在 JAVA 语言中有8中基本类型和一种比较特殊的类型String。这些类型为了使他们在运行过程中速度更快,更节省内存,都提供了一种常量池的概念。常量池就类似一个JAVA系统级别提供的缓存。
基本类型的缓存参考这篇
String类型的常量池比较特殊。它的主要使用方法有两种:
- 直接使用双引号声明出来的String对象会直接存储在常量池中。
- 如果不是用双引号声明的String对象,可以使用String提供的intern方法。intern 方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中
String的String Pool是一个固定大小的Hashtable,默认值大小长度是1009,如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降(因为要一个一个找)。
在 jdk6中StringTable固定为1009,所以如果常量池中的字符串过多就会导致效率下降很快。在jdk7中,StringTable的长度默认为60013,但是可以通过一个参数指定:-XX:StringTableSize=99991
为什么是 1009,而不是 1000 或者 1024?因为 1009 是质数,有利于达到更好的散列。60013 同理。
可以通过
java -XX:+PrintFlagsFinal -version查看默认值
对于下面的代码
String s1 = "hello";
String s2 = "hello";
对于这种直接通过双引号”“声明字符串的方式, 虚拟机首先会到字符串常量池中查找该字符串是否已经存在. 如果存在会直接返回该引用, 如果不存在则会在先在字符串常量池中创建该字符串。

所以s1和s2指向的是同一个对象,s1==s2
通过javap -v反编译后可以看到这两个变量的创建
...
// 常量池在编译期就确定好了
Constant pool:
#1 = Methodref #4.#21 // java/lang/Object."<init>":()V
#2 = String #22 // hello
#3 = Class #23 // com/edgar615/string/StringTest
#4 = Class #24 // java/lang/Object
#5 = Utf8 <init>
#6 = Utf8 ()V
#7 = Utf8 Code
#8 = Utf8 LineNumberTable
#9 = Utf8 LocalVariableTable
#10 = Utf8 this
#11 = Utf8 Lcom/edgar615/string/StringTest;
#12 = Utf8 main
#13 = Utf8 ([Ljava/lang/String;)V
#14 = Utf8 args
#15 = Utf8 [Ljava/lang/String;
#16 = Utf8 s1
#17 = Utf8 Ljava/lang/String;
#18 = Utf8 s2
#19 = Utf8 SourceFile
#20 = Utf8 StringTest.java
#21 = NameAndType #5:#6 // "<init>":()V
#22 = Utf8 hello
#23 = Utf8 com/edgar615/string/StringTest
#24 = Utf8 java/lang/Object
{
...
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=3, args_size=1
0: ldc #2 // String hello
2: astore_1
3: ldc #2 // String hello
5: astore_2
6: return
...
}
常量池中的“对象”是在编译期就确定好了的,在类被加载的时候创建的,如果类加载时,该字符串常量在常量池中已经有了,那这一步就省略了。
可以看到常量池中有一个hello的常量
#2 = String #22 // hello
在main方法内部
// 将int、float或String型常量从常量池推送至栈顶
0: ldc #2 // String hello
// 栈顶ref对象存入第1局部变量
2: astore_1
// 将int、float或String型常量从常量池推送至栈顶
3: ldc #2 // String hello
// 栈顶ref对象存入第2局部变量
5: astore_2
6: return
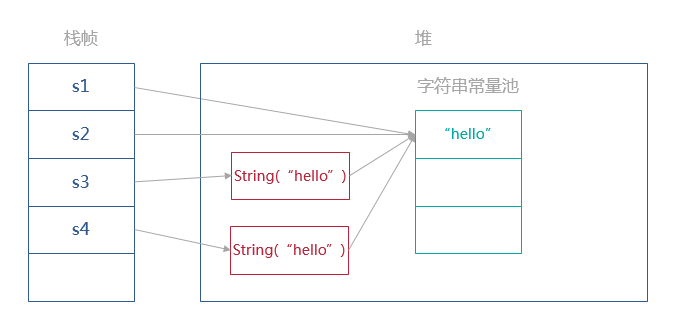
对于下面的代码
String s3 = new String("hello");
String s4 = new String("hello");
对于通过new String("hello")声明的字符串,虚拟机首先会
- 到字符串中查找该字符串是否已经存在. 如果存在会直接返回该引用, 如果不存在则会在先在字符串常量池中创建该字符串。
- 在堆中new一个String(“hello”)
- 将对象地址肤质给s3,创建一个引用
通过javap -v反编译后可以看到这两个变量的创建
...
