1. 为什么要用缓存
当一个服务刚开始的时候,架构比较简单,往往就是一个Tomcat,后面连着一个数据库。
对于一个服务其性能瓶颈往往都在MySQL。我们在创建表的时候,并不会未所有的字段创建索引,这意味着如果我们需要读取非缓存数据就要从磁盘拿数据。这个过程至少需要十几毫秒的时间。而缓存往往是基于内存的,这要比DB读数据快两个数量级。这是我们用缓存的根本原因。
- 高性能
假设用户一个请求耗时 600ms 从 MySQL查出来一个结果,但是这个结果可能接下来几个小时都不会变了,或者变了也可以不会立即反馈给用户。这时就可以将这次 600ms 查出来的结果放入缓存里,一个 key 对应一个 value,下次查找时不经过 MySQL,直接从缓存里通过key 查出来 value。
所以对于一些需要复杂操作耗时查出来的结果,确定后面不怎么变化,但是有很多读请求,直接将查询出来的结果放在缓存中,后面直接读缓存就好。
- 高并发
MySQL 数据库对于高并发来说天然支持不好,MySQL 单机支撑到 2000QPS 就开始容易报警了。如果系统高峰期一秒钟有1万个请求,那么一个 MySQL 单机绝对会宕机。这个时候就只能上缓存,把很多数据放入缓存。因为缓存就是简单的 key-value 式操作,单机支撑的并发量一秒可达几万十几万,单机承载并发量是 MySQL 单机的几十倍。
2. 哪里可以加缓存
符合什么特点的数据才需要加缓存:
- 热点数据:被高频访问,如几十次/秒以上
- 静态数据:很少变化,读远大于写,如几天变更一次
以终端用户为起点,系统的数据库为终点,数据要经过浏览器,CDN,代理服务器,应用服务器,以及数据库各个环节

上面的每个环节都可以运用缓存技术。
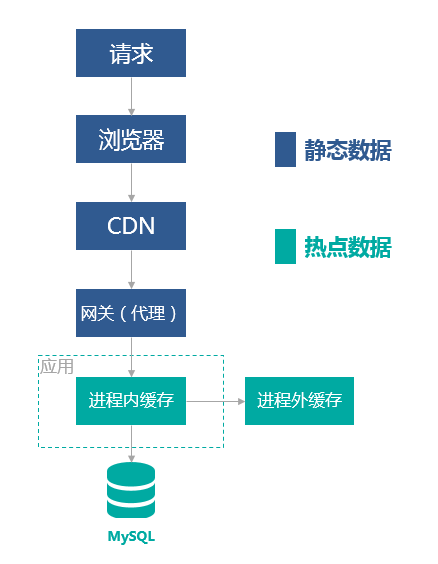
每个环节可以拦截掉一些流量,最终形成一个漏斗状的拦截效果,以此保护最后面的系统以及最终的数据库。

2.1. 浏览器缓存
当用户通过浏览器请求服务器的时候,会发起 HTTP 请求,如果对每次 HTTP 请求进行缓存,那么可以减少应用服务器的压力。
当第一次请求的时候,浏览器本地缓存库没有缓存数据,会从服务器取数据,并且放到浏览器的缓存库中,下次再进行请求的时候会根据缓存的策略来读取本地或者服务的信息。
2.2. CDN缓存
CDN的全称是Content Delivery Network,即内容分发网络。提供 CDN 服务的服务商,在全国甚至是全球部署着大量的服务器节点(可以叫做“边缘服务器”)。
那么将数据分发到这些遍布各地服务器上作为缓存,让用户访问就近的服务器上的缓存数据,就可以起到压力分摊和加速效果。如果用户在CDN上请求到数据就不用在请求应用服务器了。
但是需要注意的是,由于节点众多,更新缓存数据比较缓慢,一般至少是分钟级别,所以一般仅适用于不经常变动的静态数据。
2.3. 网关(代理)缓存
很多时候我们会在源站前面架一层网关(或者说反向代理、正向代理),为的是做一些安全机制或者作为统一分流策略的入口。我们可以把一些修改频率不高的数据缓存在这里,例如:用户信息,配置信息。通过服务定期刷新这个缓存就行了。一般我们会使用Nginx作为网关。
2.4. 进程内缓存
从这里开始对缓存的引入成本比前面 3 种大大增加,因为对缓存与数据库之间的“数据一致性”要求更高了。
进程内缓存指的是在应用中的缓存组件,其最大的优点是应用和cache是在同一个进程内部,请求缓存非常快速,没有过多的网络开销,也不需要序列化和反序列化,通常我们会把热点数据放在这里。进程内缓存放在 JVM 的堆内存上面,因此会受到垃圾算法的影响。在进程内缓存没有命中的时候,我们会去搜索进程外的缓存或者分布式缓存。
在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用进程内缓存较合适;同时,它的缺点也是缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费。
目前比较流行的实现有 Ehcache、GuavaCache、Caffeine。
如果要保证多个节点进程内缓存的一致性,可以使用MQ通知或定时拉取的方式
2.5. 进程外缓存
进程外缓存在应用运行的进程之外,它拥有更大的缓存容量,并且可以部署到不同的物理节点,通常会用分布式缓存的方式实现(Redis 、 Memcached)。
分布式缓存是与应用分离的缓存服务,最大的特点是自身是一个独立的应用,与本地应用隔离,多个应用可直接共享一个或者多个缓存应用。
2.6. 数据库缓存
数据库本身是自带缓存模块的,它是数据库的内部机制,但是比较吃内存
3. 缓存的特征
