1. 消费者组
在Kafka中,每个消费者都有一个对应的消费组。当消息发布到主题后,只会被投递给订阅它的每个消费组中的一个消费者。每个消费者只能消费所分配到的分区中的消息。而每一个分区只能被一个消费组中的一个消费者所消费。
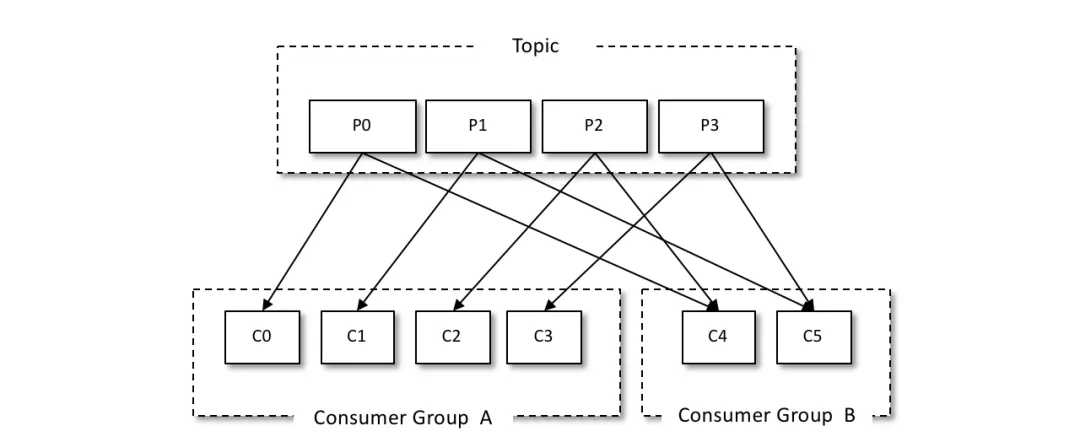
如上图所示,我们可以设置两个消费者组来实现广播消息的作用,消费组A和组B都可以接受到生产者发送过来的消息。
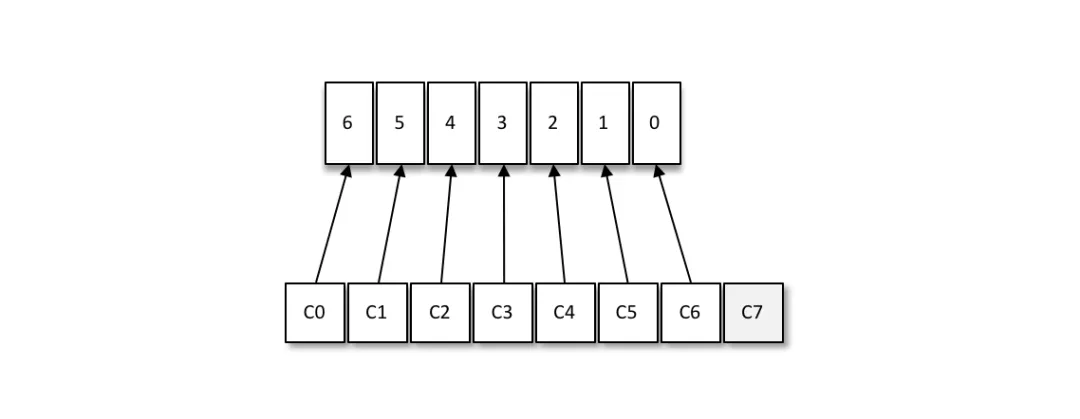
消费者与消费组这种模型可以让整体的消费能力具备横向伸缩性,我们可以增加(或减少)消费者的个数来提高(或降低)整体的消费能力。对于分区数固定的情况,一味地增加消费者并不会让消费能力一直得到提升,如果消费者过多,出现了消费者的个数大于分区个数的情况,就会有消费者分配不到任何分区。
如下:一共有8个消费者,7个分区,那么最后的消费者C7由于分配不到任何分区而无法消费任何消息。
2. 消费端分区分配策略
Kafka 提供了消费者客户端参数 partition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略。
2.1. RangeAssignor分配策略
默认情况下,采用 RangeAssignor 分配策略。
RangeAssignor 分配策略的原理是按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。对于每一个主题,RangeAssignor 策略会将消费组内所有订阅这个主题的消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
通过下面公式更直观:
假设n = 分区数 / 消费者数量,m = 分区数 % 消费者线程数量,那么前m个消费者每个分配n+1个分区,后面的(消费者线程数量 - m)个消费者每个分配n个分区。
假设消费组内有2个消费者 C0 和 C1,都订阅了主题 t0 和 t1,并且每个主题都有4个分区,那么订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t0p3、t1p0、t1p1、t1p2、t1p3。最终的分配结果为:
消费者C0:t0p0、t0p1、t1p0、t1p1
消费者C1:t0p2、t0p3、t1p2、t1p3
假设上面例子中2个主题都只有3个分区,那么订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终的分配结果为:
消费者C0:t0p0、t0p1、t1p0、t1p1
消费者C1:t0p2、t1p2
可以明显地看到这样的分配并不均匀。
2.2. RoundRobinAssignor分配策略
RoundRobinAssignor 分配策略的原理是将消费组内所有消费者及消费者订阅的所有主题的分区按照字典序排序,然后通过轮询方式逐个将分区依次分配给每个消费者。
如果同一个消费组内所有的消费者的订阅信息都是相同的,那么 RoundRobinAssignor 分配策略的分区分配会是均匀的。
