1.什么是ID
一个ID可以是很多东西,但它有一个最重要的特性“唯一性”。如果你用ID标记了一段数据,那么你要确保在你的ID再次查找数据后,你不会有歧义或者冲突。
ID还可能有一些其他有用的属性:
- 全局唯一:这是ID的最基本要求。我们在对数据库集群作扩容时,为了保证负载的平衡,需要在不同的Shard之间进行数据的移动, 如果主键不唯一,我们就没办法这样随意的移动数据.
- 有序:直接根据主键就可以进行时间排序,而不是单独在时间列上建立普通索引主键上的聚集索引要比普通索引更快
- 有意义:ID可以包含一些特定的信息,例如生成时间(并不需要多精确)
- 紧凑:尽可能紧凑的格式,占用更小的空间
- 分布式:它们可以由一台机器生成,而无需访问任何其他机器 能保证每台电脑上的时间准确。但是NTP服务允许向后移动时间补偿时钟漂移,这需要我们在生成基于时间的ID的时候保证不会产生重复ID。
所以在分布式环境中,我们不能保证时间永远不变,也不能仅仅依靠时间进行排序或识别
在传统的SQL数据库,我们使用自动递增主键来实现排序
下面我们来看一下常用的主键生成策略
2. UUID
采用UUID作为主键是最简单的方案.
维基百科
通用唯一识别码(英语:Universally Unique Identifier,简称UUID)是一种软件建构的标准,亦为自由软件基金会组织在分散式计算环境领域的一部份。
UUID的目的,是让分散式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。如此一来,每个人都可以创建不与其它人冲突的UUID。在这样的情况下,就不需考虑数据库创建时的名称重复问题。目前最广泛应用的UUID,是微软公司的全局唯一标识符(GUID),而其他重要的应用,则有Linux ext2/ext3文件系统、LUKS加密分区、GNOME、KDE、Mac OS X等等。另外我们也可以在e2fsprogs包中的UUID库找到实现。
UUID是由一组32位数的16进制数字所构成,是故UUID理论上的总数为1632=2128,约等于3.4 x 1038。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
UUID的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的32个字符。示例:
550e8400-e29b-41d4-a716-446655440000
优点:
- 本地生成ID,不需要进行远程调用,时延低
- 扩展性好,基本可以认为没有性能上限
缺点:
- uuid过长,往往用字符串表示
- UUID的生成没有顺序性,所以在写入时, 需要随机更改索引的不同位置,这就需要更多的IO操作,如果索引太大而不能存放在内存中的话就更是如此。 而UUID索引时,一个key需要32个字节(当然如果采用二进制形式存储的话可以压缩到16个字节), 因此整个索引也会相对比较大
2. MySQL自增字段
结合数据库维护一个Sequence表:此方案的思路也很简单,在数据库中建立一个Sequence表,表的结构类似于
CREATE TABLE `SEQUENCE` (
`tablename` varchar(30) NOT NULL,
`nextid` bigint(20) NOT NULL,
PRIMARY KEY (`tablename`)
) ENGINE=InnoDB
每当需要为某个表的新纪录生成ID时就从Sequence表中取出对应表的nextid,并将nextid的值加1后更新到数据库中以备下次使用。
优点:
- 简单,使用数据库已有的功能
- 能够保证唯一性
- 能够保证递增性
- 步长固定
缺点:
- 可用性难以保证:数据库常见架构是一主多从+读写分离,生成自增ID是写请求,主库挂了就玩不转了
- 扩展性差,性能有上限:因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且难以扩展
3.flickr的ID自增
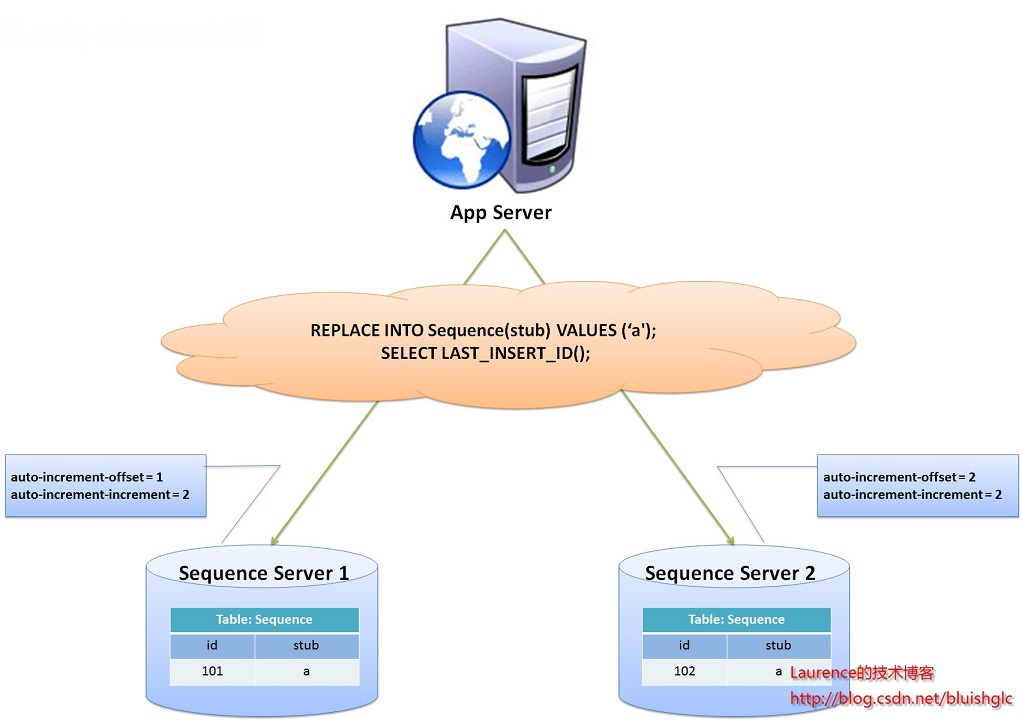
flickr这一方案的整体思想是:建立两台以上的数据库ID生成服务器,每个服务器都有一张记录各表当前ID的Sequence表,但是Sequence中ID增长的步长是服务器的数量,起始值依次错开,这样相当于把ID的生成散列到了每个服务器节点上。
例如:如果我们设置两台数据库ID生成服务器,那么就让一台的Sequence表的ID起始值为1,每次增长步长为2,另一台的Sequence表的ID起始值为2,每次增长步长也为2,那么结果就是奇数的ID都将从第一台服务器上生成,偶数的ID都从第二台服务器上生成,这样就将生成ID的压力均匀分散到两台服务器上,同时配合应用程序的控制,当一个服务器失效后,系统能自动切换到另一个服务器上获取ID,从而保证了系统的容错。
设置两台服务器的自增步长
一台服务器从1开始,步长为2,生成的ID永远为奇数,一台服务器从2开始步长为2生成的ID永远为偶数
Server1:
auto-increment-increment = 2
auto-increment-offset = 1
Server2:
auto-increment-increment = 2
auto-increment-offset = 2
在两台服务器上分别创建一个Sequence表
CREATE TABLE `Sequence` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=MyISAM
生成一个新的ID
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
REPLACE INTO和INSERT的功能一样,但是当使用REPLACE INTO插入新数据行时, 如果新插入的行的主键或唯一键(UNIQUE Key)已有的行重复时,已有的行会先被删除,然后再将新数据行插入
SELECT LAST_INSERT_ID()必须要于REPLACE INTO语句在同一个数据库连接下才能得到刚刚插入的新ID,否则返回的值总是0。该方案中Sequence表使用的是MyISAM引擎,以获取更高的性能.MyISAM引擎使用的是表级别的锁,MyISAM对表的读写是串行的,因此不必担心在并发时两次读取会得到同一个ID。
优点:简单可靠
缺点:ID只是一个ID,没有带入时间,shardingId等信息。
4. 基于数据库的号段模式
号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如(1,1000]代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。表结构如下:
CREATE TABLE id_generator (
id INT ( 10 ) NOT NULL,
max_id BIGINT ( 20 ) NOT NULL COMMENT '当前最大id',
step INT ( 20 ) NOT NULL COMMENT '号段的布长',
biz_type INT ( 20 ) NOT NULL COMMENT '业务类型',
version INT ( 20 ) NOT NULL COMMENT '版本号',
PRIMARY KEY ( `id` )
);