缓存也是一个数据模型对象,那么必然有它的一些特征:
- 命中率 命中率=返回正确结果数/请求缓存次数,命中率问题是缓存中的一个非常重要的问题,它是衡量缓存有效性的重要指标。缓存的命中率越高则表示使用缓存的收益越高,应用的性能越好(响应时间越短、吞吐量越高),抗并发的能力越强。
- 最大元素(或最大空间) 缓存中可以存放的最大元素的数量,一旦缓存中元素数量超过这个值(或者缓存数据所占空间超过其最大支持空间),那么将会触发缓存启动清空策略根据不同的场景合理的设置最大元素值往往可以一定程度上提高缓存的命中率,从而更有效的时候缓存。
- 清空策略 如上描述,缓存的存储空间有限制,当缓存空间被用满时,如何保证在稳定服务的同时有效提升命中率?这就由缓存清空策略来处理,设计适合自身数据特征的清空策略能有效提升命中率
3.1. 命中率
3.1.1. 业务场景
缓存适合“读多写少”的业务场景,反之,使用缓存的意义其实并不大,命中率会很低。
业务需求决定了对时效性的要求,直接影响到缓存的过期时间和更新策略。时效性要求越低,就越适合缓存。在相同key和相同请求数的情况下,缓存时间越长,命中率会越高。
3.1.2. 缓存的设计(粒度和策略)
通常情况下,缓存的粒度越小,命中率会越高。
当缓存单个对象的时候(例如:单个用户信息),只有当该对象对应的数据发生变化时,我们才需要更新缓存或者让移除缓存。而当缓存一个集合的时候(例如:所有用户数据),其中任何一个对象对应的数据发生变化时,都需要更新或移除缓存。
还有另一种情况,假设其他地方也需要获取该对象对应的数据时(比如其他地方也需要获取单个用户信息),如果缓存的是单个对象,则可以直接命中缓存,反之,则无法直接命中。这样更加灵活,缓存命中率会更高。
此外,缓存的更新/过期策略也直接影响到缓存的命中率。当数据发生变化时,直接更新缓存的值会比移除缓存(或者让缓存过期)的命中率更高,当然,系统复杂度也会更高。
3.1.3. 缓存容量
缓存的容量有限,则容易引起缓存失效和被淘汰(目前多数的缓存框架或中间件都采用了LRU算法)。
3.1.4. 命中率对性能的影响
摘自https://tech.youzan.com/cache-background/
**场景一: **
我们假定, HTTP QPS 有 10,000, 没有使用Cache(变相地假定Miss100%), RDBMS是读 3 ms/query , Cache是 1 ms/query。
那么理想下10,000个Query总耗时: 3 ms/query * 10,000query = 30,000 ms
如果我们用了以上2者结合的方式
假定是 90% 命中率, 那么理想下10,000个Query总耗时: 3 ms/query * 1,000query + 1 ms/query * 9,000query = 12,000 ms.
假定是 70% 命中率, 那么理想下10,000个Query总耗时: 3 ms/query * 3,000 query + 1 ms/query * 7,000query = 16,000 ms.
场景二:
我们假定, HTTP QPS 有 10,000, 没有使用Cache(变相地假定Miss100%), RDBMS是 读:写 是 8 : 2 . 读 3 ms/query, 写 5 ms / query, Cache是 1 ms/query.
那么理想下10,000个Query总耗时: 3 ms / query * 8,000 query + 5 ms / query * 2000 query = 34,000 ms .
如果我们用了以上2者结合的方式,
假定新数据写入后才有读的操作, 那么命中率可能为100%, 那么理想下10,000个Query总耗时: 1 ms/query * 8,000query + 5 ms/query * 2000 query = 18,000 ms.
差一些命中率可能为90%, 那么理想下10,000个Query总耗时: 1 ms/query * ( 8,000query90%) + 3 ms/query * ( 8,000query10%) + 5 ms/query * 2000 query = 19,600 ms.
再差一些命中率可能为70%, 那么理想下10,000个Query总耗时: 1 ms/query * ( 8,000query70%) + 3 ms/query * ( 8,000query30%) + 5 ms/query * 2000 query = 22,800 ms.
可以看到 22,800ms / 19,600ms = 117%, 那么有17%的性能损失.
