常用的缓存模式有下面几种:
- Cache Aside
- Read Through
- Write Through
- Write Behind Caching
1. Cache Aside
这种模式下应用程序负责对数据库的读写,而缓存不与数据库交互。应用程序在读取数据库中的任何数据之前先检查缓存。同时,应用程序在对数据库进行任何更新后需要更新缓存。通过上述的操作应用程序确保缓存与数据库保持同步。


当数据发生变化的时候,对缓存的失效有两种处理策略:
- 更新缓存:数据不但写入数据库,还会写入缓存,缓存不会增加一次miss,命中率高,但处理复杂
- 淘汰缓存:数据只会写入数据库,不会写入缓存,只会把数据淘汰掉,增加了一次cache miss,但处理简单
这两种策略同时又有两种处理方式:
- 先写数据库,再操作缓存
- 先操作缓存,再写数据库
Cache Aside模式建议先写数据库,再淘汰缓存。为什么?
我们先假设写数据库和操作缓存都会成功。在两个线程并发写入的时候分别看更新缓存的两种场景
先更新缓存,再写数据库
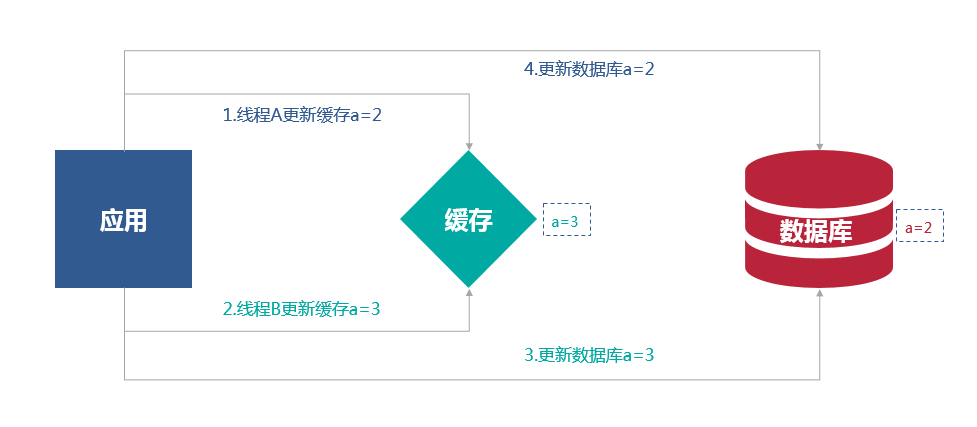
先写数据库,在更新缓存

对于更新缓存,在线程A和线程B两个并发写发生时,由于无法保证时序,此时不管先操作缓存还是先操作数据库,都会导致缓存和数据库的数据不一致。
在两个线程并发读写的时候分别看淘汰缓存的两种场景
先淘汰缓存,再写数据库
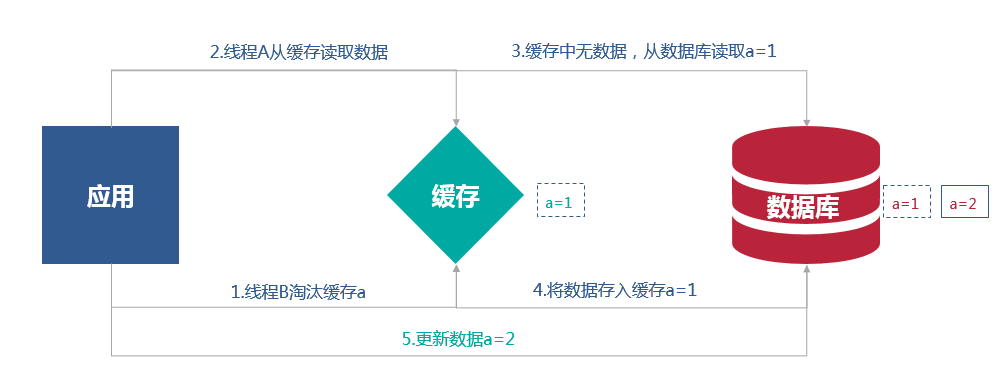
先写数据库,再淘汰缓存
从上面的分析可以得出,先写数据库,再淘汰缓存会导致一次cache miss,其他三种情况都容易出现数据不一致的情况,所以Cache Aside模式建议先写数据库,再淘汰缓存
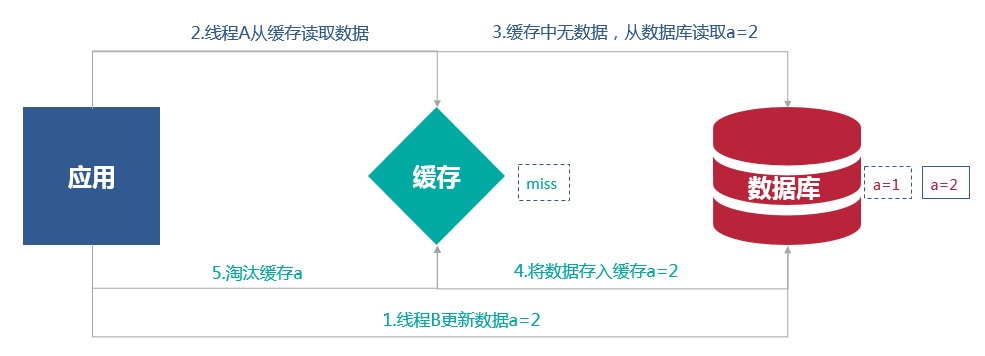
然而这并非说这种模式的缓存处理就一定能做到完美。比如下面的场景