号段ID用完后,再次向数据库申请新号段,对maxid字段做一次update操作,update maxid= maxid + step,update成功则说明新号段获取成功,新的号段范围是(maxid ,max_id +step]。
UPDATE id_generator
SET max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
4.1. 美团的leaf方案
具体参考 https://tech.meituan.com/2017/04/21/mt-leaf.html 源码:https://github.com/Meituan-Dianping/Leaf
Leaf同时支持号段模式和snowflake算法模式,可以切换使用
DROP TABLE
IF
EXISTS `leaf_alloc`;
CREATE TABLE `leaf_alloc` (
`biz_tag` VARCHAR ( 128 ) NOT NULL DEFAULT '' COMMENT '业务key',
`max_id` BIGINT ( 20 ) NOT NULL DEFAULT '1' COMMENT '当前已经分配了的最大id',
`step` INT ( 11 ) NOT NULL COMMENT '初始步长,也是动态调整的最小步长',
`description` VARCHAR ( 256 ) DEFAULT NULL COMMENT '业务key的描述',
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '数据库维护的更新时间',
PRIMARY KEY ( `biz_tag` )
) ENGINE = INNODB;
- id表示为主键,无业务含义
- biz_tag为了表示业务,因为整体系统中会有很多业务需要生成ID,这样可以共用一张表维护
- max_id表示现在整体系统中已经分配的最大ID
- desc描述
- update_time表示每次取的ID时间
4.1.1. 整体流程
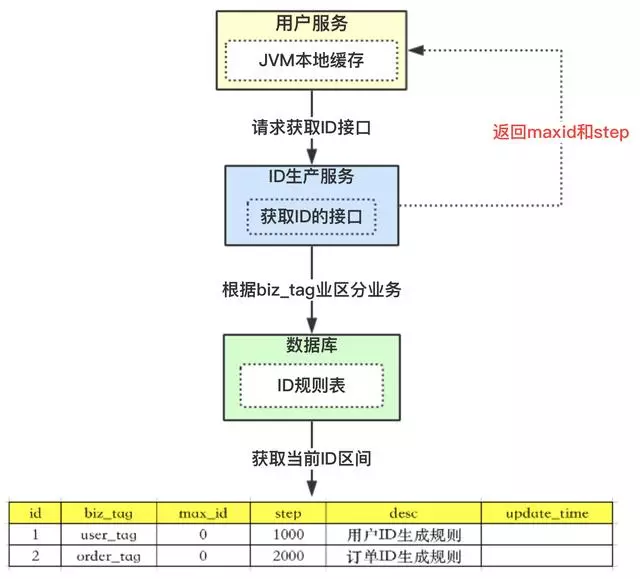
-
【用户服务】在注册一个用户时,需要一个用户ID;会请求【生成ID服务(是独立的应用)】的接口
-
【生成ID服务】会去查询数据库,找到user_tag的id,现在的max_id为0,step=1000
-
【生成ID服务】把max_id和step返回给【用户服务】;并且把max_id更新为max_id = max_id + step,即更新为1000
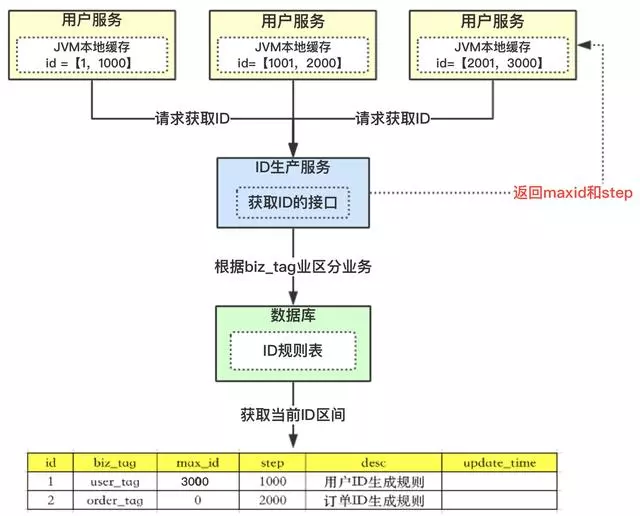
-
【用户服务】获得max_id=0,step=1000;
- 这个用户服务可以用ID=【max_id + 1,max_id+step】区间的ID,即为【1,1000】
- 【用户服务】会把这个区间保存到jvm中
- 【用户服务】需要用到ID的时候,在区间【1,1000】中依次获取id,可采用AtomicLong中的getAndIncrement方法。
- 如果把区间的值用完了,再去请求【生产ID服务】接口,获取到max_id为1000,即可以用【max_id + 1,max_id+step】区间的ID,即为【1001,2000】
上述方案解决了数据库压力的问题,因为在一段区间内,是在jvm内存中获取的,而不需要每次请求数据库。即使数据库宕机了,系统也不受影响,ID还能维持一段时间。
4.1.2. 竞争问题
以上方案中,如果是多个用户服务,同时获取ID,同时去请求【ID服务】,在获取max_id的时候会存在并发问题。
如用户服务A,取到的max_id=1000 ;用户服务B取到的也是max_id=1000,那就出现了问题,Id重复了。那怎么解决?