如果同一个消费组内的消费者订阅的信息是不相同的,那么在执行分区分配的时候就不是完全的轮询分配,有可能导致分区分配得不均匀。
假设消费组内有3个消费者(C0、C1 和 C2),t0、t1、t2主题分别有1、2、3个分区,即整个消费组订阅了 t0p0、t1p0、t1p1、t2p0、t2p1、t2p2 这6个分区。
具体而言,消费者 C0 订阅的是主题 t0,消费者 C1 订阅的是主题 t0 和 t1,消费者 C2 订阅的是主题 t0、t1 和 t2,那么最终的分配结果为:
消费者C0:t0p0
消费者C1:t1p0
消费者C2:t1p1、t2p0、t2p1、t2p2
可以看 到 RoundRobinAssignor 策略也不是十分完美,这样分配其实并不是最优解,因为完全可以将分区 t1p1 分配给消费者 C1。
2.3. StickyAssignor分配策略
这种分配策略,它主要有两个目的:
- 分区的分配要尽可能均匀。
- 分区的分配尽可能与上次分配的保持相同。
假设消费组内有3个消费者(C0、C1 和 C2),它们都订阅了4个主题(t0、t1、t2、t3),并且每个主题有2个分区。也就是说,整个消费组订阅了 t0p0、t0p1、t1p0、t1p1、t2p0、t2p1、t3p0、t3p1 这8个分区。最终的分配结果如下:
消费者C0:t0p0、t1p1、t3p0
消费者C1:t0p1、t2p0、t3p1
消费者C2:t1p0、t2p1
再假设此时消费者 C1 脱离了消费组,那么分配结果为:
消费者C0:t0p0、t1p1、t3p0、t2p0
消费者C2:t1p0、t2p1、t0p1、t3p1
StickyAssignor 分配策略如同其名称中的“sticky”一样,让分配策略具备一定的“黏性”,尽可能地让前后两次分配相同,进而减少系统资源的损耗及其他异常情况的发生。
3. 再均衡(Rebalance)
再均衡是指分区的所属权从一个消费者转移到另一消费者的行为,它为消费组具备高可用性和伸缩性提供保障,使我们可以既方便又安全地删除消费组内的消费者或往消费组内添加消费者。
弊端:
- 在再均衡发生期间,消费组内的消费者是无法读取消息的。
- Rebalance 很慢。如果一个消费者组里面有几百个 Consumer 实例,Rebalance 一次要几个小时。
- 在进行再均衡的时候消费者当前的状态也会丢失。比如消费者消费完某个分区中的一部分消息时还没有来得及提交消费位移就发生了再均衡操作,之后这个分区又被分配给了消费组内的另一个消费者,原来被消费完的那部分消息又被重新消费一遍,也就是发生了重复消费。
Rebalance 发生的时机有三个:
- 组成员数量发生变化
- 订阅主题数量发生变化
- 订阅主题的分区数发生变化
后两类通常是业务的变动调整所导致的,我们一般不可控制,我们主要说说因为组成员数量变化而引发的 Rebalance 该如何避免。
3.1. 如何避免组成员数量变化而引发的 Rebalance