3.2. 缓存的清空策略
- FIFO(first in first out)
先进先出策略,最先进入缓存的数据在缓存空间不够的情况下(超出最大元素限制)会被优先被清除掉,以腾出新的空间接受新的数据。这种算法主要比较缓存元素的创建时间。在数据实效性要求场景下可选择该类策略,优先保障最新数据可用。
但这个策略会导致命中率很低,如果有个访问频率很高的数据是所有数据第一个访问的,而那些不是很高的是后面再访问的,那这样就会把我们的首个数据但是他的访问频率很高给挤出。
- LFU(less frequently used)
最近最少频率使用策略,无论是否过期,根据元素的被使用次数判断,清除使用次数较少的元素释放空间。这种算法主要比较元素的hitCount(命中次数)。在保证高频数据有效性场景下,可选择这类策略。
- LRU(least recently used)
最近最少使用策略,无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。这种算法主要比较元素最近一次被get使用时间。在热点数据场景下较适用,优先保证热点数据的有效性。
但是这个依然有个问题,如果有个数据在1个小时的前59分钟访问了1万次(可见这是个热点数据),再后一分钟没有访问这个数据,但是有其他的数据访问,就导致了我们这个热点数据被淘汰。
LRU和LFU的区别。LFU算法是根据在一段时间里数据项被使用的次数选择出最少使用的数据项,即根据使用次数的差异来决定。而LRU是根据使用时间的差异来决定的。
4. 使用缓存
缓存的操作流程一般是这样的:

- 读取缓存中是否有相关数据
- 如果缓存中有相关数据,直接返回(缓存命中“hit”)
- 如果缓存中没有相关数据,则从数据库读取相关数据(缓存未命中“miss”),再将数据放入缓存,然后返回。
伪代码:
Object value = cache.get(key);
if (value != null) {
return value;
}
value = db.get(key);
if (value != null) {
cache.put(key, value)
}
return value;
缓存的命中率 = 命中缓存请求个数/总缓存访问请求个数 = hit/(hit+miss)
对于一般的应用的话db的读写频率的比例大约在10:1左右,读的次数明显大于写的次数,大多数请求到了缓存这里就给搞定了,只有少量的穿透来维护数据的更新.这种做法是明智的,服务器读内存的速度比读硬盘的速度快 10^5-10^6倍,使用缓存可以大大增加用户的响应速度和服务器的处理能力。
然而上述的代码却存在一些比较公共的缓存问题
- 缓存雪崩
- 缓存穿透
- 缓存并发
5. 缓存的不足
通过了解上面的内容,你不难发现,缓存的主要作用是提升访问速度,从而能够抗住更高的并发。那么,缓存是不是能够解决一切问题?显然不是。事物都是具有两面性的,缓存也不例外,我们要了解它的优势的同时也需要了解它有哪些不足,从而扬长避短,将它的作用发挥到最大。
首先,缓存比较适合于读多写少的业务场景,并且数据最好带有一定的热点属性。这是因为缓存毕竟会受限于存储介质不可能缓存所有数据,那么当数据有热点属性的时候才能保证一定的缓存命中率。比如说类似微博、朋友圈这种 20% 的内容会占到 80% 的流量。所以,一旦当业务场景读少写多时或者没有明显热点时,比如在搜索的场景下,每个人搜索的词都会不同,没有明显的热点,那么这时缓存的作用就不明显了。
其次,缓存会给整体系统带来复杂度,并且会有数据不一致的风险。当更新数据库成功,更新缓存失败的场景下,缓存中就会存在脏数据。对于这种场景,我们可以考虑使用较短的过期时间或者手动清理的方式来解决。
再次,之前提到缓存通常使用内存作为存储介质,但是内存并不是无限的。因此,我们在使用缓存的时候要做数据存储量级的评估,对于可预见的需要消耗极大存储成本的数据,要慎用缓存方案。同时,缓存一定要设置过期时间,这样可以保证缓存中的会是热点数据。
最后,缓存会给运维也带来一定的成本,运维需要对缓存组件有一定的了解,在排查问题的时候也多了一个组件需要考虑在内。
虽然有这么多的不足,但是缓存对于性能的提升是毋庸置疑的,我们在做架构设计的时候也需要把它考虑在内,只是在做具体方案的时候需要对缓存的设计有更细致的思考,才能最大化地发挥缓存的优势。
6. 参考资料
http://www.pianshen.com/article/4878312465/
https://tech.meituan.com/2017/03/17/cache-about.html
https://community.qingcloud.com/topic/463
https://mp.weixin.qq.com/s/JCFx-GNjueLLOEjWMKbLRQ
https://mp.weixin.qq.com/s/PXj1vPeWmle0k6KhgUhHgg
https://mp.weixin.qq.com/s/FxOQ4HrjaFn0lDis0zei-g
https://tech.youzan.com/cache-background/
《高并发系统设计40问》