使用数据库行锁解决
4.1.3. 突发阻塞问题
上图中,多个用户服务获取到了各自的ID区间,在高并发场景下,ID用的很快,如果3个用户服务在某一时刻都用完了,同时去请求【ID服务】。因为上面提到的竞争问题,所有只有一个用户服务去操作数据库,其他二个会被阻塞。系统出现的现象就是一会儿突然系统耗时变长,一会儿好了。
美团采用双buffer方案解决这个问题
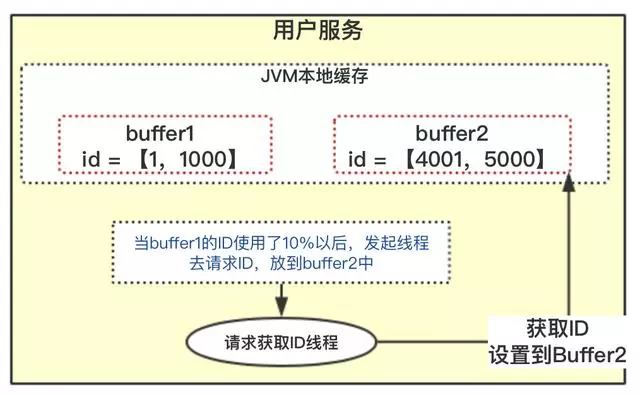
- 当前获取ID在buffer1中,每次获取ID在buffer1中获取
- 当buffer1中的Id已经使用到了100,也就是达到区间的10%
- 达到了10%,先判断buffer2中有没有去获取过,如果没有就立即发起请求获取ID线程,此线程把获取到的ID,设置到buffer2中
- 如果buffer1用完了,会自动切换到buffer2
- buffer2用到10%了,也会启动线程再次获取,设置到buffer1中
- 依次往返
此外leaf还监控ID使用频率,自动设置步长step,从而达到对ID节省使用。
5. snowflake
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的id必须不同。
0 00000.....000 00000 00000 000000000000
| |___________| |___| |___| |__________|
| | | | |
1bit 41bit 5bit 5bit 12bit
核心代码就是毫秒级时间41位+机器ID 10位+毫秒内序列12位
- 第一段:1bit 预留 实际上是作为long的符号位
- 第二段:41bit 时间标记 记录的是当前时间与元年的时间差
- 第三段:5bit 数据中心Id标记 记录的是数据中心的Id,5bit最大可以表示32个数据中心,这么多数据中心能保证全球范围内服务可用
- 第四段:5bit 节点标记 记录的是单个数据中心里面服务节点的Id,同理也是最大可以有32个节点,这个除非是整个数据中心离线,否则可以保证服务永远可用
- 第五段:12bit 单毫秒内自增序列 每毫秒可以生成4096个ID
除了最高位bit标记为不可用以外,其余三组bit位数均可根据具体的业务需求浮动。
5.1. 时间戳
时间戳的细度是毫秒级
因为NTP的存在,snowflake存在时钟漂移问题
5.2. 数据中心ID和节点标记
机器级可以使用MAC地址来唯一标识工作机器
工作进程级可以使用IP+Path来标识工作进程
如果工作机器比较少,也可以使用配置文件来设置这个id,需要注意如果机器过多,维护配置文件将是一个灾难性的事情。考虑到自动部署、运维等等问题,机器编码最好由系统自动维护,有以下两个方案可供选择:
- 使用mysql自增ID特性,用数据表,存储机器的mac地址或者ip来维护。
- 使用ZooKeeper持久顺序节点的特性。
5.3. 自增序列
序列号就是一系列的自增id(多线程建议使用atomic),为了处理在同一毫秒内需要给多条消息分配id,若同一毫秒把序列号用完了,则“等待至下一毫秒”。
下面是一段代码示例
class SimpleSnowflakeIdFactory implements IdFactory<Long>, TimeExtracter<Long>, SeqExtracter<Long>,
ServerExtracter<Long> {
/**
* 自增序列的位数
*/
private static final int SEQ_BIT = 12;
/**
* 节点标识的位数
*/
private static final int SERVER_BIT = 10;
/**
* 最大序列号
*/
private static final int SEQ_MASK = -1 ^ (-1 << SEQ_BIT);
/**
* 最大server
*/
private static final int SERVER_MASK = -1 ^ (-1 << SERVER_BIT);
/**
* 时间的左移位数
*/
private static final int TIME_LEFT_BIT = SEQ_BIT + SERVER_BIT;
/**
* SERVER的左移位数
*/
private static final int SERVER_LEFT_BIT = SEQ_BIT;
/**
* 每次初始化对序列值.