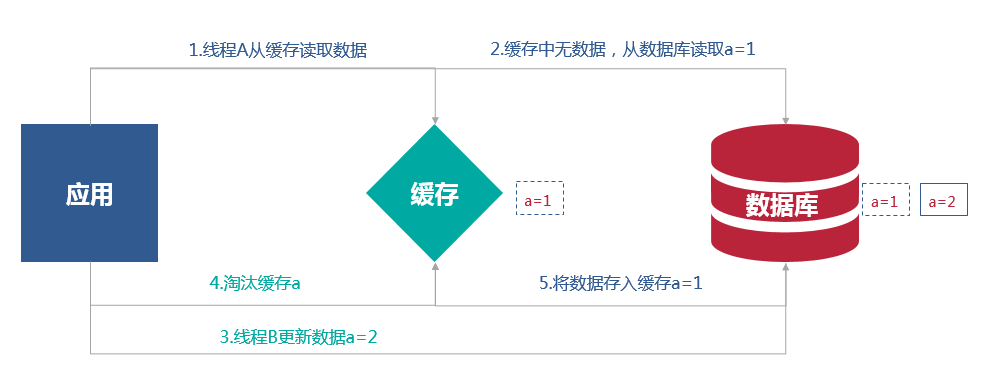
一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,这时缓存和数据库中的数据就不一致。
不过,上述问题实际上出现的概率可能非常低,因为这种情况触发的条件比较苛刻
- 需要在读缓存时缓存失效,而且同时并发着有一个写操作
- 查询操作需要在更新操作先到达数据库
- 查询操作的回填比更新操作的删除后触发
而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存。所以第三条出现的概率较低
为了保证数据一致性,只能通过2PC或者Paxos协议来保证一致性,这会极大增加复杂度。所以我们一般会采取尽量降低并发时脏数据的概率 我们也可以将同一个数据的更新、读取操作放到一个队列中排队处理,但这样会带来更大的复杂度,而且降低了系统吞吐量。
另外更新缓存的代价有时候是很高的。如果一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低,用到缓存才去算缓存。
Cache Aside 策略是我们日常开发中最经常使用的缓存策略,不过我们在使用时也要学会依情况而变。比如说当新注册一个用户,按照这个更新策略,你要写数据库,然后清理缓存(当然缓存中没有数据给你清理)。可当我注册用户后立即读取用户信息,并且数据库主从分离时,会出现因为主从延迟所以读不到用户信息的情况。而解决这个问题的办法恰恰是在插入新数据到数据库之后写入缓存,这样后续的读请求就会从缓存中读到数据了。并且因为是新注册的用户,所以不会出现并发更新用户信息的情况。
Cache Aside 存在的最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。如果你的业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
