在 Hotspot 虚拟机中,对象在内存中的布局可以分为3块区域:对象头、实例数据和对齐填充。
Hotspot虚拟机的对象头包括两部分信息,第一部分用于存储对象自身的自身运行时数据Mark Word(哈希码、GC分代年龄、锁状态标志等等),另一部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是那个类的实例。
实例数据部分是对象真正存储的有效信息,也是在程序中所定义的各种类型的字段内容。
对齐填充部分不是必然存在的,也没有什么特别的含义,仅仅起占位作用。因为Hotspot虚拟机的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是对象的大小必须是8字节的整数倍。而对象头部分正好是8字节的倍数(1倍或2倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
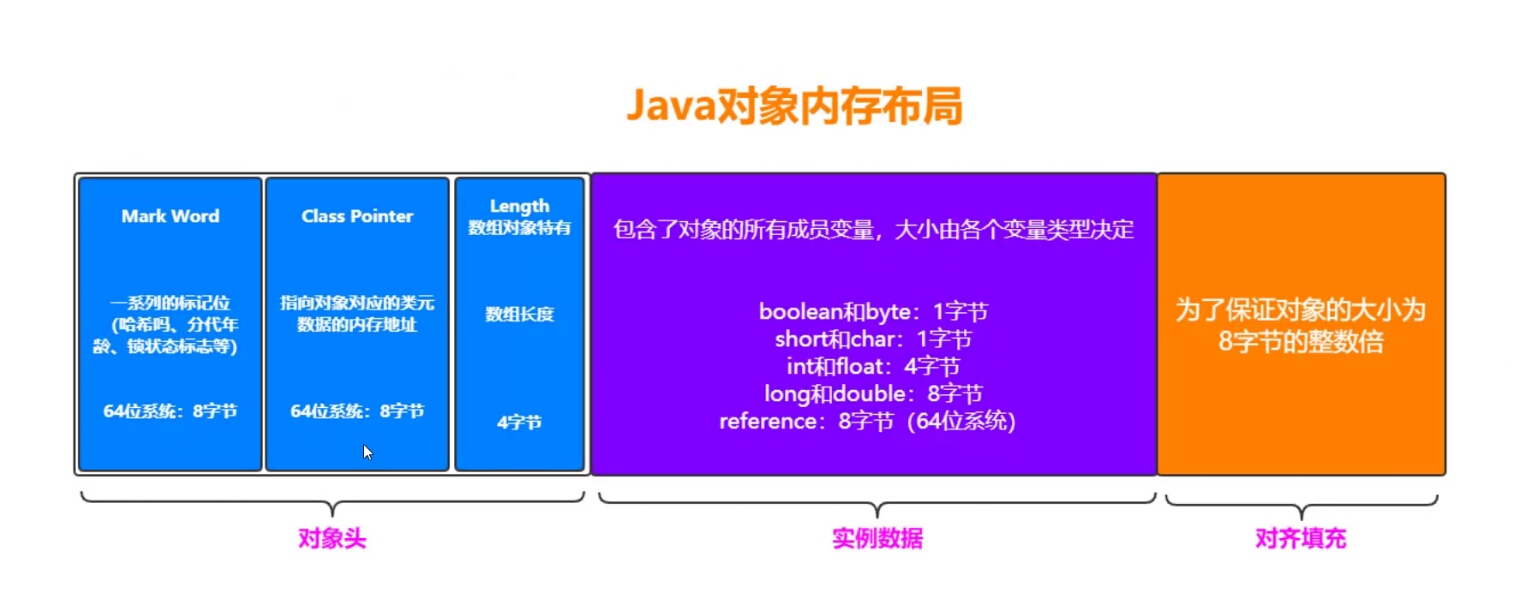
32位的MarkWord和ClassPoint分别占4个字节,64位分别占8个字节
对象头
对象头(Object Header)包括两部分信息,第一部分用于存储对象自身的运行时数据Mark Word。另外一部分是类型指针,即是对象指向它的类的元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。另外,如果对象时一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据。
| 长度 | 内容 | 说明 |
|---|---|---|
| 32/64bit | Mark Word | 存储对象的hashCode或锁的信息等 |
| 32/64bit | Class Metadata Address | 存储到对象类型数据的指针 |
| 32/64bit | Array length | 数组的长度(如果当前对象是数组) |
普通对象
|--------------------------------------------------------------|
| Object Header (64 bits) |
|------------------------------------|-------------------------|
| Mark Word (32 bits) | Klass Word (32 bits) |
|------------------------------------|-------------------------|
数组对象
|---------------------------------------------------------------------------------|
| Object Header (96 bits) |
|--------------------------------|-----------------------|------------------------|
| Mark Word(32bits) | Klass Word(32bits) | array length(32bits) |
|--------------------------------|-----------------------|------------------------|
对象头的大小一般和系统的位数有关,也和启动参数UseCompressedOops有关:
- 32位系统,占用 8 字节
- 64位系统,如果通过
-XX:+UseCompressedOops开启UseCompressedOops时,占用 12 字节,否则占用16字节
压缩指针,指的是在 64 位的机器上,使用 32 位的指针来访问数据(堆中的对象或 Metaspace 中的元数据)的一种方式。
这样有很多的好处,比如 32 位的指针占用更小的内存,可以更好地使用缓存,在有些平台,还可以使用到更多的寄存器。
