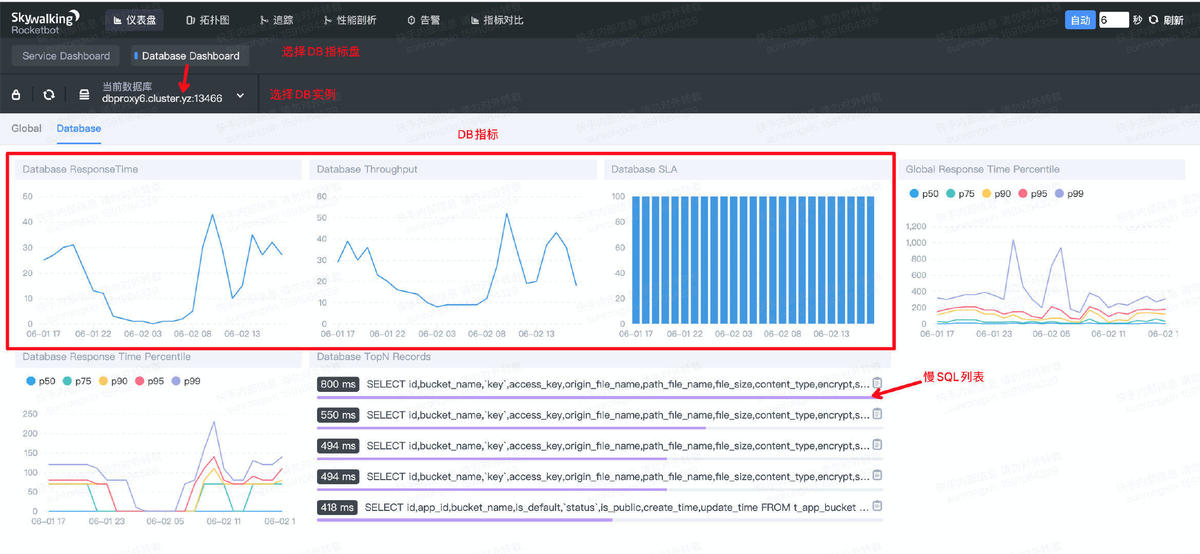
1.4. DB 数据指标查询
除了服务本身的指标,SW也监控了服务依赖的DB指标。切换DB指标盘并选择对应DB实例,就可以看到从服务角度(client)来看该DB实例的吞吐量、SLA、响应时间等指标。
更进一步,该DB执行慢SQL会被自动列出,可以直接粘贴出来,便于定位耗时原因。
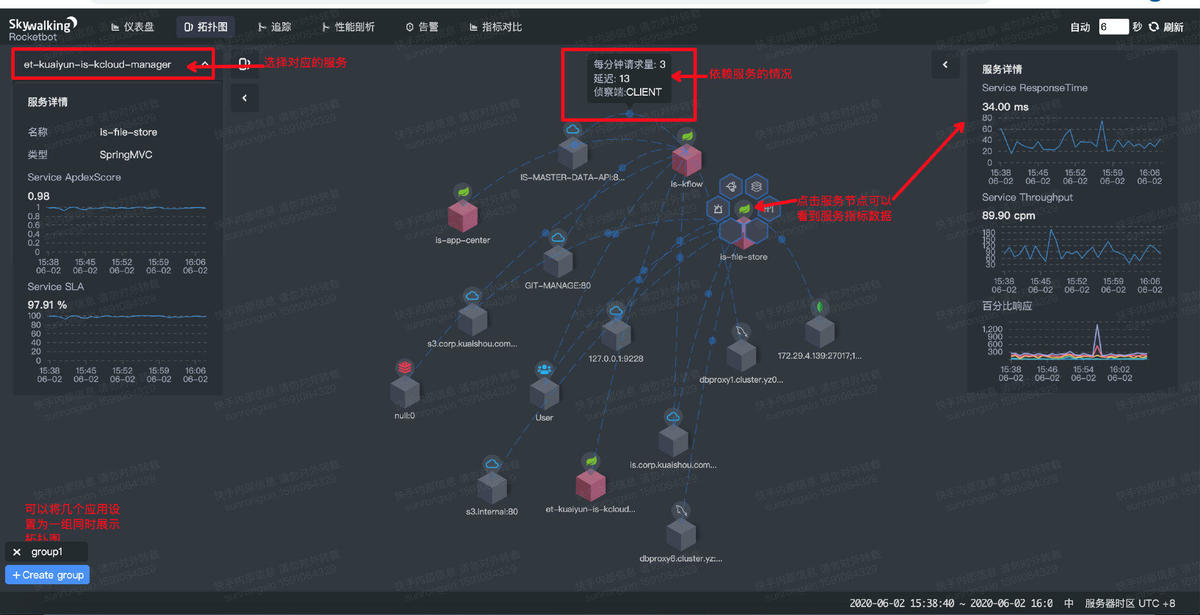
2. 拓扑结构
不同于仪表盘来展示单一服务的指标,拓扑图是来展示服务和服务之间的依赖关系。
用户可以选择单一服务查询,也可以将多个服务设定为一组同时查询。