当 Consumer Group 完成 Rebalance 之后,每个 Consumer 实例都会定期地向 Coordinator 发送心跳请求,表明它还存活着。如果某个 Consumer 实例不能及时地发送这些心跳请求,Coordinator 就会认为该 Consumer 已经“死”了,从而将其从 Group 中移除,然后开启新一轮 Rebalance。
Consumer端可以设置session.timeout.ms,默认是10s,表示如果 Coordinator 在 10 秒之内没有收到 Group 下某 Consumer 实例的心跳,它就会认为这个 Consumer 实例已经挂了。
Consumer端还可以设置heartbeat.interval.ms,表示发送心跳请求的频率。
以及max.poll.interval.ms 参数,它限定了 Consumer 端应用程序两次调用 poll 方法的最大时间间隔。它的默认值是 5 分钟,表示你的 Consumer 程序如果在 5 分钟之内无法消费完 poll 方法返回的消息,那么 Consumer 会主动发起“离开组”的请求,Coordinator 也会开启新一轮 Rebalance。
所以知道了上面几个参数后,我们就可以避免以下两个问题:
-
非必要 Rebalance 是因为未能及时发送心跳,导致 Consumer 被“踢出”Group 而引发的。 所以我们在生产环境中可以这么设置:
-
- 设置 session.timeout.ms = 6s。
- 设置 heartbeat.interval.ms = 2s。
- 要保证 Consumer 实例在被判定为“dead”之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。
-
必要 Rebalance 是 Consumer 消费时间过长导致的。如何消费任务时间达到8分钟,而max.poll.interval.ms设置为5分钟,那么也会发生Rebalance,所以如果有比较重的任务的话,可以适当调整这个参数。
- Consumer 端的频繁的 Full GC导致的长时间停顿,从而引发了 Rebalance。
3.2. 消费者组再平衡全流程
重平衡过程是靠消费者端的心跳线程(Heartbeat Thread),通知到其他消费者实例的。
当协调者决定开启新一轮重平衡后,它会将“REBALANCE_IN_PROGRESS”封装进心跳请求的响应中,发还给消费者实例。当消费者实例发现心跳响应中包含了“REBALANCE_IN_PROGRESS”,就能立马知道重平衡又开始了,这就是重平衡的通知机制。
所以,实际上heartbeat.interval.ms不止是设置了心跳的间隔时间,还可以控制重平衡通知的频率。
消费者组状态机
重平衡一旦开启,Broker 端的协调者组件就要完成整个重平衡流程,Kafka 设计了一套消费者组状态机(State Machine)来实现。
Kafka 为消费者组定义了 5 种状态,它们分别是:Empty、Dead、PreparingRebalance、CompletingRebalance 和 Stable。