*/
private static final int INIT_SEQ = 0;
/**
* 服务器id
*/
private final int serverId;
/**
* 上次时间戳
*/
private volatile long lastTime = -1l;
/**
* 自增序列
*/
private volatile long seqId = INIT_SEQ;
private SimpleSnowflakeIdFactory(int serverId) {
this.serverId = serverId & SERVER_MASK;
}
@Override
public synchronized Long nextId() {
long time = currentTime();
if (time < lastTime) {//当前时间小于上次时间,说明时钟不对
throw new IllegalStateException("Clock moved backwards.");
}
if (time == lastTime) {
seqId = (seqId + 1) & SEQ_MASK;
if (seqId == 0) {//说明该毫秒下对序列已经自增完毕,等待下一个毫秒
tilNextMillis(lastTime);
}
} else {
seqId = INIT_SEQ;
}
lastTime = time;
long id = time << TIME_LEFT_BIT;
id |= serverId << SERVER_LEFT_BIT;
id |= seqId;// & SEQ_MASK;
return id;
}
/**
* 从主键中提取时间.
* 将ID左移22位,提取出时间
*
* @param id 主键
* @return 时间
*/
@Override
public long fetchTime(Long id) {
return id >> TIME_LEFT_BIT;
}
@Override
public long fetchServer(Long id) {
return (id ^ (fetchTime(id) << TIME_LEFT_BIT)) >> SERVER_LEFT_BIT;
}
@Override
public long fetchSeq(Long id) {
return (id ^ (fetchTime(id) << TIME_LEFT_BIT)) ^ (fetchServer(id) << SERVER_LEFT_BIT);
}
}
优点:充分把信息保存到ID里。
缺点:结构略复杂,要依赖zookeeper,分片ID不能灵活生成。强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
在数据量大时往往需要分库分表,这些ID经常作为取模分库分表的依据,为了分库分表后数据均匀,ID生成往往有“取模随机性”的需求,所以我们通常把每秒内的序列号放在ID的最末位,保证生成的ID是随机的。同时我们在跨毫秒时,序列号总是归0,会使得序列号为0的ID比较多,导致生成的ID取模后不均匀。解决方法是,序列号不是每次都归0,而是归一个0到9的随机数.
因为时钟漂移的问题,即使每台服务器分配的ID是绝对递增的,但从全局来看生成的ID只是趋势递增的
5.4. redis lua实现snowflake
直接上代码
local lock_key = 'id-generator-lock'
local sequence_key = 'id-generator-sequence'
local logical_shard_id_key = 'id-generator-logical-shard-id'
local max_sequence = 4095 --自增序列的最大值
local min_logical_shard_id = 0 --最小的分片ID
local max_logical_shard_id = 1023 --最大的分片ID
--如果存在锁标识说明当前毫秒下的自增序列已经分配完毕,必须等到下一个毫秒才能分配新的序列
if redis.call('EXISTS', lock_key) == 1 then
redis.log(redis.LOG_NOTICE, 'Cannot generate ID, waiting for lock to expire.')
return redis.error_reply('Cannot generate ID, waiting for lock to expire.')
end
local sequence = redis.call('INCR', sequence_key) --自增序列+1
local logical_shard_id = tonumber(redis.call('GET', logical_shard_id_key)) or -1 --分片ID
--检查分片ID
if logical_shard_id < min_logical_shard_id or logical_shard_id > max_logical_shard_id then
redis.log(redis.LOG_NOTICE, 'Cannot generate ID, logical_shard_id invalid.')
return redis.error_reply('Cannot generate ID, logical_shard_id invalid.')
end
if sequence >= max_sequence then
--[[
如果生成的序列大于最大的序列值,设置锁标识并设置过期时间为1毫秒
--]]
redis.log(redis.LOG_NOTICE, 'Rolling sequence back to the start, locking for 1ms.')