Constant pool:
#1 = Methodref #6.#23 // java/lang/Object."<init>":()V
#2 = Class #24 // java/lang/String
#3 = String #25 // hello
#4 = Methodref #2.#26 // java/lang/String."<init>":(Ljava/lang/String;)V
#5 = Class #27 // com/edgar615/string/StringTest
#6 = Class #28 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 Lcom/edgar615/string/StringTest;
#14 = Utf8 main
#15 = Utf8 ([Ljava/lang/String;)V
#16 = Utf8 args
#17 = Utf8 [Ljava/lang/String;
#18 = Utf8 s3
#19 = Utf8 Ljava/lang/String;
#20 = Utf8 s4
#21 = Utf8 SourceFile
#22 = Utf8 StringTest.java
#23 = NameAndType #7:#8 // "<init>":()V
#24 = Utf8 java/lang/String
#25 = Utf8 hello
#26 = NameAndType #7:#29 // "<init>":(Ljava/lang/String;)V
#27 = Utf8 com/edgar615/string/StringTest
#28 = Utf8 java/lang/Object
#29 = Utf8 (Ljava/lang/String;)V
{
...
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=3, args_size=1
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String hello
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: astore_1
10: new #2 // class java/lang/String
13: dup
14: ldc #3 // String hello
16: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
19: astore_2
20: return
...
}
在main方法内部
// 创建类实例
0: new #2 // class java/lang/String
// 复制栈顶数值,并压入栈顶
3: dup
// 将int、float或String型常量从常量池推送至栈顶
4: ldc #3 // String hello
// 调用特殊实例方法(包括实例初始化方法、父类方法)
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
// 栈顶ref对象存入第1局部变量
9: astore_1
10: new #2 // class java/lang/String
13: dup
14: ldc #3 // String hello
16: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
19: astore_2
20: return
运行时常量池的动态扩展
编译期生成的各种字面量和符号引用是运行时常量池中比较重要的一部分来源,但是并不是全部。那么还有一种情况,可以在运行期像运行时常量池中增加常量。那就是String的intern()方法。

当一个String实例调用intern()方法时,首先会去常量池中查找是否有该字符串对应的引用, 如果有就直接返回该字符串; 如果没有, 就会在常量池中注册该字符串的引用, 然后返回该字符串。
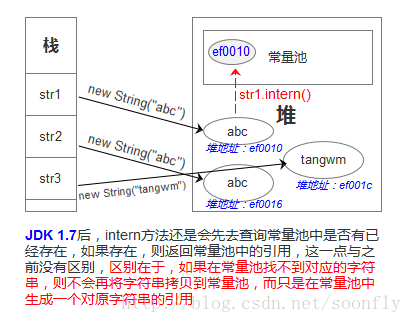
JDK 1.7后,intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。简单的说,就是往常量池放的东西变了:原来在常量池中找不到时,复制一个副本放到常量池,1.7后则是将在堆上的地址引用复制到常量池。
通过上面的分析,我们知道下面的代码返回false
String s = new String("hello");
s.intern();
String s2 = "hello";
System.out.println(s == s2);
下面的代码也返回false
String s = new String("hello");
s.intern();
String s2 = "hello";
System.out.println(s == s2);
String s = newString("hello"),生成了常量池中的“hello” 和堆空间中的字符串对象。
s.intern(),这一行的作用是s对象去常量池中寻找后发现”hello”已经存在于常量池中了。
String s2 = "hello",这行代码是生成一个s2的引用指向常量池中的“hello”对象。
结果就是 s 和 s2 的引用地址明显不同。因此返回了false。
下面的代码返回true,因为s4和s3指向了同一个地址
String s3 = new String("he") + new String("llo");
s3.intern();
String s4 = "hello";
System.out.println(s3 == s4);
在JDK 1.7下,当执行s3.intern();时,因为常量池中没有“hello”这个字符串,所以会在常量池中生成一个对堆中的“hello”的引用(注意这里是引用 ,就是这个区别于JDK 1.6的地方。在JDK1.6下是生成原字符串的拷贝),而在进行String s4= “hello”;字面量赋值的时候,常量池中已经存在一个引用,所以直接返回了该引用,因此s3和s4都指向堆中的同一个字符串,返回true。
String s3 = new String("he") + new String("llo"),这行代码在字符串常量池中生成“he” 和”llo”,并在堆空间中生成s3引用指向的对象(内容为”hello”)。注意此时常量池中是没有 “hello”对象的。
下面的代码也返回false
String s3 = new String("he") + new String("llo");
String s4 = "hello";
s3.intern();//String是不可变对象
System.out.println(s3 == s4);
将中间两行调换位置以后,因为在进行字面量赋值(String s4 = “hello″)的时候,常量池中不存在,所以s4指向的常量池中的位置,而s3指向的是堆中的对象,再进行intern方法时,对s3和s4已经没有影响了,所以返回false。
下面的代码也返回true,它会把字符串对象的引用直接返回给定义的对象。这个过程是不会在Java堆中再创建一个String对象的。
String s = new String("hello").intern();
String s2 = "hello";
System.out.println(s == s2);
上面的代码的写法其实是使用intern是没什么意义的。因为字符串hello会作为编译期常量被加载到运行时常量池。
JDK1.8基础上测试,JDK1.6的字符串常量池在方法区,肯定与堆内存中的地址不同
intern的正确用法
根据上面的分析,我们知道new String("hello").intern();里intern()是多余的,并没有起到任何作用,那它什么时候有用呢?
