对于缓存来说命中率是它的生命线。在低缓存命中率的系统中,大量查询商品信息的请求会穿透缓存到数据库,因为数据库对于并发的承受能力是比较脆弱的。一旦数据库承受不了用户大量刷新商品页面、定向搜索衣服信息,查询就会变慢,大量的请求也会阻塞在数据库查询上,造成应用服务器的连接和线程资源被占满,最终导致你的电商系统崩溃。
一般来说,我们的核心缓存的命中率要保持在 99% 以上,非核心缓存的命中率也要尽量保证在 90%,如果低于这个标准你可能就需要优化缓存的使用方式了。
下面我们来看一下缓存面临的一些问题
1. 缓存并发
一个缓存如果失效,可能出现多个进程同时查询DB,同时设置缓存的情况,如果并发确实很大,这也可能造成DB压力过大,还有缓存频繁更新的问题。
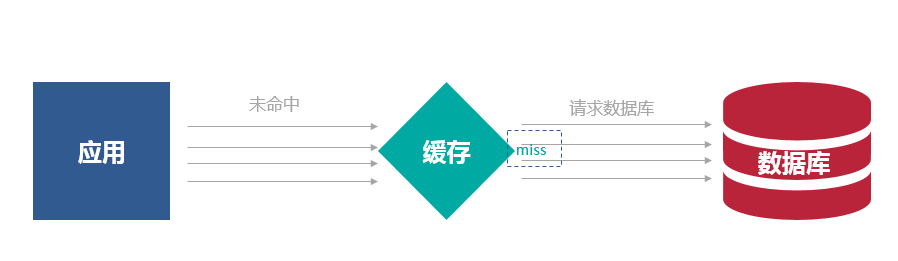
解决思路:
对缓存查询加锁,如果KEY不存在,就加锁,然后查DB入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入DB查询。但这样会降低系统的吞吐量,需要根据实际情况考虑是否这么做。
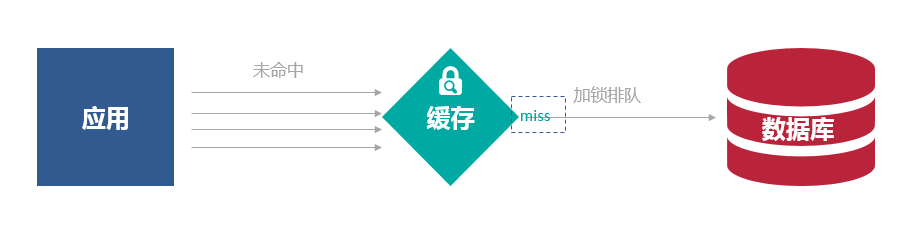
因为字符串也是共享的,我们直接锁缓存key,会阻塞其他使用这个字符串的操作行为,所以我们要加锁的字符串要是一个基于KEY生成的特殊对象.
Object value = cache.get(key);
if (value != null) {
return value;
}
String lockKey = key + "1190000005886009";
synchronized (lockKey) {
value = cache.get(key);
if (value != null) {
return value;
}
value = db.get(key);
if (value != null) {
cache.put(key, value)
}
return value;
}
在获取到锁之后,我们需要再次从缓存中读取数据,如果有相关数据之间返回
除了加锁外,我们还可以通过全局map为每个key存放一个计数器,如果计数器大于0,说明有线程正在查询。
2. 缓存穿透
缓存穿透是指用户查询的数据在数据库一定没有,自然在缓存中也不会有。这样就导致用户查询的时候,每次都要去数据库中查询。在流量大时,可能数据库就挂掉了。

在主从架构,读写分离中,如果写到主库却未同步到从库,就会出现请求穿透到数据库的情况。
少量的缓存穿透不可避免,对系统也是没有损害的,主要有几点原因:
- 一方面,互联网系统通常会面临极大数据量的考验,而缓存系统在容量上是有限的,不可能存储系统所有的数据,那么在查询未缓存数据的时候就会发生缓存穿透。
- 另一方面,互联网系统的数据访问模型一般会遵从“80/20 原则”。简单来说,它是指在一组事物中,最重要的部分通常只占 20%,而其他的 80% 并没有那么重要。把它应用到数据访问的领域,就是我们会经常访问 20% 的热点数据,而另外的 80% 的数据则不会被经常访问。
既然缓存的容量有限,并且大部分的访问只会请求 20% 的热点数据,那么理论上说,我们只需要在有限的缓存空间里存储 20% 的热点数据就可以有效地保护脆弱的后端系统了,也就可以放弃缓存另外 80% 的非热点数据了。所以这种少量的缓存穿透是不可避免的,但是对系统是没有损害的。那么什么样的缓存穿透对系统有害呢?
答案是大量的穿透请求超过了后端系统的承受范围造成了后端系统的崩溃。如果把少量的请求比作毛毛细雨,那么一旦变成倾盆大雨,引发洪水,冲倒房屋,肯定就不行了。
解决思路:
1. 存放空值
如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。