当然,在 64 位的机器中,最终还是需要一个 64 位的地址来访问数据的,所以这个 32 位的值是相对于一个基准地址的值。
new一个空对象在32为系统中占用内存大小是8byte(对象头,在堆中)+4byte(对象的引用地址,在栈中)=12byte;
new一个空对象在64为系统中占用内存大小是16byte(对象头,在堆中)+8byte(对象的引用地址,在栈中)=24byte;
可想而知同一个对象在64位系统中占的内存加大一半了,不仅消耗运行内存,而且GC回收时挺耗cpu的。
jvm的属性
-XX:+UseCompressedOops在JDK 1.6和之后的版本都默认开启了,所以jvm开启了压缩之后64为系统的对象也只占用12byte。
Mark Word
对象头用于存储对象自身的运行时数据, 如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,这部分数据的长度在32位和64位的虚拟机(暂不考虑开启压缩指针的场景)中分别为32个和64个Bits,官方称它为“Mark Word”。
当这个对象被synchronized关键字当成同步锁时,围绕这个锁的一系列操作都和Mark Word有关。 Mark Word在32位JVM中的长度是4个字节,在64位JVM中长度是8个字节。
32位JVM Mark Word 结构
| 锁状态 | 25bit | 4bit | 1bit是否是偏向锁 | 2bit锁标志位 |
|---|---|---|---|---|
| 无锁状态 | 对象的hashCode | 对象分代年龄 | 0 | 01 |
64位JVM Mark Word 结构

Mark Word在不同的锁状态下存储的内容不同,在32位JVM中是这么存的:
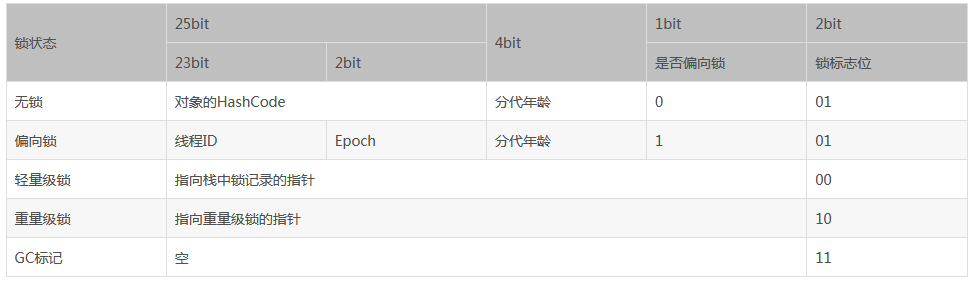
其中无锁和偏向锁的锁标志位都是01,只是在前面的1bit区分了这是无锁状态还是偏向锁状态。
新建对象分代年龄为0,之后每次在新生代拷贝一次就年龄+1,当年龄超过一个阈值之后,就会被丢入老年代。默认情况下,并行GC的年龄阈值为15,并发GC的年龄阈值为6。由于age只有4位,所以最大值为15,这就是 -XX:MaxTenuringThreshold 选项最大值为15的原因。
JVM一般是这样使用锁和Mark Word的:
1,当没有被当成锁时,这就是一个普通的对象,Mark Word记录对象的HashCode,锁标志位是01,是否偏向锁那一位是0。
2,当对象被当做同步锁并有一个线程A抢到了锁时,锁标志位还是01,但是否偏向锁那一位改成1,前23bit记录抢到锁的线程id,表示进入偏向锁状态。
3,当线程A再次试图来获得锁时,JVM发现同步锁对象的标志位是01,是否偏向锁是1,也就是偏向状态,Mark Word中记录的线程id就是线程A自己的id,表示线程A已经获得了这个偏向锁,可以执行同步锁的代码。
4,当线程B试图获得这个锁时,JVM发现同步锁处于偏向状态,但是Mark Word中的线程id记录的不是B,那么线程B会先用CAS操作试图获得锁,这里的获得锁操作是有可能成功的,因为线程A一般不会自动释放偏向锁。如果抢锁成功,就把Mark Word里的线程id改为线程B的id,代表线程B获得了这个偏向锁,可以执行同步锁代码。如果抢锁失败,则继续执行步骤5。
5,偏向锁状态抢锁失败,代表当前锁有一定的竞争,偏向锁将升级为轻量级锁。JVM会在当前线程的线程栈中开辟一块单独的空间,里面保存指向对象锁Mark Word的指针,同时在对象锁Mark Word中保存指向这片空间的指针。上述两个保存操作都是CAS操作,如果保存成功,代表线程抢到了同步锁,就把Mark Word中的锁标志位改成00,可以执行同步锁代码。如果保存失败,表示抢锁失败,竞争太激烈,继续执行步骤6。
6,轻量级锁抢锁失败,JVM会使用自旋锁,自旋锁不是一个锁状态,只是代表不断的重试,尝试抢锁。从JDK1.7开始,自旋锁默认启用,自旋次数由JVM决定。如果抢锁成功则执行同步锁代码,如果失败则继续执行步骤7。