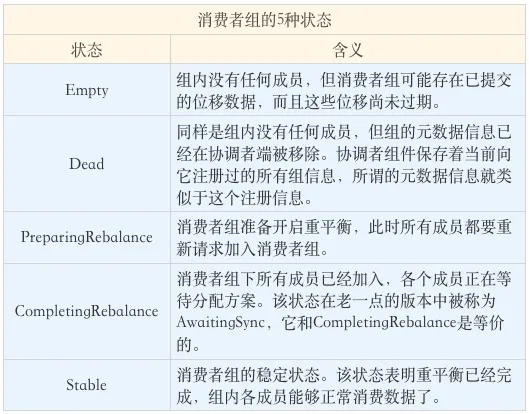
状态机的各个状态流转:
当有新成员加入或已有成员退出时,消费者组的状态从 Stable 直接跳到 PreparingRebalance 状态,此时,所有现存成员就必须重新申请加入组。当所有成员都退出组后,消费者组状态变更为 Empty。Kafka 定期自动删除过期位移的条件就是,组要处于 Empty 状态。因此,如果你的消费者组停掉了很长时间(超过 7 天),那么 Kafka 很可能就把该组的位移数据删除了。
组协调器(GroupCoordinator)
GroupCoordinator 是 Kafka 服务端中用于管理消费组的组件。它专门为 Consumer Group 服务,负责为 Group 执行 Rebalance 以及提供位移管理和组成员管理等。
具体来讲,Consumer 端应用程序在提交位移时,其实是向 Coordinator 所在的 Broker 提交位移。同样地,当 Consumer 应用启动时,也是向 Coordinator 所在的 Broker 发送各种请求,然后由 Coordinator 负责执行消费者组的注册、成员管理记录等元数据管理操作。
所有 Broker 在启动时,都会创建和开启相应的 Coordinator 组件。也就是说,所有 Broker 都有各自的 Coordinator 组件。那么,Consumer Group 如何确定为它服务的 Coordinator 在哪台 Broker 上呢?答案就是 Kafka 内部位移主题 __consumer_offsets 。
__consumer_offsets 是 Kafka 内部使用的一个 topic,专门用来存储 group 消费的情况,默认情况下有50个 partition,每个 partition 三副本
目前,Kafka 为某个 Consumer Group 确定 Coordinator 所在的 Broker 的算法有 2 个步骤。
- 第 1 步:确定由位移主题的哪个分区来保存该 Group 数据:partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount)。
- 第 2 步:找出该分区 Leader 副本所在的 Broker,该 Broker 即为对应的 Coordinator。
简单解释一下上面的算法。首先,Kafka 会计算该 Group 的 group.id 参数的哈希值。比如你有个 Group 的 group.id 设置成了“test-group”,那么它的 hashCode 值就应该是 627841412。其次,Kafka 会计算 __consumer_offsets 的分区数,通常是 50 个分区,之后将刚才那个哈希值对分区数进行取模加求绝对值计算,即 abs(627841412 % 50) = 12。此时,我们就知道了位移主题的分区 12 负责保存这个 Group 的数据。有了分区号,算法的第 2 步就变得很简单了,我们只需要找出位移主题分区 12 的 Leader 副本在哪个 Broker 上就可以了。