redis.call('SET', sequence_key, '-1')
redis.call('PSETEX', lock_key, 1, 'lock')
sequence = max_sequence
end
--将移位计算交给客户端实现
local current_time = redis.call('TIME')
return {
sequence,
logical_shard_id,
tonumber(current_time[1]) * 1000 + math.floor(tonumber(current_time[2]) / 1000)
}
java的调用代码
List<String> keys = new ArrayList<String>();
List<String> argv = new ArrayList<String>();
for (int i = 0; i < 5000; i++) {
List<Long> result =
new ArrayList<Long>(
(Collection<Long>) jedis.eval(loadScriptString("id2.lua"), keys, argv));
long seq = result.get(0);
long shardId = result.get(1);
long time = result.get(2);
long id = (time << 22)
| (shardId << 12)
| seq;
System.out.println(id);
}
上述的代码如果当前毫秒下的自增序列已经分配完毕,会返回一个错误信息给调用方,这就要求调用方捕获这个错误并作出相应的处理(重试或者抛出异常)。而且自增序列增长到4094之后,即使时间已经到了下1毫秒,由于自增序列没有重置为-1,那么这一毫秒只能生成一个ID,目前还没有想到好的处理办法
注:我尝试了两种处理方式都不是很理想: 1.将自增序列每次都设为1毫秒过期
redis.call('PEXPIRE', sequence_key, 1)
可能1毫秒的时间间隔很短,依然有很多请求的自增序列是从上一毫秒的序列开始自增的
2.在自增序列分配完毕之后将脚本阻塞1毫秒
--根据当前时间生成主键key
local now = redis.call('TIME')
local sequence_key = 'id-generator-sequence' .. '-' .. now[1] .. '-' .. math.floor(now[2]/1000);
local sequence
--如果自增序列大于最大的序列,说明当前毫秒的序列已经分配完毕,使用循环重试的方法直到时间跳到下一毫秒
repeat
sequence = tonumber(redis.call('INCRBY', sequence_key, 1))
if sequence > max_sequence then
now = redis.call('TIME')
sequence_key = 'id-generator-sequence' .. '-' .. now[1] .. '-' .. math.floor(now[2]/1000);
end
until sequence <= max_sequence
但是因为TIME命令是REDIS_CMD_RANDOM属性的命令,而当一个脚本执行了拥有REDIS_CMD_RANDOM属性的命令后,就不能执行拥有REDIS_CMD_WRITE属性的命令了,所以下面的脚本并不能成功运行,权做参考.默认的LUA不支持取毫秒数,必须扩展lua才行,我不太喜欢这样做。
在并发量大时,可以使用批量的方式降低调用redis的损耗,代码与上面的代码基本一致,只是使用INCRBY来增长序列,并且在返回值返回start_sequence和end_sequence由调用方来生成对应的ID列表。
local num_ids = tonumber(ARGV[1]) --需要获取的ID数量
local end_sequence = redis.call('INCRBY', sequence_key, num_ids) --最大的序列
local start_sequence = end_sequence - num_ids + 1 --最小的序列
if end_sequence >= max_sequence then
--[[
如果生成的序列大于最大的序列值,设置锁标识并设置过期时间为1毫秒
--]]
redis.log(redis.LOG_NOTICE, 'Rolling sequence back to the start, locking for 1ms.')
redis.call('SET', sequence_key, '-1')
redis.call('PSETEX', lock_key, 1, 'lock')
end_sequence = max_sequence
end
--将移位计算交给客户端实现
local current_time = redis.call('TIME')
return {
start_sequence,
end_sequence,
logical_shard_id,
tonumber(current_time[1]) * 1000 + math.floor(tonumber(current_time[2]) / 1000)
}
当然上述的方法也存在问题:生成ID可能会不连续,中间会出现空洞。一次不能取太多的ID,否则会导致其他生成ID的请求失败。
5.5. snowflake的时钟回拨问题