点击服务图片会自动显示当前的服务指标;
SW会根据请求数据,自动探测出依赖的服务,DB和中间件等。
点击依赖线上的圆点,会显示服务之间的依赖情况,如每分钟吞吐量,平均延迟时间,和侦察端模式(client/Server)。
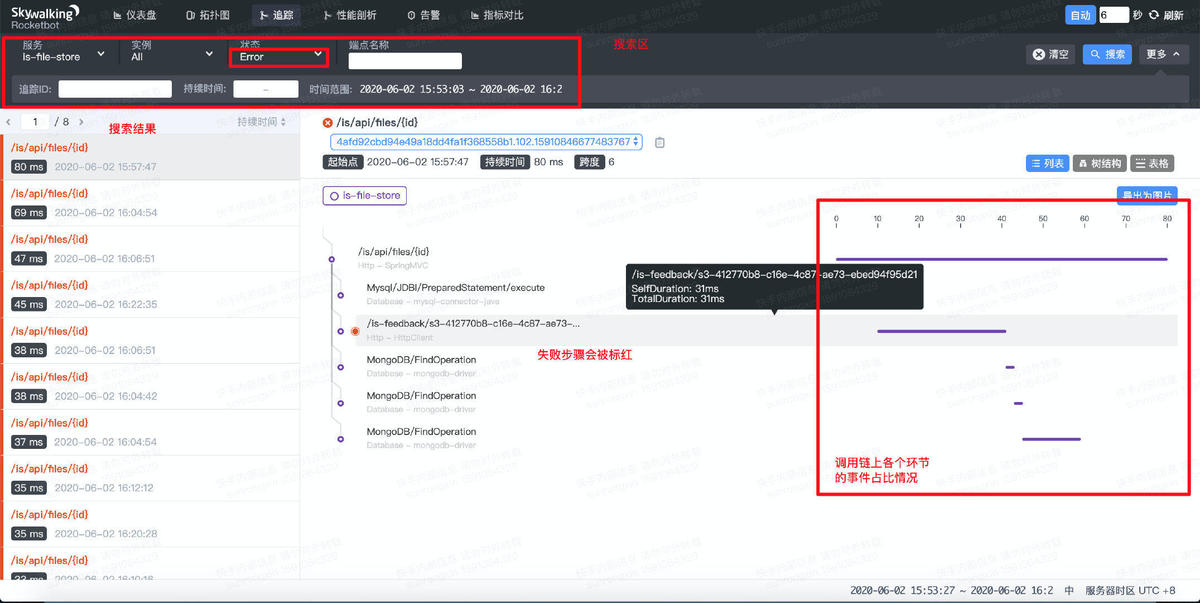
3. 请求追踪
当用户发现服务的SLA降低,或者某个具体的端口响应时间上扬明显,可以使用追踪功能查询具体的请求记录。
- 最上方为搜索区,用户可以指定搜索条件,如隶属于哪个服务、哪个实例、哪个端口,或者请求是成功还是失败;也可以根据上文提到的TraceID精确查询。
