还没有时间测试,直接复制的参考资料
1. Producer Only
1.1. Producer Number VS. Throughput
实验条件:3个Broker,1个Topic,6个Partition,无Replication,异步模式,消息Payload为100字节
测试项目:分别测试1,2,3个Producer时的吞吐量
测试目标:多个Producer可同时向同一个Topic发送数据,在Broker负载饱和前,理论上Producer数量越多,集群每秒收到的消息量越大,并且呈线性增涨。本实验主要验证该特性。同时作为性能测试,本实验还将监控测试过程中单个Broker的CPU和内存使用情况
测试结果:使用不同个数Producer时的总吞吐率如下图所示
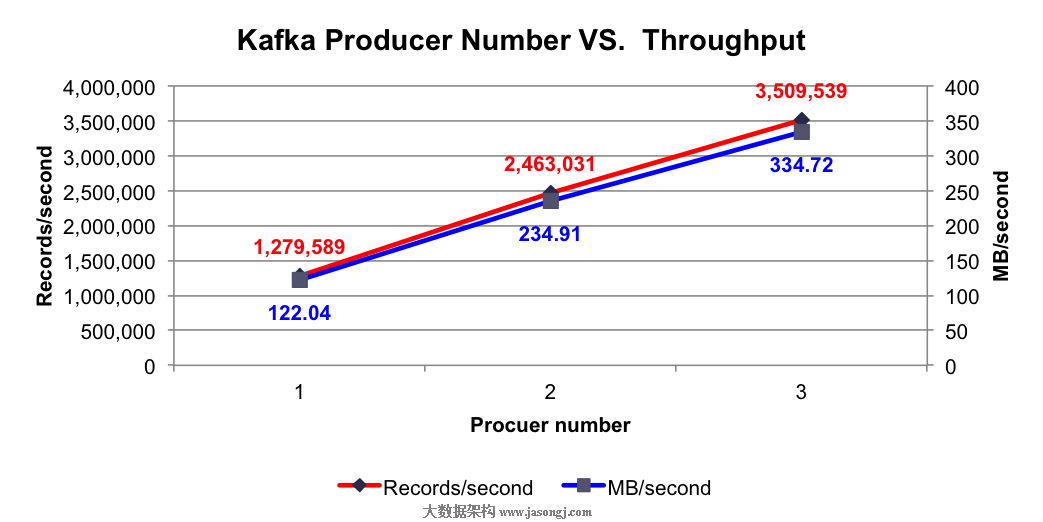
由上图可看出,单个Producer每秒可成功发送约128万条Payload为100字节的消息,并且随着Producer个数的提升,每秒总共发送的消息量线性提升,符合之前的分析。
1.2. Message Size VS. Throughput
实验条件:3个Broker,1个Topic,6个Partition,无Replication,异步模式,3个Producer
测试项目:分别测试消息长度为10,20,40,60,80,100,150,200,400,800,1000,2000,5000,10000字节时的集群总吞吐量