snowflake方案依赖系统时钟,如果机器时钟回拨,就有可能生成重复ID,为了保证ID唯一性,必须解决时钟回拨问题。可以采取以下几种方案解决时钟问题:
- 关闭系统NTP同步,这样就不会产生时钟调整
- 系统做出判断,在时钟回拨这段时间,不生成ID,直接返回ERROR_CODE,直到时钟追上,恢复服务。
if (time < lastTime) {//当前时间小于上次时间,说明时钟不对
throw new IllegalStateException("Clock moved backwards.");
}
- 系统做出判断,如果遇到超过容忍限度的回拨,上报报警系统,并把自身从集群节点中摘除

- 系统做兼容处理,由于nfp网络回拨都是几十毫秒到几百毫秒,极少数到秒级别,这种回拨会产生以下几种结果:系统中缓存最近几秒内最后的发号序号(具体范围请根据实际需要确定),存储格式为:时间秒-序号。
- 当前秒数不变:当前是8:30秒100毫秒,ntp回拨50毫秒,当前时间变成8:30秒50毫秒,这个时候秒数没变,我们算法的时间戳部分不会产生重复,就不影响系统继续发号
- 当前秒数向前:当前是8:30秒800毫秒,ntp 向前调整300毫秒,当前时间变成8:31秒100毫秒,由于这个时间还没发过号,不会生成重复的ID
- 当前秒数向后:当前是8:30秒100毫秒,ntp回拨150毫秒,当前时间变成8:29秒950毫秒,这个时候秒发生回退,就可能产生重复ID。产生重复的原因在于秒回退后,算法的时间戳部分使用了已经用过的时间戳,但是算法的序号部分,并没有回退到29秒那个时间对应的序号,依然使用当前的序号,如果序号也同时回退到29秒时间戳所对应的最后序号,就不会重复发号。解决方案如下:

类似的实现还有 https://github.com/didi/tinyid https://github.com/baidu/uid-generator uid-generator的时间递增没有通过System.currentTimeMillis()来获取时间并与上一次时间进行比较(这样的实现严重依赖服务器的时间),而是通过AtomicLong的incrementAndGet()方法获取下一次的时间,从而脱离了对服务器时间的依赖,也就不会有时钟回拨的问题
5.5. 结合业务使用snowflake
不同公司也会依据自身业务的特点对 Snowflake 算法做一些改造,比如说减少序列号的位数增加机器 ID 的位数以支持单 IDC 更多的机器,也可以在其中加入业务 ID 字段来区分不同的业务。借鉴snowflake的思想,结合各公司的业务逻辑和并发量,可以实现自己的分布式ID生成算法。 举例,假设某公司ID生成器服务的需求如下:
- 单机高峰并发量小于1W,预计未来5年单机高峰并发量小于10W
- 有2个机房,预计未来5年机房数量小于4个
- 每个机房机器数小于100台
- 目前有5个业务线有ID生成需求,预计未来业务线数量小于10个
分析过程如下:
- 高位取从2016年1月1日到现在的毫秒数(假设系统ID生成器服务在这个时间之后上线),假设系统至少运行10年,那至少需要10年365天24小时3600秒1000毫秒=320*10^9,差不多预留39bit给毫秒数
- 每秒的单机高峰并发量小于10W,即平均每毫秒的单机高峰并发量小于100,差不多预留7bit给每毫秒内序列号
- 5年内机房数小于4个,预留2bit给机房标识
- 每个机房小于100台机器,预留7bit给每个机房内的服务器标识
-
业务线小于10个,预留4bit给业务线标识
0 00000…..000 0000 00 0000000 0…..0 0000000 | |____| |__| || || || |___| | | | | | | | 1bit 39bit毫秒 4bit业务 2bit机房 7bit机器 预留 7bit序列
这样设计的64bit标识,可以保证:
- 每个业务线、每个机房、每个机器生成的ID都是不同的
- 同一个机器,每个毫秒内生成的ID都是不同的
- 同一个机器,同一个毫秒内,以序列号区区分保证生成的ID是不同的
- 将毫秒数放在最高位,保证生成的ID是趋势递增的
5.6. 工程化
了解了 Snowflake 算法的原理之后,我们如何把它工程化,来为业务生成全局唯一的 ID 呢?一般来说我们会有两种算法的实现方式:
- 一种是嵌入到业务代码里,也就是分布在业务服务器中。这种方案的好处是业务代码在使用的时候不需要跨网络调用,性能上会好一些,但是就需要更多的机器 ID 位数来支持更多的业务服务器。另外,由于业务服务器的数量很多,我们很难保证机器 ID 的唯一性,所以就需要引入 ZooKeeper 等分布式一致性组件来保证每次机器重启时都能获得唯一的机器 ID。
另外一个部署方式是作为独立的服务部署,这也就是我们常说的发号器服务。业务在使用发号器的时候就需要多一次的网络调用,但是内网的调用对于性能的损耗有限,却可以减少机器 ID 的位数,如果发号器以主备方式部署,同时运行的只有一个发号器,那么机器 ID 可以省略,这样可以留更多的位数给最后的自增信息位。即使需要机器 ID,因为发号器部署实例数有限,那么就可以把机器 ID 写在发号器的配置文件里,这样可以保证机器 ID 唯一性,也无需引入第三方组件了。微博和美图都是使用独立服务的方式来部署发号器的,性能上单实例单 CPU 可以达到两万每秒。
Snowflake 算法设计得非常简单且巧妙,性能上也足够高效,同时也能够生成具有全局唯一性、单调递增性和有业务含义的 ID,但是它也有一些缺点,其中最大的缺点就是它依赖于系统的时间戳,一旦系统时间不准,就有可能生成重复的 ID。所以如果我们发现系统时钟不准,就可以让发号器暂时拒绝发号,直到时钟准确为止。