比如我们这个不存在的key预先设定一个特定值NullValue。在缓存返回这个NullValue值的时候,我们的应用就可以认为这是不存在的key,那调用方就可以决定是等待一段事件后重试,还是直接返回不存在。
当然在该KEY对应的数据被插入之后,应该清理缓存,或者将不存在KEY的缓存时间稍微设置短一点。
Object value = cache.get(key);
if (value != null) {
return value;
}
String lockKey = key + "1190000005886009";
synchronized (lockKey) {
value = cache.get(key);
if (value != null) {
return value;
}
value = db.get(key);
if (value == null) {
value = "NOT_EXISTS"
}
cache.put(key, value)
return value;
}
2.布隆过滤器
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的BitSet中,不存在的数据将会被拦截掉,从而避免了对底层存储系统的查询压力。关于布隆过滤器可以在网上搜索相关介绍,它的原理就是利用多个HASH算法将一个对象映射成一个bit数组(也称为bitmap)里面的多个点。以后判断就只要HASH后和数组里面的值亦或下就好了,效率很高。

BloomFilter的介绍https://edgar615.github.io/bloom-filter.html
针对于一些恶意攻击,攻击带过来的大量key 是不存在的,那么我们采用第一种方案就会缓存大量不存在key的数据,过多的占用缓存空间。此时我们采用第一种方案就不合适了,我们完全可以先对使用第二种方案进行过滤掉这些key。
针对这种key异常多、请求重复率比较低的数据,我们就没有必要进行缓存,使用第二种方案直接过滤掉。而对于空数据的key有限的,重复率比较高的,我们则可以采用第一种方式进行缓存。
存放空值和布隆过滤器是解决缓存穿透问题的两种最主要的解决方案,但是它们也有各自的适用场景,并不能解决所有问题。比方说当有一个极热点的缓存项,它一旦失效会有大量请求穿透到数据库,这会对数据库造成瞬时极大的压力。
3. 缓存雪崩
缓存雪崩是由于在缓存失效(缓存服务器重启或者大量缓存集中在某一个时间段失效),新缓存还未到的中间时间内,所有请求都会去查询数据库,而对数据库造成巨大压力甚至宕机。上面提到的缓存并发,缓存穿透都可能会导致缓存雪崩现象发生。
解决思路:
- 在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。这种办法虽然能缓解数据库的压力,但是同时又降低了系统的吞吐量。和缓存并发是同一种处理方式。
- 不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。避免缓存雪崩的出现。
- 二级缓存,A1为原始缓存,A2为拷贝缓存,A1缓存失效时间设置为短期,A2设置为长期,当A1失效的时候,利用同步(或者其他手段)让一个线程去查询并更新缓存,其他线程直接返回A2的数据。
- 使用分布式缓存。设计合理的缓存分布算法,让缓存均匀地分布到各个节点,这样一台缓存服务器挂了只是有部分缓存丢失,不会所有压力集中到数据库
上面的思路是从缓存的角度考虑,也可以从设计方面考虑
- 熔断机制:某个缓存节点不能工作的时候,需要通知缓存代理不要把请求路由到该节点,减少用户等待和请求时长。
- 限流机制:在接入层和代理层可以做限流,当缓存服务无法支持高并发的时候,前端可以把无法响应的请求放入到队列或者丢弃。
- 隔离机制:缓存无法提供服务或者正在预热重建的时候,把该请求放入队列中,这样该请求因为被隔离就不会被路由到其他的缓存节点。如此就不会因为这个节点的问题影响到其他节点。当缓存重建以后,再从队列中取出请求依次处理。
加锁排队的优化
加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的,同样会导致用户等待超时。对于这个问题对应的解决思路是:
给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
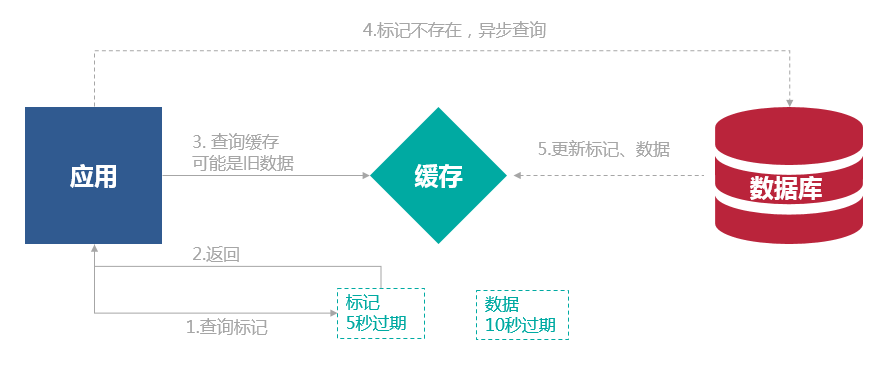
- 缓存标记:记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际key的缓存。
- 缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。 这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。
Object value = cache.get(key);
//获取标记值
String cacheSign = key + "_Sign";
Object sign = cache.get(cacheSign)
if (sign == null) {
//过期,用一个线程在后台更新缓存
new Runnable() {
Object v = db.get(key);
cache.put(key, v, cacheTime * 2);
cache.put(cacheSign, cacheSign, cacheTime);
}.start()
}
return value;//会出现脏数据