测试结果:不同消息长度时的集群总吞吐率如下图所示
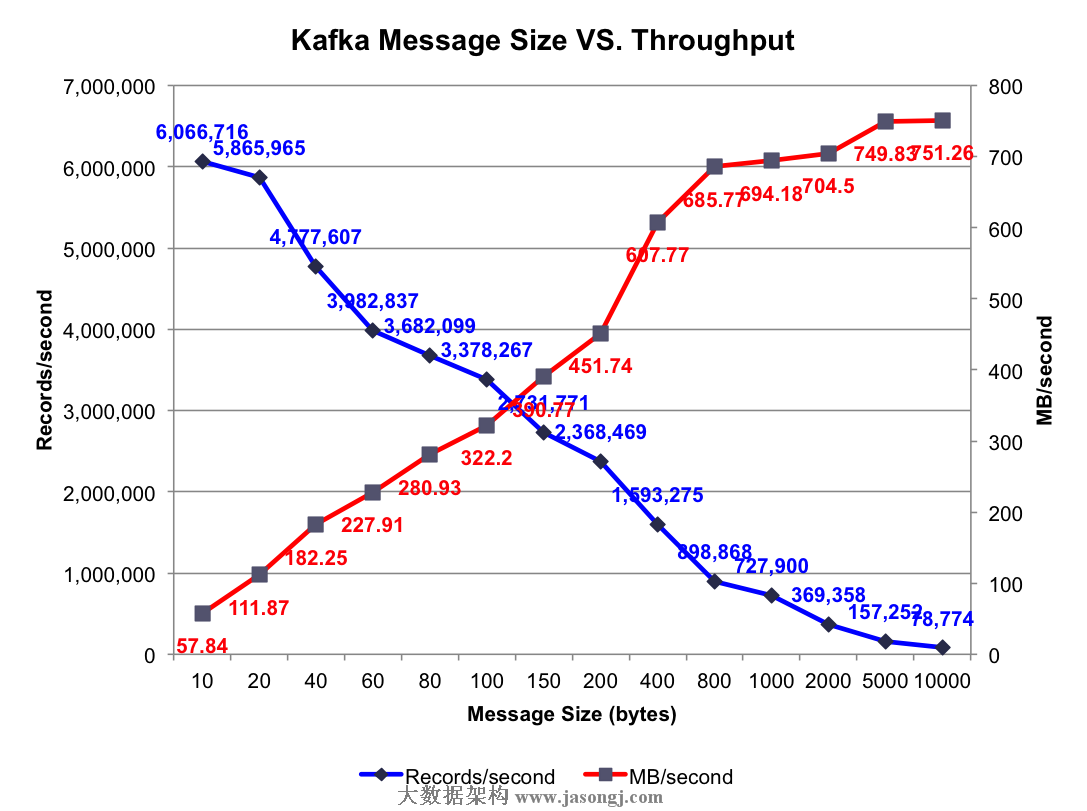
每秒所能发送的消息数越少,而每秒所能发送的消息的量(MB)越大。另外,每条消息除了Payload外,还包含其它Metadata,所以每秒所发送的消息量比每秒发送的消息数乘以100字节大,而Payload越大,这些Metadata占比越小,同时发送时的批量发送的消息体积越大,越容易得到更高的每秒消息量(MB/s)。其它测试中使用的Payload为100字节,之所以使用这种短消息(相对短)只是为了测试相对比较差的情况下的Kafka吞吐率。
1.3. Partition Number VS. Throughput
实验条件:3个Broker,1个Topic,无Replication,异步模式,3个Producer,消息Payload为100字节
测试项目:分别测试1到9个Partition时的吞吐量
测试结果:不同Partition数量时的集群总吞吐率如下图所示
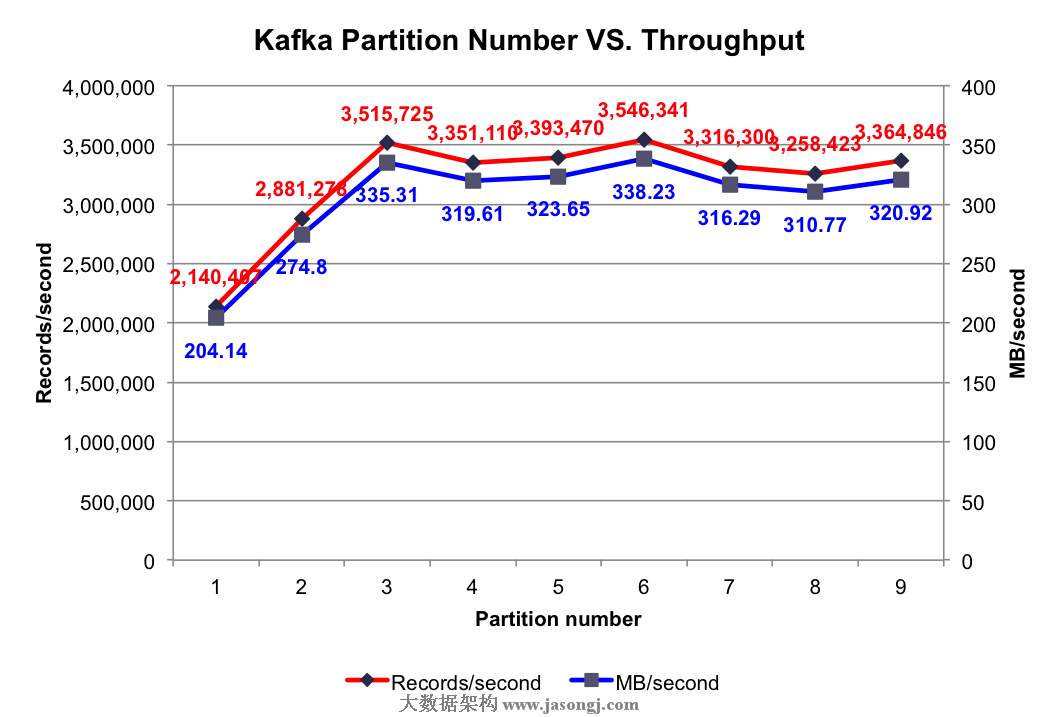
由上图可知,当Partition数量小于Broker个数(3个)时,Partition数量越大,吞吐率越高,且呈线性提升。本文所有实验中,只启动3个Broker,而一个Partition只能存在于1个Broker上(不考虑Replication。