另外,如果请求发号器的 QPS 不高,比如说发号器每毫秒只发一个 ID,就会造成生成 ID 的末位永远是 1,那么在分库分表时如果使用 ID 作为分区键就会造成库表分配的不均匀。这一点,也是我在实际项目中踩过的坑,而解决办法主要有两个:
-
时间戳不记录毫秒而是记录秒,这样在一个时间区间里可以多发出几个号,避免出现分库分表时数据分配不均。
-
生成的序列号的起始号可以做一下随机,这一秒是 21,下一秒是 30,这样就会尽量地均衡了。
6. instagram的方案
instagram参考了flickr的方案,再结合twitter的经验,利用Postgres数据库的特性,实现了一个更简单可靠的ID生成服务。
- 使用41 bit来存放时间,精确到毫秒,可以使用41年。
- 使用13 bit来存放逻辑分片ID。
- 使用10 bit来存放自增长ID,意味着每台机器,每毫秒最多可以生成1024个ID
以instagram举的例子为说明: 假定时间是September 9th, 2011, at 5:00pm,则毫秒数是1387263000(直接使用系统得到的从1970年开始的毫秒数)。那么先把时间数据放到ID里: id = 1387263000 « (64-41)
再把分片ID放到时间里,假定用户ID是31341,有2000个逻辑分片,则分片ID是31341 % 2000 -> 1341: id |= 1341 « (64-41-13)
最后,把自增序列放ID里,假定前一个序列是5000,则新的序列是5001: id |= (5001 % 1024)
这样就得到了一个全局的分片ID。
下面列出instagram使用的Postgres schema的sql:
REATE OR REPLACE FUNCTION insta5.next_id(OUT result bigint) AS $$
DECLARE
our_epoch bigint := 1314220021721;
seq_id bigint;
now_millis bigint;
shard_id int := 5;
BEGIN
SELECT nextval('insta5.table_id_seq') %% 1024 INTO seq_id;
SELECT FLOOR(EXTRACT(EPOCH FROM clock_timestamp()) * 1000) INTO now_millis;
result := (now_millis - our_epoch) << 23;
result := result | (shard_id << 10);
result := result | (seq_id);
END;
$$ LANGUAGE PLPGSQL;
则在插入新数据时,直接用类似下面的SQL即可(连请求生成ID的步骤都省略了!):
CREATE TABLE insta5.our_table (
"id" bigint NOT NULL DEFAULT insta5.next_id(),
...rest of table schema...
)
缺点:
优点:
- 充分把信息保存到ID里。
- 充分利用数据库自身的机制,程序完全不用额外处理,直接插入到对应的分片的表即可。
我尝试在MySQL下实现了一下,可能我对MySQL不是太熟,觉得实现太过复杂,中途放弃了,权当参考
7. 参考资料
https://mp.weixin.qq.com/s/6J7n3udEyQvUHRHwvALNYw
https://tech.meituan.com/2017/04/21/mt-leaf.html
http://blog.csdn.net/bluishglc/article/details/7710738
https://mp.weixin.qq.com/s/KfoLFClRwDXlcTDmhCEdaQ
http://www.zolazhou.com/posts/primary-key-selection-in-database-partition-design/
http://blog.csdn.net/hengyunabc/article/details/19025973
https://mp.weixin.qq.com/s/AHRCYOjnXAgcy2j6vziukQ
http://engineering.intenthq.com/2015/03/icicle-distributed-id-generation-with-redis-lua/
http://code.flickr.net/2010/02/08/ticket-servers-distributed-unique-primary-keys-on-the-cheap/
https://github.com/intenthq/icicle/blob/master/icicle-core/src/main/resources/id-generation.lua
https://www.lanindex.com/twitter-snowflake%EF%BC%8C64%E4%BD%8D%E8%87%AA%E5%A2%9Eid%E7%AE%97%E6%B3%95%E8%AF%A6%E8%A7%A3/
https://mp.weixin.qq.com/s/HRJb8iBsXJTdsUhfhOxHlw
https://mp.weixin.qq.com/s/8ZWUmlhmP2PR1XGGqjEUQQ
https://mp.weixin.qq.com/s/hz7TntFDurwkAaSGODbF-Q
