控制器组件(Controller),是 Apache Kafka 的核心组件。它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。集群中任意一台 Broker 都能充当控制器的角色,但是,在运行过程中,只能有一个 Broker 成为控制器,行使其管理和协调的职责
1. Controller Broker
在分布式系统中,通常需要有一个协调者,该协调者会在分布式系统发生异常时发挥特殊的作用。在Kafka中该协调者称之为控制器(Controller),其实该控制器并没有什么特殊之处,它本身也是一个普通的Broker,只不过需要负责一些额外的工作(追踪集群中的其他Broker,并在合适的时候处理新加入的和失败的Broker节点、Rebalance分区、分配新的leader分区等)。值得注意的是:Kafka集群中始终只有一个Controller Broker。
2. 控制器是如何被选出来的?
Broker 在启动时,会尝试去 ZooKeeper 中创建 /controller 节点。Kafka 当前选举控制器的规则是:第一个成功创建 /controller 节点的 Broker 会被指定为控制器。
一般而言,Kafka集群中第一台启动的Broker会成为Controller,并将自身Broker编号等信息写入ZooKeeper临时节点/controller。
get /controller
{"version":1,"brokerid":0,"timestamp":"1611819140932"}
其中version固定为1,brokerid表示成为Broker编号,timestamp表示成为Controller的时间戳。
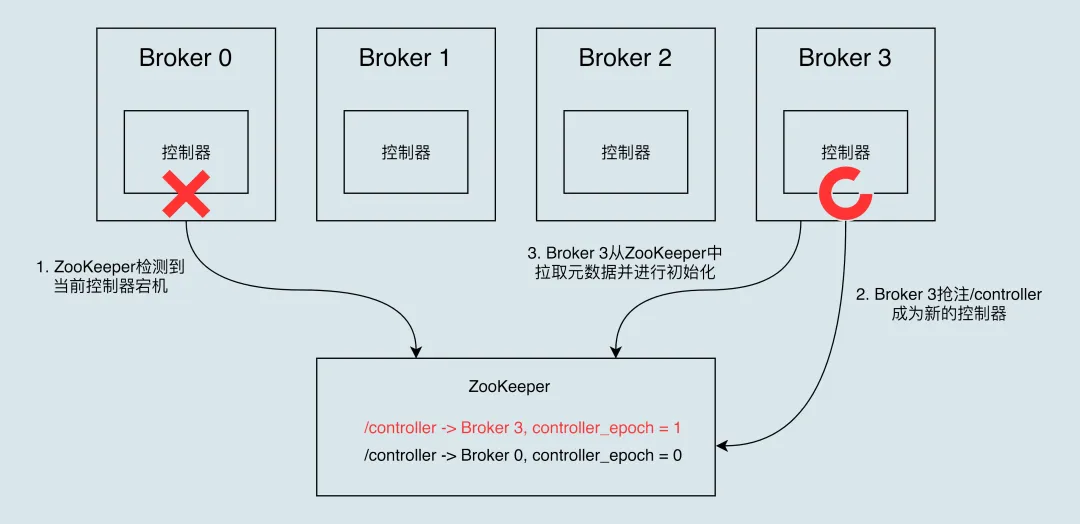
在任意时刻,Kafka集群中有且只有一台Controller,每个Broker启动的时候都会去尝试读取ZooKeeper临时节点/controller的brokerid,如果读取到brokerid不为-1,则表示已有Broker竞选成为Controller。此时,当前Broker会放弃竞选Controller,并对ZooKeeper临时节点/controller注册监听器,当Controller因为某些情况导致Kafka进程停止,甚至所在的机器宕机,在规定的时间内没有发送心跳到ZooKeeper,此时ZooKeeper会将临时节点/controller删除,然后监听器会通知各个Broker进行Controller选举,第一个创建ZooKeeper临时节点/controller被认为抢占成功,成为新的Controller。
在ZooKeeper中的 /controller_epoch 节点中存放的是一个整型的 controller_epoch 值。controller_epoch 用于记录控制器发生变更的次数,即记录当前的控制器是第几代控制器,我们也可以称之为“控制器的纪元”。
controller_epoch 的初始值为1,即集群中第一个控制器的纪元为1,当控制器发生变更时,每选出一个新的控制器就将该字段值加1。Kafka 通过 controller_epoch 来保证控制器的唯一性,进而保证相关操作的一致性。
