1. 三种语义
- at-least-once
至少一次,有可能会有多次。如果 Producer 收到来自 Ack 的确认,则表示该消息已经写入到 Kafka 了,此时刚好是一次,也就是我们后面的 Exactly-once。
但是如果 Producer 超时或收到错误,并且 request.required.acks 配置的不是 -1,则会重试发送消息,客户端会认为该消息未写入 Kafka。
如果 Broker 在发送 Ack 之前失败,但在消息成功写入 Kafka 之后,这一次重试将会导致我们的消息会被写入两次。
所以消息就不止一次地传递给最终 Consumer,如果 Consumer 处理逻辑没有保证幂等的话就会得到不正确的结果。
在这种语义中会出现乱序,也就是当第一次 Ack 失败准备重试的时候,但是第二消息已经发送过去了,这个时候会出现单分区中乱序的现象。
我们需要设置Prouducer 的参数 max.in.flight.requests.per.connection,flight.requests 是
Producer 端用来保存发送请求且没有响应的队列,保证 Producer端未响应的请求个数为 1。
- at-most-once
如果在 Ack 超时或返回错误时 Producer 不重试,也就是我们讲 request.required.acks = -1,则该消息可能最终没有写入 Kafka,所以 Consumer 不会接收消息。
- exactly-once
刚好一次,即使 Producer 重试发送消息,消息也会保证最多一次地传递给 Consumer。该语义是最理想的,也是最难实现的。
在 0.10 之前并不能保证 exactly-once,需要使用 Consumer 自带的幂等性保证。0.11.0 使用事务保证了。
2. 如何实现 exactly-once
要实现 exactly-once 在 Kafka 0.11.0 中有两个官方策略:
2.1. 单 Producer 单 Topic
每个 Producer 在初始化的时候都会被分配一个唯一的 PID,对于每个唯一的 PID,Producer 向指定的 Topic 中某个特定的 Partition 发送的消息都会携带一个从 0 单调递增的 Sequence Number。
在我们的 Broker 端也会维护一个维度为,每次提交一次消息的时候都会对齐进行校验:
- 如果消息序号比 Broker 维护的序号大一以上,说明中间有数据尚未写入,也即乱序,此时 Broker 拒绝该消息,Producer 抛出 InvalidSequenceNumber。
- 如果消息序号小于等于 Broker 维护的序号,说明该消息已被保存,即为重复消息,Broker 直接丢弃该消息,Producer 抛出 DuplicateSequenceNumber。
- 如果消息序号刚好大一,就证明是合法的。
上面所说的解决了两个问题:
- 当 Prouducer 发送了一条消息之后失败,Broker 并没有保存,但是第二条消息却发送成功,造成了数据的乱序。
- 当 Producer 发送了一条消息之后,Broker 保存成功,Ack 回传失败,Producer 再次投递重复的消息。
上面所说的都是在同一个 PID 下面,意味着必须保证在单个 Producer 中的同一个 Seesion 内,如果 Producer 挂了,被分配了新的 PID,这样就无法保证了,所以 Kafka 中又有事务机制去保证。
2.2. 事务
在 Kafka 中事务的作用是:
- 实现 exactly-once 语义。
- 保证操作的原子性,要么全部成功,要么全部失败。
- 有状态的操作的恢复。
事务可以保证就算跨多个,在本次事务中的对消费队列的操作都当成原子性,要么全部成功,要么全部失败。并且,有状态的应用也可以保证重启后从断点处继续处理,也即事务恢复。
在 Kafka 的事务中,应用程序必须提供一个唯一的事务 ID,即 Transaction ID,并且宕机重启之后,也不会发生改变。
Transactin ID 与 PID 可能一一对应,区别在于 Transaction ID 由用户提供,而 PID 是内部的实现对用户透明。
为了 Producer 重启之后,旧的 Producer 具有相同的 Transaction ID 失效,每次 Producer 通过 Transaction ID 拿到 PID 的同时,还会获取一个单调递增的 Epoch。