7,自旋锁重试之后如果抢锁依然失败,同步锁会升级至重量级锁,锁标志位改为10。在这个状态下,未抢到锁的线程都会被阻塞。
class pointer
这一部分用于存储对象的类型指针,该指针指向它的类元数据,JVM通过这个指针确定对象是哪个类的实例。该指针的位长度为JVM的一个字大小,即32位的JVM为32位,64位的JVM为64位。
如果应用的对象过多,使用64位的指针将浪费大量内存,统计而言,64位的JVM将会比32位的JVM多耗费50%的内存。为了节约内存可以使用选项-XX:+UseCompressedOops开启指针压缩,其中,oop即ordinary object pointer普通对象指针。开启该选项后,下列指针将压缩至32位:
- 每个Class的属性指针(即静态变量)
- 每个对象的属性指针(即对象变量)
- 普通对象数组的每个元素指针
当然,也不是所有的指针都会压缩,一些特殊类型的指针JVM不会优化,比如指向PermGen的Class对象指针(JDK8中指向元空间的Class对象指针)、本地变量、堆栈元素、入参、返回值和NULL指针等。
array length
如果对象是一个数组,那么对象头还需要有额外的空间用于存储数组的长度,这部分数据的长度也随着JVM架构的不同而不同:32位的JVM上,长度为32位;64位JVM则为64位。64位JVM如果开启-XX:+UseCompressedOopss选项,该区域长度也将由64位压缩至32位。
实例数据
实例数据部分是对象真正存储的有效信息,也就是我们在程序代码里面所定义的各种类型的字段内容,无论是从父类继承下来的,还是在子类中定义的都需要记录下来。 这部分的存储顺序会受到虚拟机分配策略参数-XX:FieldsAllocationStyle和字段在Java源码中定义顺序的影响。
Hotspot默认分配策略下的排列顺序为(相同宽度的字段放在一起):
- long/double
- int
- short/char
- byte/boolean
- oop(引用对象指针)
默认分配策略还规定,父类的字段先排列,然后再排列子类的字段,如果通过-XX:+CompactFields参数开启压缩模式,那么会打破此规则。
对齐填充
对齐填充不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。HotSpot 虚拟机中规定对象的大小必须是8字节的整数倍,换句话说,就是对象的大小必须是 8 字节的整数倍。因此当对象实例数据部分没有对齐时,需要通过对齐填充来补全。对象内存空间中的实例数据和对齐填充是交替出现的,例如:假设类定义如下:
class MyClass {
byte a;
int c;
boolean d;
long e;
Object f;
}
那么它的空间分配如下:
[HEADER: 8 bytes] 8
[e: 8 bytes] 16
[c: 4 bytes] 20
[a: 1 byte ] 21
[d: 1 byte ] 22
[padding: 2 bytes] 24
[f: 4 bytes] 28
[padding: 4 bytes] 32
CPU一次寻址一般是2的倍数,所以一般会按照2的倍数来对齐提高CPU效率.这个似乎没什么好讲的.此外,JVM上对齐填充也方便gc, JVM能直接计算出对象的大小, 就能快速定位到对象的起始终止地址.
参考资料
https://www.jianshu.com/p/3d38cba67f8b
https://www.jianshu.com/p/421c1f1425f5
https://blog.csdn.net/lkforce/article/details/81128115
https://www.kancloud.cn/imnotdown1019/java_core_full/1012266#_HotSpot__155
https://wiki.openjdk.java.net/display/HotSpot/CompressedOops