每个和控制器交互的请求都会携带 controller_epoch 这个字段,如果请求的 controller_epoch 值小于内存中的 controller_epoch 值,则认为这个请求是向已经过期的控制器所发送的请求,那么这个请求会被认定为无效的请求。
如果请求的 controller_epoch 值大于内存中的 controller_epoch 值,那么说明已经有新的控制器当选了。
3. 控制器是做什么的
主题管理(创建、删除、增加分区):这里的主题管理,就是指控制器帮助我们完成对 Kafka 主题的创建、删除以及分区增加的操作。,当我们执行 kafka-topics 脚本时,大部分的后台工作都是控制器来完成的。
分区重分配:分区重分配主要是指,kafka-reassign-partitions 脚本提供的对已有主题分区进行细粒度的分配功能
Preferred 领导者选举:Preferred 领导者选举主要是 Kafka 为了避免部分 Broker 负载过重而提供的一种换 Leader 的方案。
集群成员管理(新增 Broker、Broker 主动关闭、Broker 宕机):控制器组件会利用 Watch 机制检查 ZooKeeper 的 /brokers/ids 节点下的子节点数量变更。目前,当有新 Broker 启动后,它会在 /brokers 下创建专属的 znode 节点。一旦创建完毕,ZooKeeper 会通过 Watch 机制将消息通知推送给控制器,这样,控制器就能自动地感知到这个变化,进而开启后续的新增 Broker 作业。
数据服务:控制器上保存了最全的集群元数据信息。
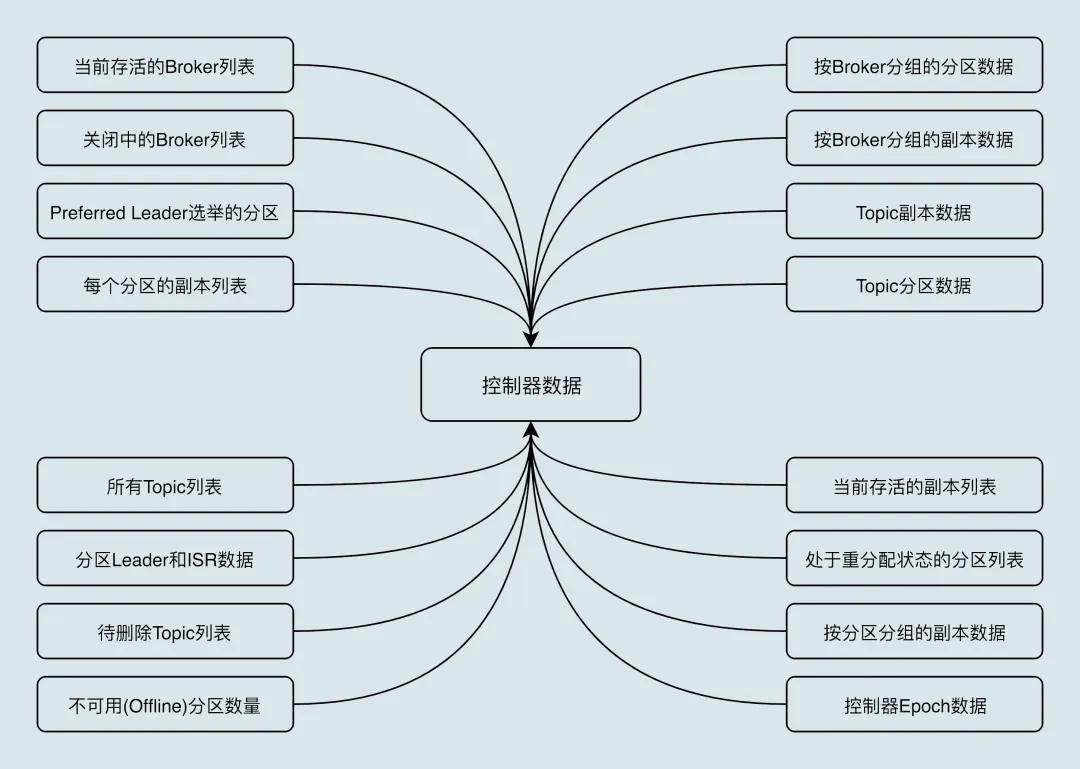
3.1. 处理集群中下线的Broker
当某个Broker节点由于故障离开Kafka群集时,则存在于该Broker的leader分区将不可用(由于客户端仅对leader分区进行读写操作)。为了最大程度地减少停机时间,需要快速找到替代的leader分区。
每个 Broker 启动后,会在zookeeper的 /Brokers/ids 下创建一个临时 znode。当 Broker 宕机或主动关闭后,该 Broker 与 ZooKeeper 的会话结束,这个 znode 会被自动删除。同理,ZooKeeper 的 Watch 机制将这一变更推送给控制器,这样控制器就能知道有 Broker 关闭或宕机了,从而进行后续的协调操作。
Controller将收到通知并对此采取行动,决定哪些Broker上的分区成为leader分区,然后,它会通知每个相关的Broker,要么将Broker上的主题分区变成leader,要么通过LeaderAndIsr请求从新的leader分区中复制数据。
3.2. 处理新加入到集群中的Broker