- 一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
- 另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快过期,对业务的影响也是可以接受
2. Read-Through
Read-Through模式是指应用程序始终从缓存中请求数据。如果缓存没有数据,则它负责使用底层提供程序插件从数据库中检索数据。检索数据后,缓存会自行更新并将数据返回给调用应用程序。
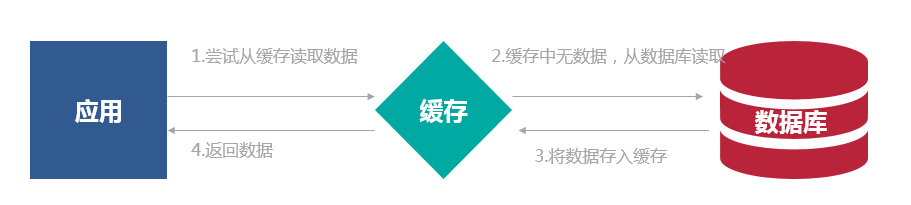
Read-though模式下应用总是使用key从缓存中请求数据, 调用的应用程序不知道数据库, 由存储方来负责自己的缓存处理,这使代码更具可读性, 代码更清晰。
3. Write-Through
Write Through模式和Read Through模式类似,当数据发生更新的时候,首先将数据写入缓存,然后写入数据库。缓存与数据库保持一致,写操作总是通过缓存到达主数据库。如果缓存和数据库都被更新成功,则认为写入操作成功(同步操作)。如果缓存写入成功,数据库写入失败,需要考虑回退的问题。
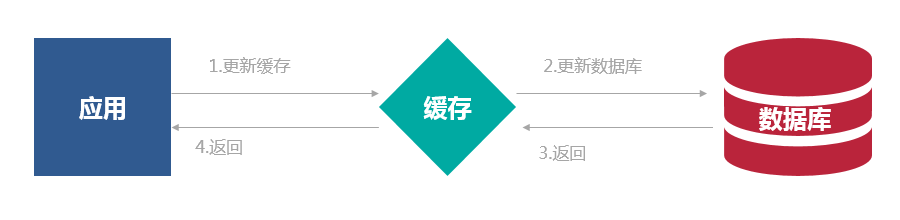
Write Through 的策略是这样的:先查询要写入的数据在缓存中是否已经存在,如果已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,如果缓存中数据不存在,我们把这种情况叫做“Write Miss(写失效)”。一般来说,我们可以选择两种“Write Miss”方式:
-
一个是“Write Allocate(按写分配)”,做法是写入缓存相应位置,再由缓存组件同步更新到数据库中;
-