由于旧的 Producer 的 Epoch 比新 Producer 的 Epoch 小,Kafka 可以很容易识别出该 Producer 是老的,Producer 并拒绝其请求。
为了实现这一点,Kafka 0.11.0.0 引入了一个服务器端的模块,名为 Transaction Coordinator,用于管理 Producer 发送的消息的事务性。
该 Transaction Coordinator 维护 Transaction Log,该 Log 存于一个内部的 Topic 内。
由于 Topic 数据具有持久性,因此事务的状态也具有持久性。Producer 并不直接读写 Transaction Log,它与 Transaction Coordinator 通信,然后由 Transaction Coordinator 将该事务的状态插入相应的 Transaction Log。
Transaction Log 的设计与 Offset Log 用于保存 Consumer 的 Offset 类似。
3. 幂等性 Producer
在 Kafka 中,Producer 默认不是幂等性的,但我们可以创建幂等性 Producer。它其实是 0.11.0.0 版本引入的新功能。在此之前,Kafka 向分区发送数据时,可能会出现同一条消息被发送了多次,导致消息重复的情况。在 0.11 之后,指定 Producer 幂等性的方法很简单,仅需要设置一个参数即可,即 props.put(“enable.idempotence”, ture)。
enable.idempotence 被设置成 true 后,Producer 自动升级成幂等性 Producer,其他所有的代码逻辑都不需要改变。Kafka 自动帮你做消息的重复去重。底层具体的原理很简单,就是经典的用空间去换时间的优化思路,即在 Broker 端多保存一些字段。当 Producer 发送了具有相同字段值的消息后,Broker 能够自动知晓这些消息已经重复了,于是可以在后台默默地把它们“丢弃”掉。当然,实际的实现原理并没有这么简单,但你大致可以这么理解。
看上去,幂等性 Producer 的功能很酷,使用起来也很简单,仅仅设置一个参数就能保证消息不重复了,但实际上,我们必须要了解幂等性 Producer 的作用范围。首先,它只能保证单分区上的幂等性,即一个幂等性 Producer 能够保证某个主题的一个分区上不出现重复消息,它无法实现多个分区的幂等性。其次,它只能实现单会话上的幂等性,不能实现跨会话的幂等性。这里的会话,你可以理解为 Producer 进程的一次运行。当你重启了 Producer 进程之后,这种幂等性保证就丧失了。
4. 事务
事务型 Producer 能够保证将消息原子性地写入到多个分区中。这批消息要么全部写入成功,要么全部失败。另外,事务型 Producer 也不惧进程的重启。Producer 重启回来后,Kafka 依然保证它们发送消息的精确一次处理。
设置事务型 Producer 的方法也很简单,满足两个要求即可:
- 和幂等性 Producer 一样,开启
enable.idempotence = true。 - 设置 Producer 端参数 transactional. id。最好为其设置一个有意义的名字
此外,你还需要在 Producer 代码中做一些调整,如这段代码所示:
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch (KafkaException e) {
producer.abortTransaction();
}
和普通 Producer 代码相比,事务型 Producer 的显著特点是调用了一些事务 API,如 initTransaction、beginTransaction、commitTransaction 和 abortTransaction,它们分别对应事务的初始化、事务开始、事务提交以及事务终止。
段代码能够保证 Record1 和 Record2 被当作一个事务统一提交到 Kafka,要么它们全部提交成功,要么全部写入失败。实际上即使写入失败,Kafka 也会把它们写入到底层的日志中,也就是说 Consumer 还是会看到这些消息。因此在 Consumer 端,读取事务型 Producer 发送的消息也是需要一些变更的。修改起来也很简单,设置 isolation.level 参数的值即可。当前这个参数有两个取值:
- read_uncommitted:这是默认值,表明 Consumer 能够读取到 Kafka 写入的任何消息,不论事务型 Producer 提交事务还是终止事务,其写入的消息都可以读取。很显然,如果你用了事务型 Producer,那么对应的 Consumer 就不要使用这个值。
- read_committed:表明 Consumer 只会读取事务型 Producer 成功提交事务写入的消息。当然了,它也能看到非事务型 Producer 写入的所有消息。
事务的基本思路是这样的:
-
引入 Tid(transaction id),和 Pid 不同,这个 ID 是应用程序提供的,用于标识事务,和 Producer 是谁并没关系。
就是任何 Producer 都可以使用这个 Tid 去做事务,这样进行到一半就死掉的事务,可以由另一个 Producer 去恢复。
-
同时为了记录事务的状态,类似对 Offset 的处理,引入 Transaction Coordinator 用于记录 Transaction Log。
在集群中会有多个 Transaction Coordinator,每个 Tid 对应唯一一个 Transaction Coordinator。
注:Transaction Log 删除策略是 Compact,已完成的事务会标记成 Null,Compact 后不保留。
做事务时,先标记开启事务,写入数据,全部成功就在 Transaction Log 中记录为 Prepare Commit 状态,否则写入 Prepare Abort 的状态。
之后再去给每个相关的 Partition 写入一条 Marker(Commit 或者 Abort)消息,标记这个事务的 Message 可以被读取或已经废弃。
成功后在 Transaction Log记录下 Commit/Abort 状态,至此事务结束。
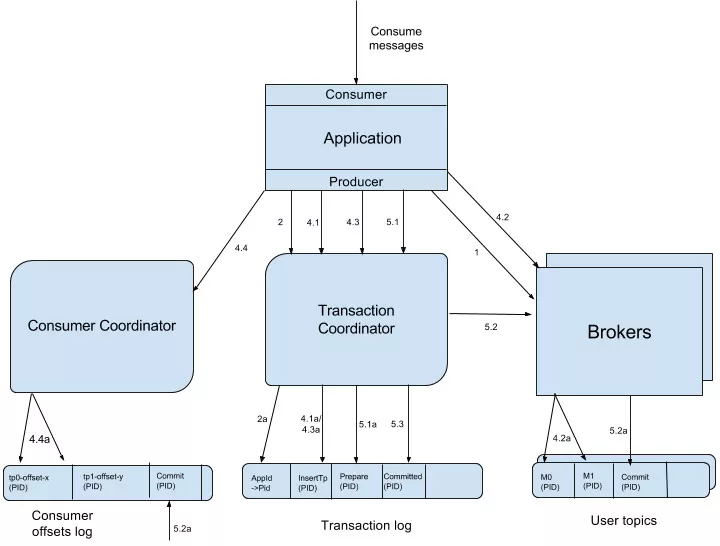
数据流:
-
首先使用 Tid 请求任意一个 Broker(代码中写的是负载最小的 Broker),找到对应的 Transaction Coordinator。
-
请求 Transaction Coordinator 获取到对应的 Pid,和 Pid 对应的 Epoch,这个 Epoch 用于防止僵死进程复活导致消息错乱。
当消息的 Epoch 比当前维护的 Epoch 小时,拒绝掉。Tid 和 Pid 有一一对应的关系,这样对于同一个 Tid 会返回相同的 Pid。
-
Client 先请求 Transaction Coordinator 记录的事务状态,初始状态是 Begin,如果是该事务中第一个到达的,同时会对事务进行计时。
Client 输出数据到相关的 Partition 中;Client 再请求 Transaction Coordinator 记录 Offset 的事务状态;Client 发送 Offset Commit 到对应 Offset Partition。
-
Client 发送 Commit 请求,Transaction Coordinator 记录 Prepare Commit/Abort,然后发送 Marker 给相关的 Partition。
全部成功后,记录 Commit/Abort 的状态,最后这个记录不需要等待其他 Replica 的 ACK,因为 Prepare 不丢就能保证最终的正确性了。
这里 Prepare 的状态主要是用于事务恢复,例如给相关的 Partition 发送控制消息,没发完就宕机了,备机起来后,Producer 发送请求获取 Pid 时,会把未完成的事务接着完成。
当 Partition 中写入 Commit 的 Marker 后,相关的消息就可被读取。所以 Kafka 事务在 Prepare Commit 到 Commit 这个时间段内,消息是逐渐可见的,而不是同一时刻可见。
消费时,Partition 中会存在一些消息处于未 Commit 状态,即业务方应该看不到的消息,需要过滤这些消息不让业务看到,Kafka 选择在消费者进程中进行过来,而不是在 Broker 中过滤,主要考虑的还是性能。
Kafka 高性能的一个关键点是 Zero Copy,如果需要在 Broker 中过滤,那么势必需要读取消息内容到内存,就会失去 Zero Copy 的特性。
5. 参考资料
《Kafka核心技术与实战》
https://mp.weixin.qq.com/s/xdHYG5nLf9SkjOj-3hUKrg
