本文基本复制的沈大在架构师之路的文章
https://mp.weixin.qq.com/s/d65cXGXp_jcEeELyDZxGVA
1. 业务场景
虚拟一个类似于“安居客”租房买房的业务场景,这个业务的数据有两大来源:
- 用户发布的数据
- 爬虫从竞对抓取来的数据
这个业务对应的系统有两类使用者:
- 普通用户,浏览与发布数据,俗称“前台用户”
- 后台用户,运营与管理数据,俗称“后台用户”
在一个创业公司,为了快速迭代,系统架构如下:
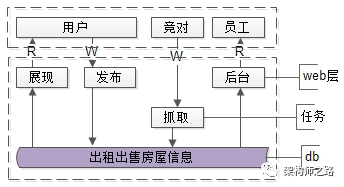
- web层:前台web,后台web
- 任务层:抓取数据
- 数据层:存储数据
2. 数据耦合的问题
系统两类数据源,一类是用户发布的数据,一类是爬虫抓取的数据,两类数据的特点不一样:
- 自有数据相对结构化,变化少
- 抓取数据源很多,数据结构变化快
如果将自有数据和抓取数据耦合在一个库里,经常出现的情况是:
- -> 抓取数据结构变化
- -> 需要修改数据结构
- -> 影响前台用户展现
- -> 经常被动修改前台用户展现逻辑,配合抓取升级
如果经历过这个过程,其中的痛不欲生,是谁都不愿意再次回忆起的。
优化思路:前台展现数据,后台抓取数据分离,解耦。
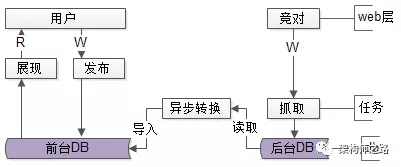
如上图所示:
- 前台展现的稳定数据,库独立
- 后台抓取的多变数据,库独立
- 任务层新增一个异步转换的任务
如此这般:
- 频繁变化的抓取程序,以及抓取的异构数据存储,解耦
- 前台数据与web都不需要被动配合升级
- 即使出现问题,前台用户的发布与展现都不影响
3. 系统耦合的问题
上面解决了不同数据源写入的耦合问题,再来看看前台与后台用户访问的耦合问题。
用户侧,前台访问的特点是:
- 访问模式有限
- 访问量较大,DAU不达到百万都不好意思说是互联网C端产品
- 对访问时延敏感,用户如果访问慢,立马就流失了
- 对服务可用性要求高,系统经常用不了,用户还会再来么
- 对数据一致性的要求高,关乎用户体验的事情就是大事
运营侧,后台访问的特点是:
- 访问模式多种多样,运营销售各种奇形怪状的,大批量分页的,查询需求
- 用户量小,访问量小
- 访问延时不这么敏感,大批量分页,几十秒能出结果,也能接受
- 对可用性能容忍,系统挂了,10分钟之内重启能回复,也能接受
- 对一致性的要求始终,晚个30秒的数据,也能接受

前台和后台的模式与访问需求都不一样,但是,如果前台与后台混用同一套服务和结构化数据,会导致:
- 后台的低性能访问,对前台用户产生巨大的影响,本质还是耦合
- 随着数据量变大,为了保证前台用户的时延,质量,做一些类似与分库分表的升级,数据库一旦变化,可能很多后台的需求难以满足
优化思路:冗余数据,前台与后台服务与数据分离,解耦。

如上图所示:
- 前台和后台独立服务与数据,解耦
- 如果出现问题,相互不影响
- 通过不同的技术方案,在不同容忍度,业务对系统要求不同的情况下,可以使用不同的技术栈来满足各自的需求,如下图,后台使用ES或者hive在进行数据存储,用以满足“售各种奇形怪状的,大批量分页的,查询需求”

参考资料
https://mp.weixin.qq.com/s/d65cXGXp_jcEeELyDZxGVA