即使有Replication,也只有其Leader接受读写请求),故当某个Topic只包含1个Partition时,实际只有1个Broker在为该Topic工作。如之前文章所讲,Kafka会将所有Partition均匀分布到所有Broker上,所以当只有2个Partition时,会有2个Broker为该Topic服务。3个Partition时同理会有3个Broker为该Topic服务。换言之,Partition数量小于等于3个时,越多的Partition代表越多的Broker为该Topic服务。如前几篇文章所述,不同Broker上的数据并行插入,这就解释了当Partition数量小于等于3个时,吞吐率随Partition数量的增加线性提升。
当Partition数量多于Broker个数时,总吞吐量并未有所提升,甚至还有所下降。可能的原因是,当Partition数量为4和5时,不同Broker上的Partition数量不同,而Producer会将数据均匀发送到各Partition上,这就造成各Broker的负载不同,不能最大化集群吞吐量。而上图中当Partition数量为Broker数量整数倍时吞吐量明显比其它情况高,也证实了这一点。
1.4. Replica Number VS. Throughput
实验条件:3个Broker,1个Topic,6个Partition,异步模式,3个Producer,消息Payload为100字节
测试项目:分别测试1到3个Replica时的吞吐率
测试结果:如下图所示
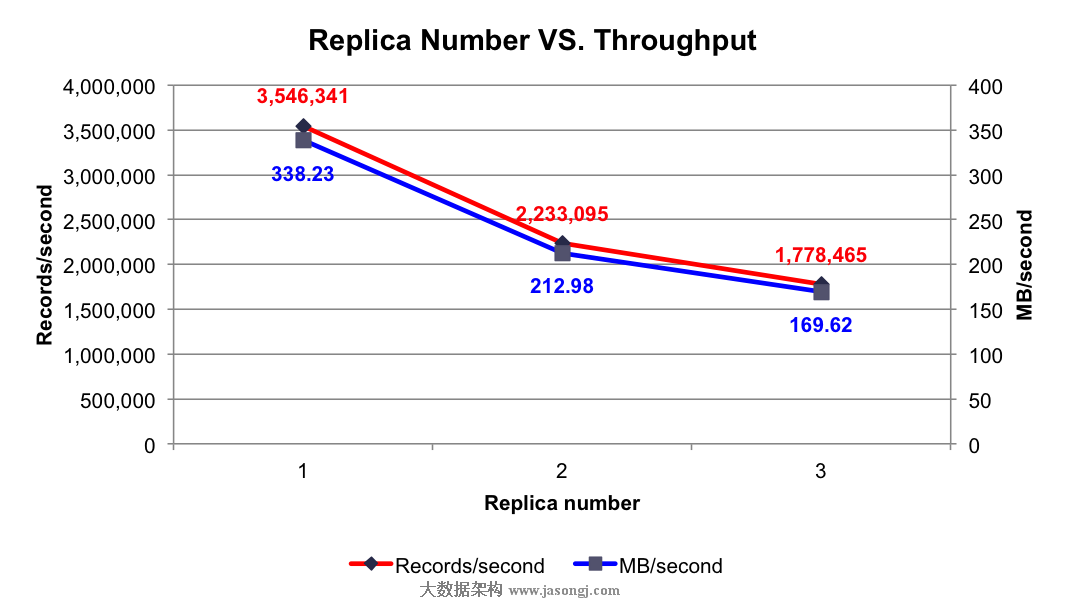
由上图可知,随着Replica数量的增加,吞吐率随之下降。但吞吐率的下降并非线性下降,因为多个Follower的数据复制是并行进行的,而非串行进行。
2. Consumer Only
实验条件:3个Broker,1个Topic,6个Partition,无Replication,异步模式,消息Payload为100字节
测试项目:分别测试1到3个Consumer时的集群总吞吐率
测试结果:在集群中已有大量消息的情况下,使用1到3个Consumer时的集群总吞吐量如下图所示
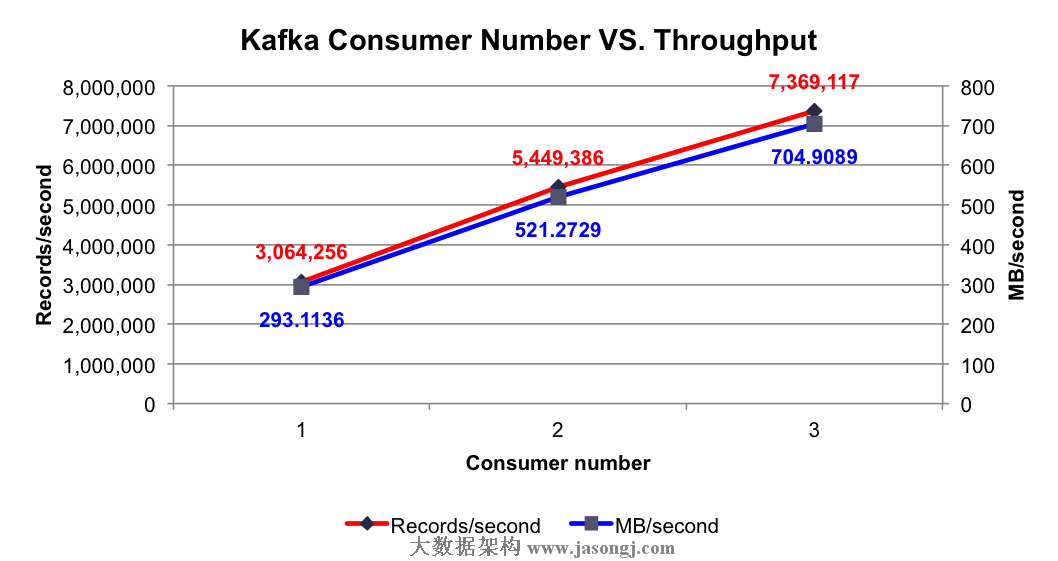
由上图可知,单个Consumer每秒可消费306万条消息,该数量远大于单个Producer每秒可消费的消息数量,这保证了在合理的配置下,消息可被及时处理。并且随着Consumer数量的增加,集群总吞吐量线性增加。
多Consumer消费消息时以Partition为分配单位,当只有1个Consumer时,该Consumer需要同时从6个Partition拉取消息,该Consumer所在机器的I/O成为整个消费过程的瓶颈,而当Consumer个数增加至2个至3个时,多个Consumer同时从集群拉取消息,充分利用了集群的吞吐率。
3. 参考资料
http://www.jasongj.com/2015/12/31/KafkaColumn5_kafka_benchmark/
