1. ConcurrentHashMap结构
在JDK1.7的ConcurrentHashMap实现是由Segments数组结构和HashEntry数组结构组成.Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的色;HashEntry则用于存储键值对数据.一个ConcurrentHashMap里包含一个Segment组.Segment的结构和HashMap类似,是一种数组加链表的结构.一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护者一个HashEntry数组里面的元素,当对HashEntry数组的数据进行修改时,必须先获得与它对应的Segment锁,如下图所示.

并发:不同Segment读读,读写,写写操作可以并发进行;相同Segment的读读和读写操作互不影响,写写操作会阻塞其中一个线程,
ConcurrentHashMap的默认初始化容量DEFAULT_INITIAL_CAPACITY是16,默认的加载因子DEFAULT_LOAD_FACTOR是0.75,并发级别DEFAULT_CONCURRENCY_LEVEL默认是16,说下这个并发级别DEFAULT_CONCURRENCY_LEVEL,该变量表示预估有多少线程并发修改这个map,该变量决定了Segment数组的大小(也就是分段锁的个数),Segment数组默认大小最小是2,最大是65536。
Segment是什么呢?
首先看一段描述:Segments are specialized versions of hash tables. This subclasses from ReentrantLock opportunistically, just to simplify some locking and avoid separate construction,大概意思就是说Segments是一个特殊版的hash表,实现了ReentrantLock可重入锁,其实就是提供了分段锁的功能,这也是ConcurrentHashMap处理并发高效的原因,结合上面的图看下,因为Segment的存在降低了锁的粒度。
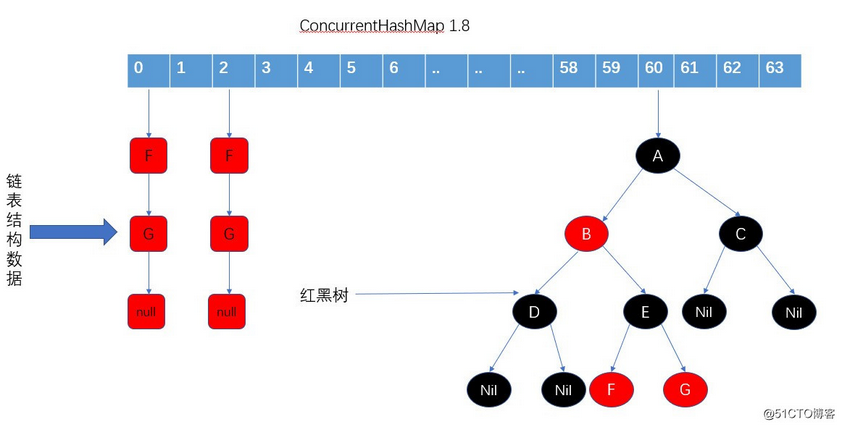
jdk1.8内部实现和1.7最大的变化就是取消了Segment分段枷锁的结构,而是用Node数组+cas+synchronized去实现,锁粒度更小。
在1.8中没有了segments这些东西了,每次锁住的数组中的一个元素或者桶(其实也就是数组或者树的头结点),然后锁也和1.7发生变了,使用的是Synchronized锁,1.8中的锁是随着数组的长度发生变化的,提升了并发的数量的灵活性,还有就是1.8的数据结构也发生了一些变化,采用的是数组+链表+红黑树(链表到达阈值会树化),结构如下图所示:
2. 基本成员
先介绍一些基本成员,只有了解了这些成员的概念后,才能去更好的去理解方法。 ConcurrentHashMap的一些成员变量
/** node数组的最大容量 2^30 */
private static final int MAXIMUM_CAPACITY = 1 << 30;
/** 默认初始化值16,必须是2的冥 */
private static final int DEFAULT_CAPACITY = 16;
/** 虚拟机限制的最大数组长度,jdk1.8新引入的,需要与toArrar()相关方法关联 */
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/** 并发数量,1.7遗留,兼容以前版本 */
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
/** 负载因子,兼容以前版本,构造方法中指定的参数是不会被用作loadFactor的,为了计算方便,统一使用 n - (n >> 2) 代替浮点乘法 *0.75 */
private static final float LOAD_FACTOR = 0.75f;
/** 链表转红黑树,阈值>=8 */
static final int TREEIFY_THRESHOLD = 8;
/** 树转链表阀值,小于等于6(tranfer时,lc、hc=0两个计数器分别++记录原bin、新binTreeNode数量,
* <=UNTREEIFY_THRESHOLD 则untreeify(lo))
*/
static final int UNTREEIFY_THRESHOLD = 6;
/** 链表转红黑树的阈值,64(map容量小于64时,链表转红黑树时先进行扩容) */
static final int MIN_TREEIFY_CAPACITY = 64;
/** 下面这三个和多线程协助扩容有关 */
/** // 扩容操作中,transfer这个步骤是允许多线程的,这个常量表示一个线程执行transfer时,最少要对连续的16个hash桶进行transfer
// (不足16就按16算,多控制下正负号就行)
private static final int MIN_TRANSFER_STRIDE = 16;
/** 生成sizeCtl所使用的bit位数 */
private static int RESIZE_STAMP_BITS = 16;
/** 参与扩容的最大线程数 */
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
/** 移位量,把生成戳移位后保存在sizeCtl中当做扩容线程计数的基数,相反方向移位后能够反解出生成
戳 */
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
/*
* Encodings for Node hash fields. See above for explanation.
*/
static final int MOVED = -1; // 表示正在转移
static final int TREEBIN = -2; // 表示已经转换为树
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
/** 可用处理器数量 */
static final int NCPU = Runtime.getRuntime().availableProcessors();
/** 用于存放node数组 */
transient volatile Node<K,V>[] table;
/**
* baseCount为并发低时,直接使用cas设置成功的值
* 并发高,cas竞争失败,把值放在counterCells数组里面的counterCell里面
* 所以map.size = baseCount + (每个counterCell里面的值累加)
*/
private transient volatile long baseCount;
/**
* 控制标识符,用来控制table的初始化和扩容的操作,不同的值有不同的含义
* 当为负数时:-1代表正在初始化,-N就代表在扩容,-N-RS-2就代表有多少个线程在协助扩容
* 当为0时:代表当时的table还没有被初始化
* 当为正数时:表示初始化或者下一次进行扩容的大小
*/
private transient volatile int sizeCtl;
/**
* 通过cas实现的锁,0 无锁,1 有锁
*/
private transient volatile int cellsBusy;
/**
* counterCells数组,具体的值在每个counterCell里面
*/
private transient volatile CounterCell[] counterCells;
https://blog.51cto.com/14220760/2395683
https://mp.weixin.qq.com/s/3FCg-9kPjSAR0tN6xLW6tw