- 整个调用链上每一个跨度的耗时和执行结果都会被列出(默认是列表,也可选择树形结构和表格的形式);
- 如果有步骤失败,该步骤会标记为红色。
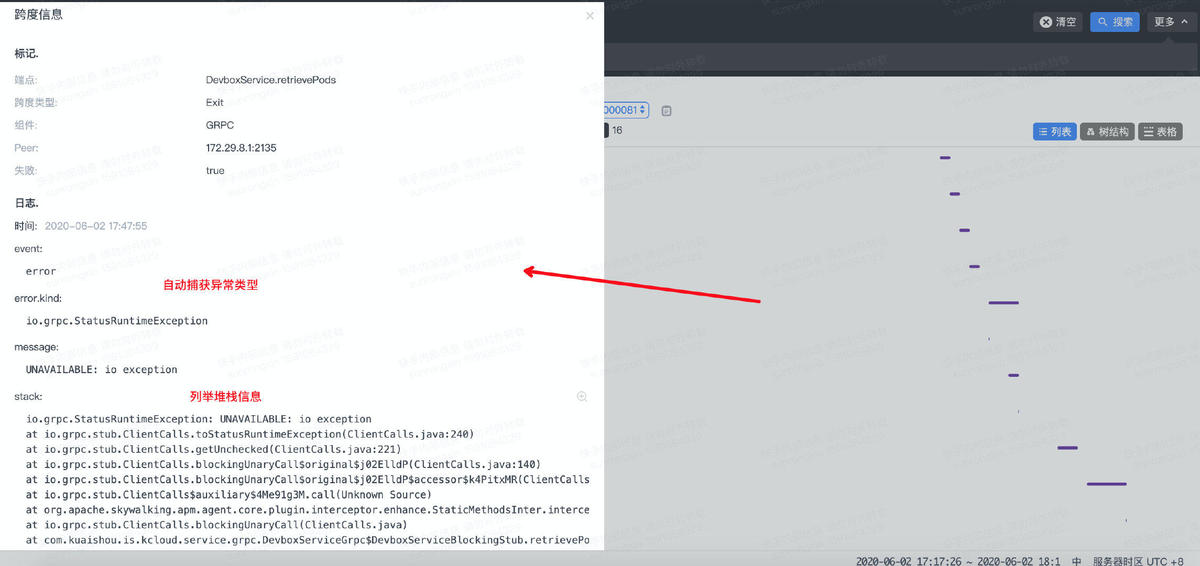
点击跨度,会显示跨度详情,如果有异常发生,异常的种类、信息和堆栈都会被自动捕获;
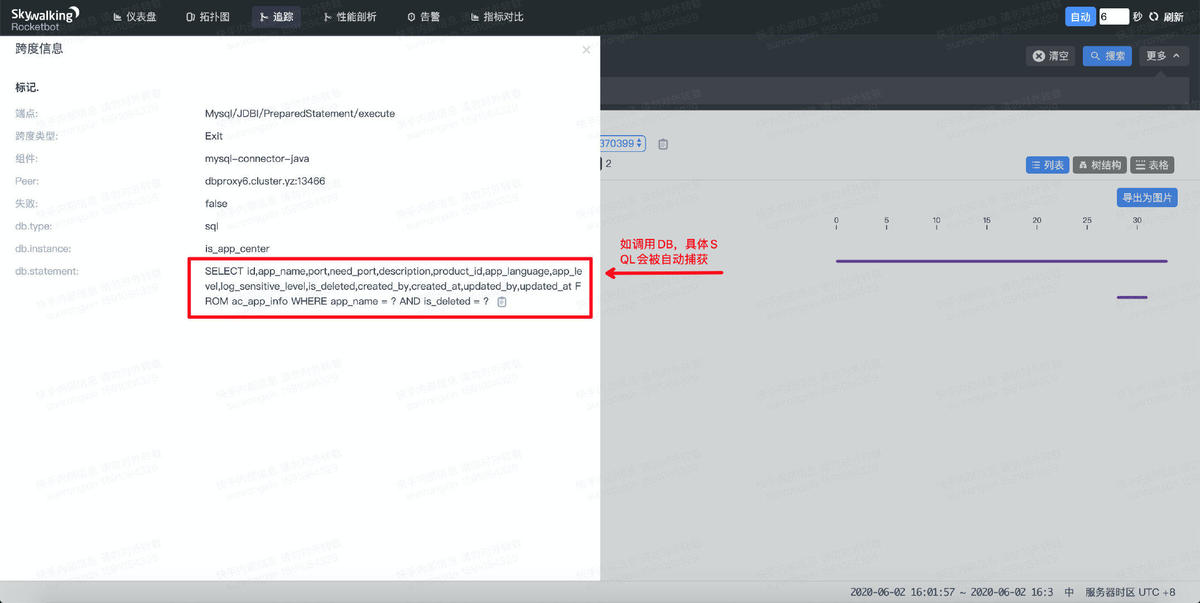
如果跨度为数据库操作,执行的SQL也会被自动记录。
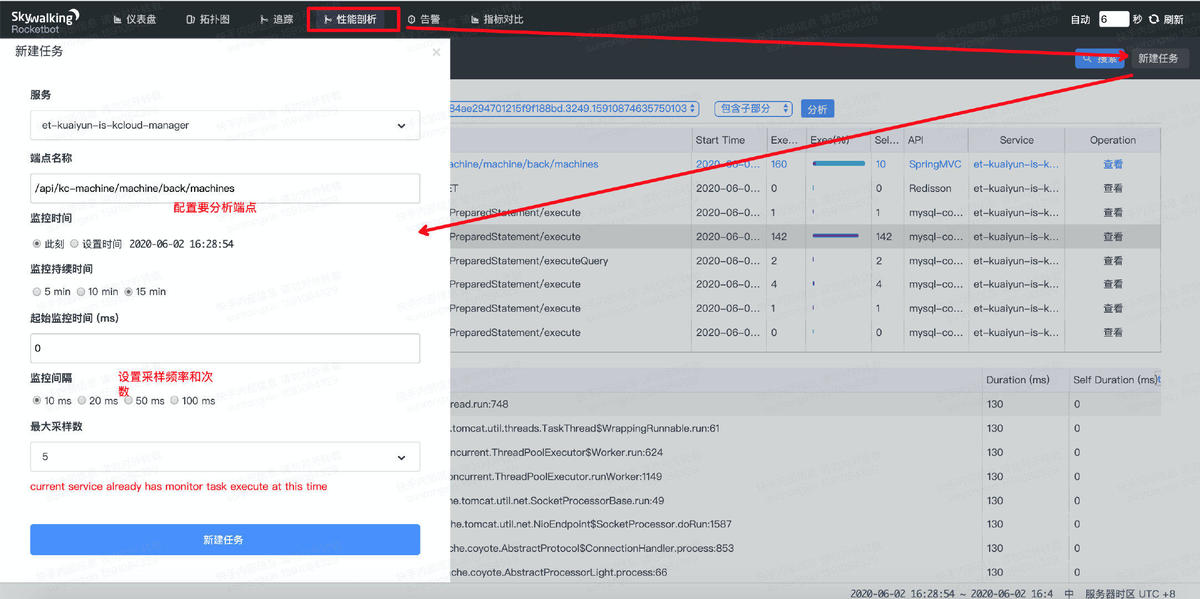
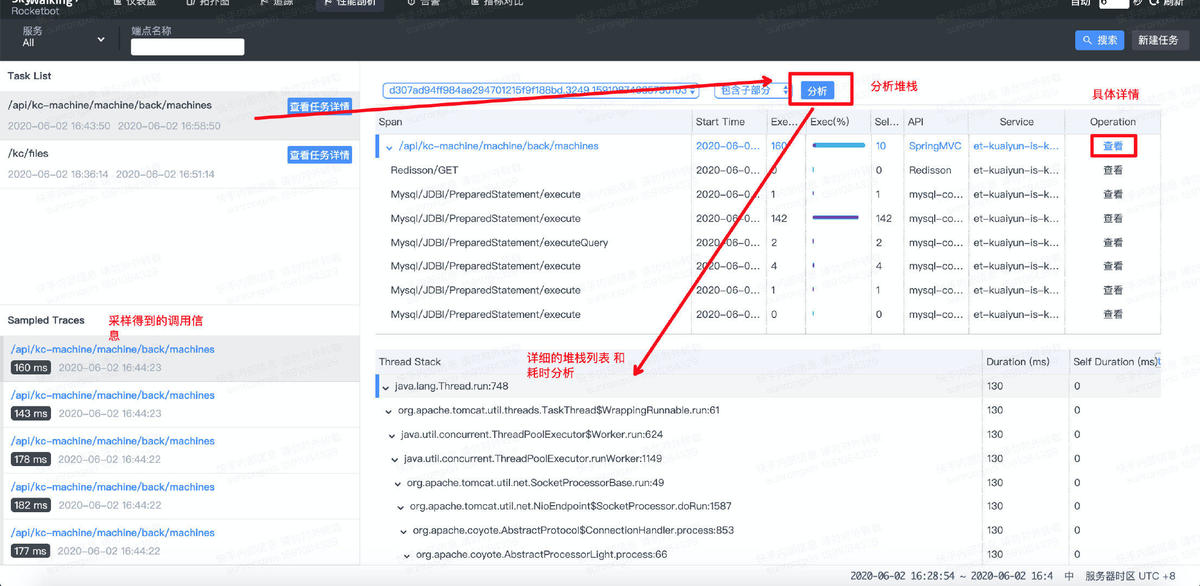
4. 性能剖析
追踪功能展示出的跨度是服务调用粒度的,如果要看应用实时的堆栈信息,可以选择性能剖析功能。
- 新建分析任务;
- 选指定的服务和端点作为分析对象;
- 设定采样频率和次数;
注意: 如果端点的响应时间小于监控间隔,可能会导致采样分析失败。
新建任务后,SW将开始采集应用的实时堆栈信息。采样结束后,用户点击分析即可查看具体的堆栈信息。
- 点击跨度右侧的“查看”,可以看到调用链的具体详情;
- 跨度目录下方是SW收集到的具体进程堆栈信息和耗时情况。
性能剖析功能因为要实时高频率收集服务的JVM堆栈信息,对于服务本身有一定的性能消耗,只适用于耗时端点的行为分析。
