进程内缓存指的是在应用中的缓存组件,其最大的优点是应用和cache是在同一个进程内部,请求缓存非常快速,没有过多的网络开销,也不需要序列化和反序列化,通常我们会把热点数据放在这里。进程内缓存放在 JVM 的堆内存上面,因此会受到垃圾算法的影响。在进程内缓存没有命中的时候,我们会去搜索进程外的缓存或者分布式缓存。
在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用进程内缓存较合适;同时,它的缺点也是缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费。
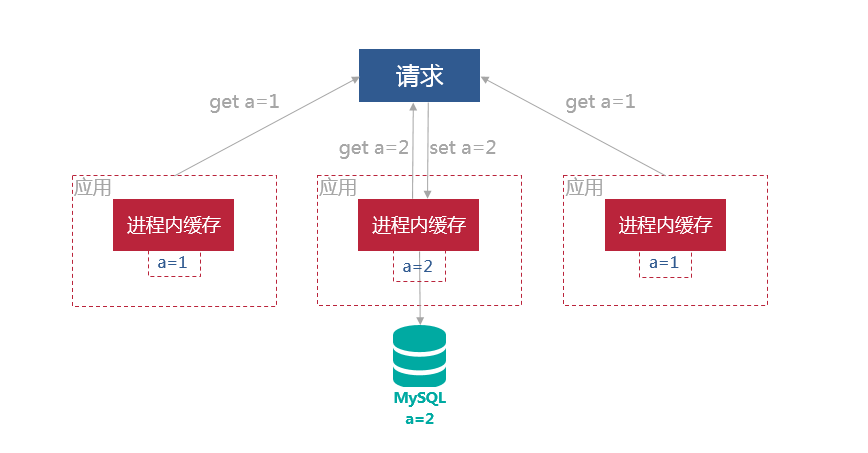
为了解决一致性问题,通常有两个方案
- 消息队列修改方案
- Timer修改方案
1. 消息队列修改
应用在修改完自身缓存数据和数据库数据之后,给消息队列发送数据变化通知,其他应用订阅了消息通知,在收到通知的时候修改缓存数据。

这个方案引入了MQ,使系统变得更加复杂
2. Timer修改方案
为了避免耦合,降低复杂性,对“实时一致性”不敏感的情况下。每个应用都会启动一个 Timer,定时从数据库拉取最新的数据,更新缓存。
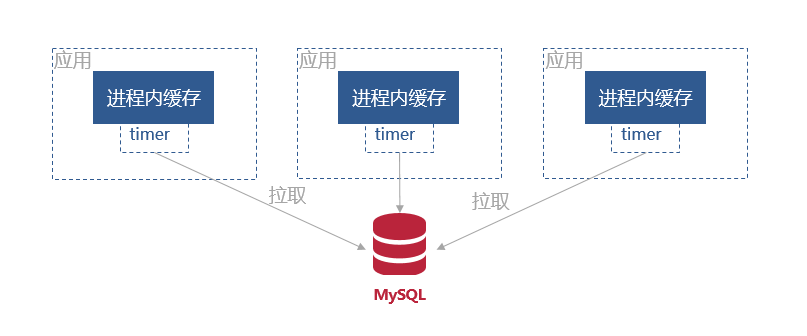
在有的应用更新数据库后,其他节点通过 Timer 获取数据之间,会读到脏数据。这里需要控制好 Timer 的频率,以及应用与对实时性要求不高的场景。
3. 适用场景
- 只读数据,不经常变更的数据(比如一天甚至好几天更新一次的那种),可以考虑在进程启动时加载到内存
- 极其高并发的,如果透传后端压力极大的场景,如秒杀
- 一定程度上允许数据不一致业务,如有一些计数场景(浏览量,评论数),运营场景,页面对数据一致性要求较低
- 极端的热点数据查询,用于阻挡热点查询对于分布式缓存节点或者数据库的压力。比如某一位明星在微博上有了热点话题,“吃瓜群众”会到他 (她) 的微博首页围观,这就会引发这个用户信息的热点查询。这些查询通常会命中某一个缓存节点或者某一个数据库分区,短时间内会形成极高的热点查询。
4. 缓存污染
我们在使用本地缓存的时候容易出现缓存污染:在本地缓存中如果你获得了数据,但是你接下来修改了这个数据,但是这个数据并没有更新在数据库,其他线程读取出来的就是错误的数据,这样就造成了缓存污染。所以在使用本地缓存的时候要注意这个问题。