这个 Broker,就是我们要找的 Coordinator。在实际使用过程中,Consumer 应用程序,特别是 Java Consumer API,能够自动发现并连接正确的 Coordinator,我们不用操心这个问题。知晓这个算法的最大意义在于,它能够帮助我们解决定位问题。当 Consumer Group 出现问题,需要快速排查 Broker 端日志时,我们能够根据这个算法准确定位 Coordinator 对应的 Broker,不必一台 Broker 一台 Broker 地盲查。
消费者端重平衡流程
在消费者端,重平衡分为两个步骤:分别是加入组和等待领导者消费者(Leader Consumer)分配方案。即JoinGroup 请求和 SyncGroup 请求。
- 加入组:当组内成员加入组时,它会向协调器发送 JoinGroup 请求。在该请求中,每个成员都要将自己订阅的主题上报,这样协调器就能收集到所有成员的订阅信息。
- 选择消费组领导者:一旦收集了全部成员的 JoinGroup 请求后,协调者会从这些成员中选择一个担任这个消费者组的领导者。 这里的领导者是具体的消费者实例,它既不是副本,也不是协调器。领导者消费者的任务是收集所有成员的订阅信息,然后根据这些信息,制定具体的分区消费分配方案。选择的算法是随机选择
- 选举分区分配策略:这个分区分配的选举是根据消费组内的各个消费者投票来决定的。协调器会收集各个消费者支持的所有分配策略,组成候选集 candidates。每个消费者从候选集 candidates 中找出第一个自身支持的策略,为这个策略投上一票。计算候选集中各个策略的选票数,选票数最多的策略即为当前消费组的分配策略。如果有消费者并不支持选出的分配策略,那么就会报出异常 IllegalArgumentException:Member does not support protocol。
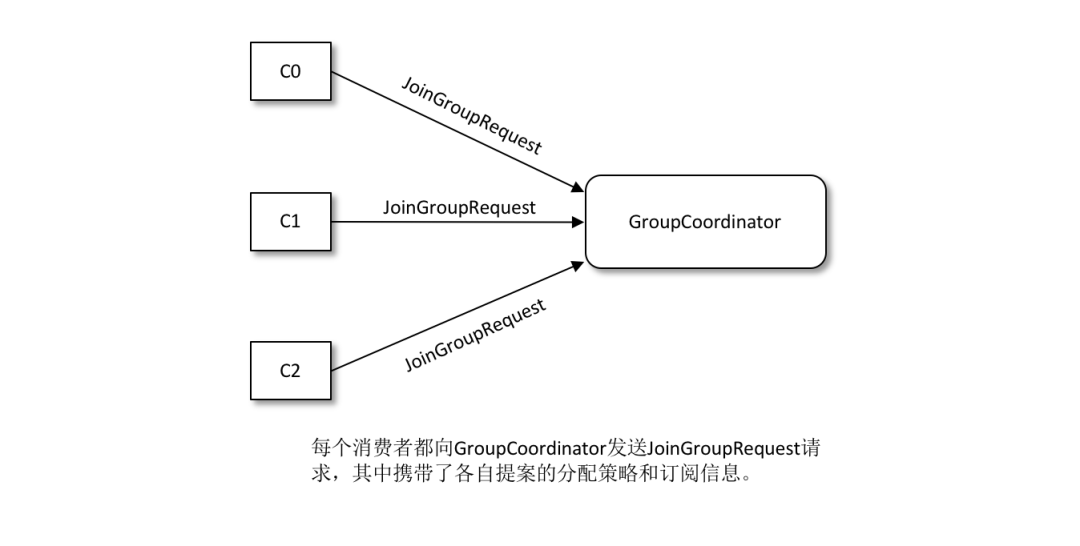
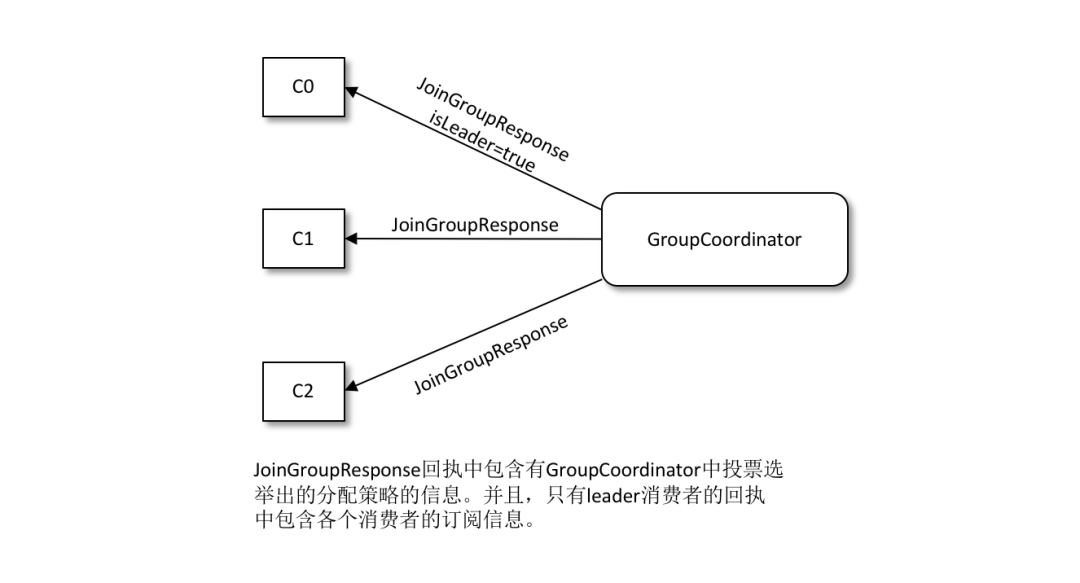
- 发送 SyncGroup 请求:协调器会把消费者组订阅信息封装进 JoinGroup 请求的响应体中,然后发给领导者,由领导者统一做出分配方案,然后领导者发送 SyncGroup 请求给协调器。

- 响应SyncGroup:组内所有的消费者都会发送一个 SyncGroup 请求,只不过不是领导者的请求内容为空,然后就会接收到一个SyncGroup响应,接受订阅信息。
Leader Consumer负责组内各个Consumer的partition分配,除此之外Leader Consumer还负责整个消费组订阅的主题的监控,Leader Consumer会定期更新消费组订阅的主题信息,一旦发现主题信息发生了变化,Leader Consumer会通知Coordinator触发Rebalance机制。
3. 参考资料
https://mp.weixin.qq.com/s/C6dfvzFkNDYgiNeZ4eWPBQ