另一个是“No-write allocate(不按写分配)”,做法是不写入缓存中,而是直接更新到数据库中。
在 Write Through 策略中,我们一般选择“No-write allocate”方式,原因是无论采用哪种“Write Miss”方式,我们都需要同步将数据更新到数据库中,而“No-write allocate”方式相比“Write Allocate”还减少了一次缓存的写入,能够提升写入的性能。
我们看到 Write Through 策略中写数据库是同步的,这对于性能来说会有比较大的影响,因为相比于写缓存,同步写数据库的延迟就要高很多了。
4. Write-Behind-Caching
在Write Through模式下面我们也可以将数据库更新改为延迟更新:只要数据被写入缓存,就认为是成功的,然后再通过异步方式更新数据库。

在“Write Miss”的情况下,我们采用的是“Write Allocate”的方式,也就是在写入后端存储的同时要写入缓存,这样我们在之后的写请求中都只需要更新缓存即可,而无需更新后端存储了。
这个模式的好处就是让数据的I/O操作飞快无比,但是数据不是强一致性的,可能会丢失。
当然,你依然可以在一些场景下使用这个策略:在向低速设备写入数据的时候,可以在内存里先暂存一段时间的数据,甚至做一些统计汇总,然后定时地刷新到低速设备上。
比如说,你在统计你的接口响应时间的时候,需要将每次请求的响应时间打印到日志中,然后监控系统收集日志后再做统计。但是如果每次请求都打印日志无疑会增加磁盘 I/O,那么不如把一段时间的响应时间暂存起来,经过简单的统计平均耗时,每个耗时区间的请求数量等等,然后定时地,批量地打印到日志中。
5. 更深入一步
我们在上面对Cache Aside的一致性分析都是基于写数据库和操作缓存都成功的情况下,然而写数据库与操作缓存不能保证原子性,两个操作的操作时序不同页会导致数据不一致的情况发生。