通过将Leader分区副本均匀地分布在集群的不同Broker上,可以保障集群的负载均衡。在Broker发生故障时,某些Broker上的分区副本会被选举为leader,会造成一个Broker上存在多个leader分区副本的情况,由于客户端只与leader分区副本交互,所以这会给Broker增加额外的负担,并损害集群的性能和运行状况。因此,尽快恢复平衡对集群的健康运行是有益的。
Kafka认为leader分区副本最初的分配(每个节点都处于活跃状态)是均衡的。这些被最初选中的分区副本就是所谓的首选领导者(preferred leaders)。由于Kafka还支持机架感知的leader选举(rack-aware leader election) ,即尝试将leader分区和follower分区放置在不同的机架上,以增加对机架故障的容错能力。因此,leader分区副本的存在位置会对集群的可靠性产生影响。
默认情况下auto.leader.rebalance.enabled为true,表示允许 Kafka 定期地对一些 Topic 分区进行Leader 重选举。大部分情况下,Broker的失败很短暂,这意味着Broker通常会在短时间内恢复。所以当节点离开群集时,与其相关联的元数据并不会被立即删除。
当Controller注意到Broker已加入集群时,它将使用Broker ID来检查该Broker上是否存在分区,如果存在,则Controller通知新加入的Broker和现有的Broker,新的Broker上面的follower分区再次开始复制现有leader分区的消息。为了保证负载均衡,Controller会将新加入的Broker上的follower分区选举为leader分区。
注意:上面提到的选Leader分区,严格意义上是换Leader分区,为了达到负载均衡,可能会造成原来正常的Leader分区被强行变为follower分区。换一次 Leader 代价是很高的,原本向 Leader分区A(原Leader分区) 发送请求的所有客户端都要切换成向 B (新的Leader分区)发送请求,建议你在生产环境中把这个参数设置成 false。
3.3. 同步副本(in-sync replica ,ISR)列表
ISR中的副本都是与Leader进行同步的副本,所以不在该列表的follower会被认为与Leader是不同步的. 那么,ISR中存在是什么副本呢?首先可以明确的是:Leader副本总是存在于ISR中。 而follower副本是否在ISR中,取决于该follower副本是否与Leader副本保持了“同步”。
始终保证拥有足够数量的同步副本是非常重要的。要将follower提升为Leader,它必须存在于同步副本列表中。每个分区都有一个同步副本列表,该列表由Leader分区和Controller进行更新。
选择一个同步副本列表中的分区作为leader 分区的过程称为clean leader election。注意,这里要与在非同步副本中选一个分区作为leader分区的过程区分开,在非同步副本中选一个分区作为leader的过程称之为unclean leader election。由于ISR是动态调整的,所以会存在ISR列表为空的情况,通常来说,非同步副本落后 Leader 太多,因此,如果选择这些副本作为新 Leader,就可能出现数据的丢失。