我们看下面的代码
String s1 = "hello";
String s2 = "world";
String s3 = s1 + s2;
String s4 = "hello" + "world";
反编译后
Constant pool:
#1 = Methodref #10.#29 // java/lang/Object."<init>":()V
#2 = String #30 // hello
#3 = String #31 // world
#4 = Class #32 // java/lang/StringBuilder
#5 = Methodref #4.#29 // java/lang/StringBuilder."<init>":()V
#6 = Methodref #4.#33 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#7 = Methodref #4.#34 // java/lang/StringBuilder.toString:()Ljava/lang/String;
#8 = String #35 // helloworld
...
{
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=5, args_size=1
0: ldc #2 // String hello
2: astore_1
3: ldc #3 // String world
5: astore_2
6: new #4 // class java/lang/StringBuilder
9: dup
10: invokespecial #5 // Method java/lang/StringBuilder."<init>":()V
13: aload_1
14: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
17: aload_2
18: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
21: invokevirtual #7 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
24: astore_3
25: ldc #8 // String helloworld
27: astore 4
29: return
...
我们可以看到s1 + s2实际上是执行的(new StringBuilder()).append(s1).append(s2).toString(),而"hello" + "world"直接在编译期就保存了常量helloworld
因为常量池要保存的是已确定的字面量值。也就是说,对于字符串的拼接,纯字面量和字面量的拼接,会把拼接结果作为常量保存到字符串池。如果在字符串拼接中,有一个参数是非字面量,而是一个变量的话,整个拼接操作会被编译成StringBuilder.append,这种情况编译器是无法知道其确定值的。只有在运行期才能确定。
基于这个特性了,intern就有用武之地了。那就是很多时候,我们在程序中得到的字符串是只有在运行期才能确定的,在编译期是无法确定的,那么也就没办法在编译期被加入到常量池中。
这时候,对于那种可能经常使用的字符串,使用intern进行定义,每次JVM运行到这段代码的时候,就会直接把常量池中该字面值的引用返回,这样就可以减少大量字符串对象的创建了。
使用参数-Xmx2048m -Xmn2048m -XX:+PrintGCDetails -XX:+HeapDumpAfterFullGC 分别执行下面代码的
static final int MAX = 1000 * 10000;
static final String[] arr = new String[MAX];
public static void main(String[] args) throws Exception {
Integer[] DB_DATA = new Integer[10];
Random random = new Random(10 * 10000);
for (int i = 0; i < DB_DATA.length; i++) {
DB_DATA[i] = random.nextInt();
}
long t = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length]));
// arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length])).intern();
}
System.out.println((System.currentTimeMillis() - t) + "ms");
System.gc();
}
arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length]));

arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length])).intern();

我们可以看到new String(String.valueOf(DB_DATA[i % DB_DATA.length]));大约生成了1KW的字符串,占用空间280M,而new String(String.valueOf(DB_DATA[i % DB_DATA.length])).intern();只生成了2K多的字符串,占用空间70K
通过上面的测试我们明确的知道,会有很多重复的相同的字符串产生,但是这些字符串的值都是只有在运行期才能确定的。所以,只能我们通过intern显示的将其加入常量池,这样可以减少很多字符串的重复创建。
观察 String Pool 的使用情况。
JVM 提供了-XX:+PrintStringTableStatistics 启动参数来帮助我们获取统计数据。只有在 JVM 退出的时候,JVM 才会将统计数据打印出来,JVM 没有提供接口给我们实时获取统计数据。
SymbolTable statistics:
Number of buckets : 20011 = 160088 bytes, avg 8.000
Number of entries : 14200 = 340800 bytes, avg 24.000
Number of literals : 14200 = 603352 bytes, avg 42.490
Total footprint : = 1104240 bytes
Average bucket size : 0.710
Variance of bucket size : 0.713
Std. dev. of bucket size: 0.844
Maximum bucket size : 6
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 1801 = 43224 bytes, avg 24.000
Number of literals : 1801 = 160528 bytes, avg 89.133
Total footprint : = 683856 bytes
Average bucket size : 0.030
Variance of bucket size : 0.030
Std. dev. of bucket size: 0.173
Maximum bucket size : 2
字符串常量池导致的YGC变长
简单记录一下,更多内容阅读你假笨的文章
从前面对intern的分析我们可以知道在StringTable上可能会存在堆内存中的对象,所以ygc过程需要对StringTable做扫描,以保证处于新生代的String代码不会被回收掉
如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降,如果链表变长,YGC过程扫描的时间也会变长
Full GC或者CMS GC过程也会对StringTable做清
参考资料
https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html
https://www.hollischuang.com/archives/2517