先更新缓存,再写数据库:第一步更新缓存成功,第二步写数据库失败,会出现数据库中是旧数据,缓存中是新数据,数据不一致。
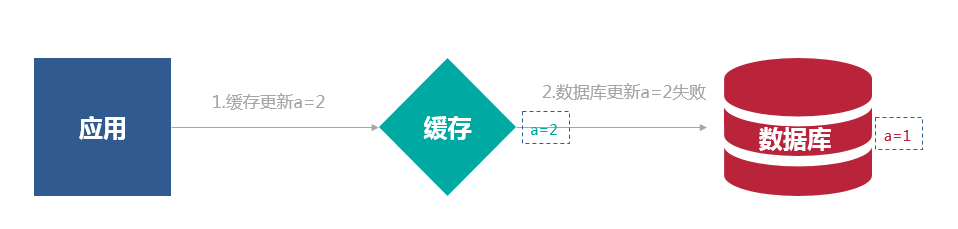
先写数据库,再更新缓存:第一步写数据库操作成功,第二步更新缓存失败,则会出现数据库中是新数据,缓存中是旧数据,数据不一致。

先淘汰缓存,再写数据库:第一步淘汰缓存成功,第二步写数据库失败,则只会引发一次Cache miss。
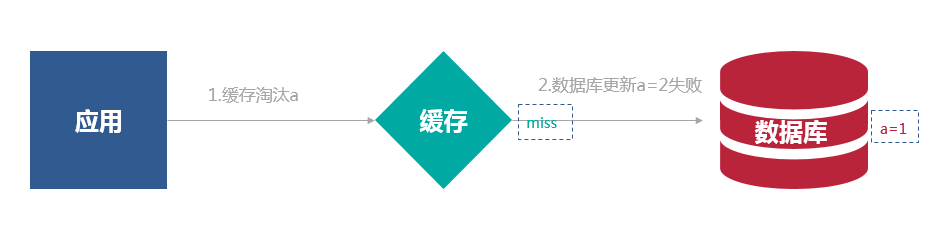
先写数据库,再淘汰缓存:第一步写数据库操作成功,第二步淘汰缓存失败,则会出现数据库中是新数据,缓存中是旧数据,数据不一致。
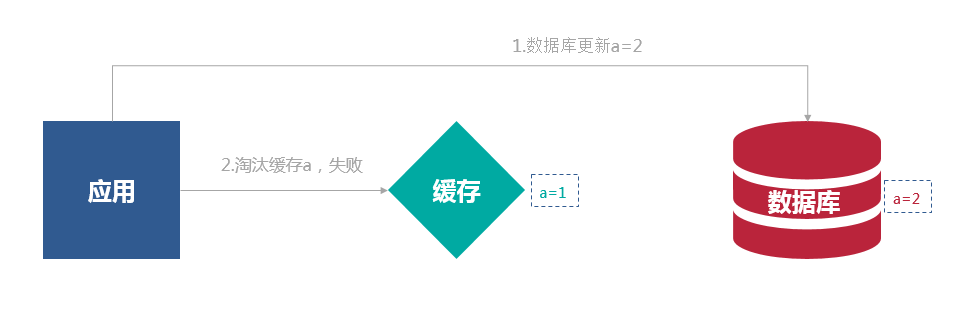
根据上面的分析,因为数据库与操作缓存不能保证原子性,先写数据库,再淘汰缓存依然无法保证数据的一致性,为了弥补这个缺陷我们可以采用重试机制
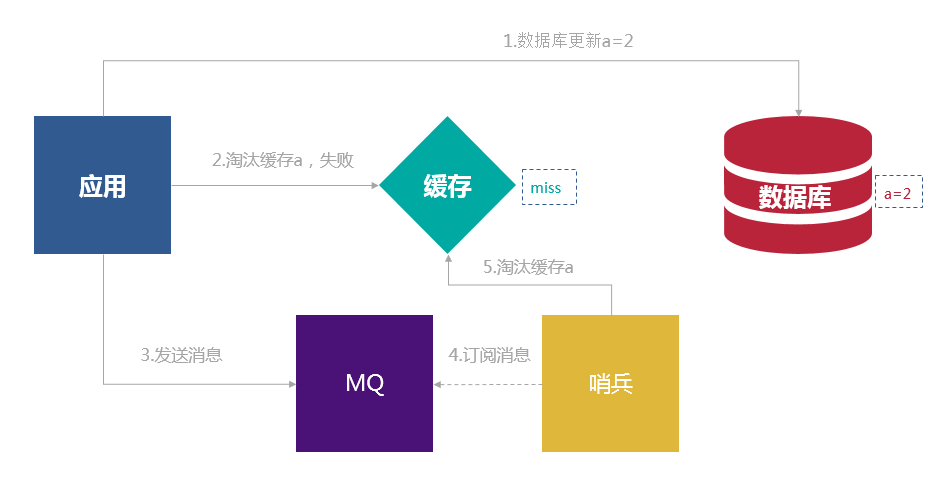
在淘汰缓存失败后,将失败的key发送到消息队列,然后由一个哨兵(也可以是自己)订阅这个消息,然后再次去淘汰缓存。
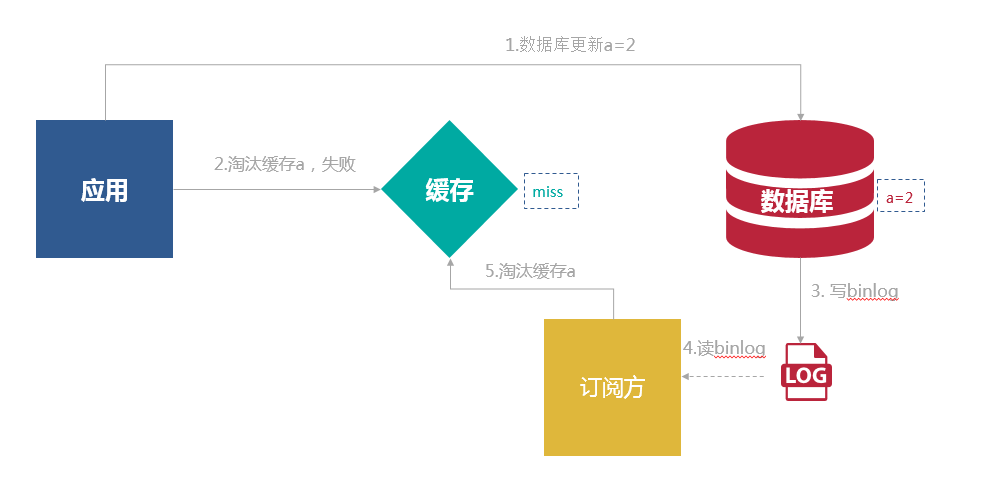
该方案有一个缺点,对业务线代码造成大量的侵入。我们可以通过订阅MySQL的binlog的日志来解耦
6. 参考资料
http://coolshell.cn/articles/17416.html
https://mp.weixin.qq.com/s/7IgtwzGC0i7Qh9iTk99Bww
https://mp.weixin.qq.com/s/pYVdCqoKauw4K2LgBnXFpw
https://mp.weixin.qq.com/s/CuwTRC8HrMHxWZe3_OX98g
《高并发系统设计40问》