毕竟,这些副本中保存的消息远远落后于老 Leader 中的消息。在 Kafka 中,选举这种副本的过程可以通过Broker 端参数 **unclean.leader.election.enable **控制是否允许 Unclean 领导者选举。开启 Unclean 领导者选举可能会造成数据丢失,但好处是,它使得分区 Leader 副本一直存在,不至于停止对外提供服务,因此提升了高可用性。反之,禁止 Unclean Leader 选举的好处在于维护了数据的一致性,避免了消息丢失,但牺牲了高可用性。分布式系统的CAP理论说的就是这种情况。
不幸的是,unclean leader election的选举过程仍可能会造成数据的不一致,因为同步副本并不是完全同步的。由于复制是异步完成的,因此无法保证follower可以获取最新消息。比如Leader分区的最后一条消息的offset是100,此时副本的offset可能不是100,这受到两个参数的影响:
- replica.lag.time.max.ms:同步副本滞后与leader副本的时间
- zookeeper.session.timeout.ms:与zookeeper会话超时时间
4. 控制器故障转移(Failover)
当运行中的控制器突然宕机或意外终止时,Kafka 能够快速地感知到,并立即启用备用控制器来代替之前失败的控制器。这个过程就被称为 Failover,该过程是自动完成的,无需你手动干预。
5. 脑裂
如果controller Broker 挂掉了,Kafka集群必须找到可以替代的controller,集群将不能正常运转。这里面存在一个问题,很难确定Broker是挂掉了,还是仅仅只是短暂性的故障。但是,集群为了正常运转,必须选出新的controller。如果之前被取代的controller又正常了,他并不知道自己已经被取代了,那么此时集群中会出现两台controller。
其实这种情况是很容易发生。比如,某个controller由于GC而被认为已经挂掉,并选择了一个新的controller。在GC的情况下,在最初的controller眼中,并没有改变任何东西,该Broker甚至不知道它已经暂停了。因此,它将继续充当当前controller,这是分布式系统中的常见情况,称为脑裂。
假如,处于活跃状态的controller进入了长时间的GC暂停。它的ZooKeeper会话过期了,之前注册的/controller节点被删除。集群中其他Broker会收到zookeeper的这一通知。
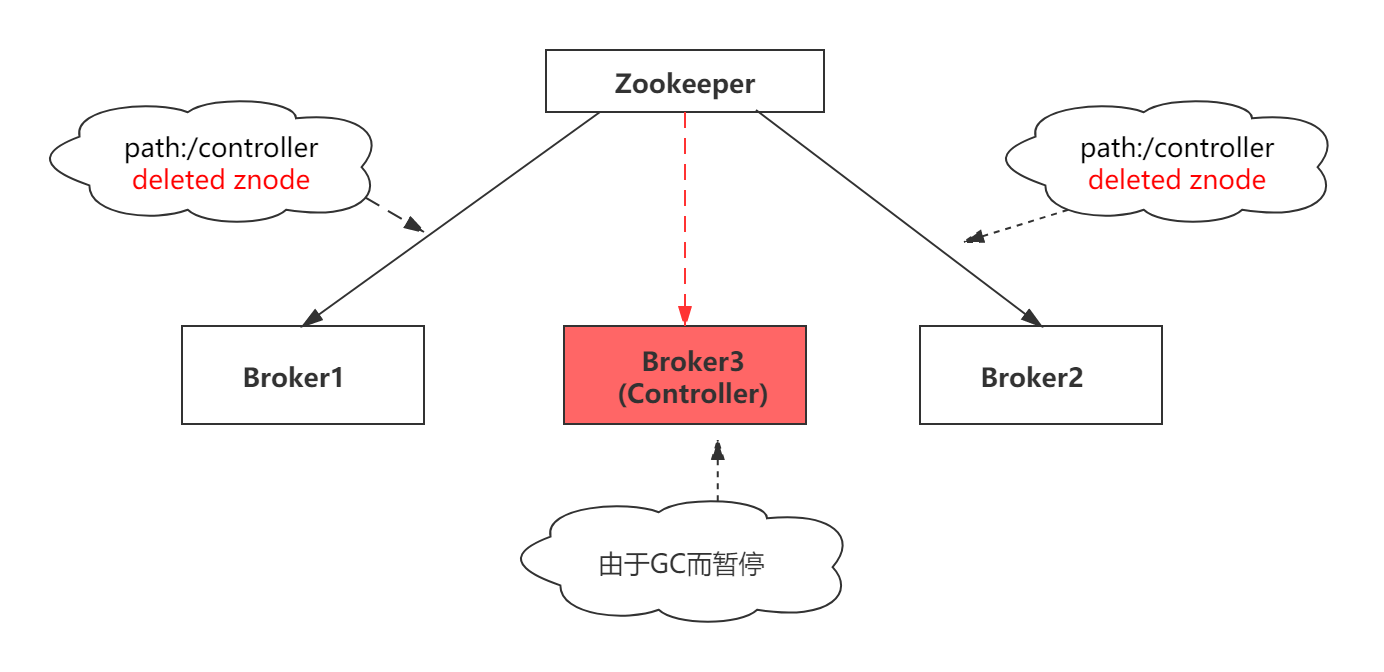
由于集群中必须存在一个controller Broker,所以现在每个Broker都试图尝试成为新的controller。假设Broker 2速度比较快,成为了最新的controller Broker。此时,每个Broker会收到Broker2成为新的controller的通知,由于Broker3正在进行”stop the world”的GC,可能不会收到Broker2成为最新的controller的通知。
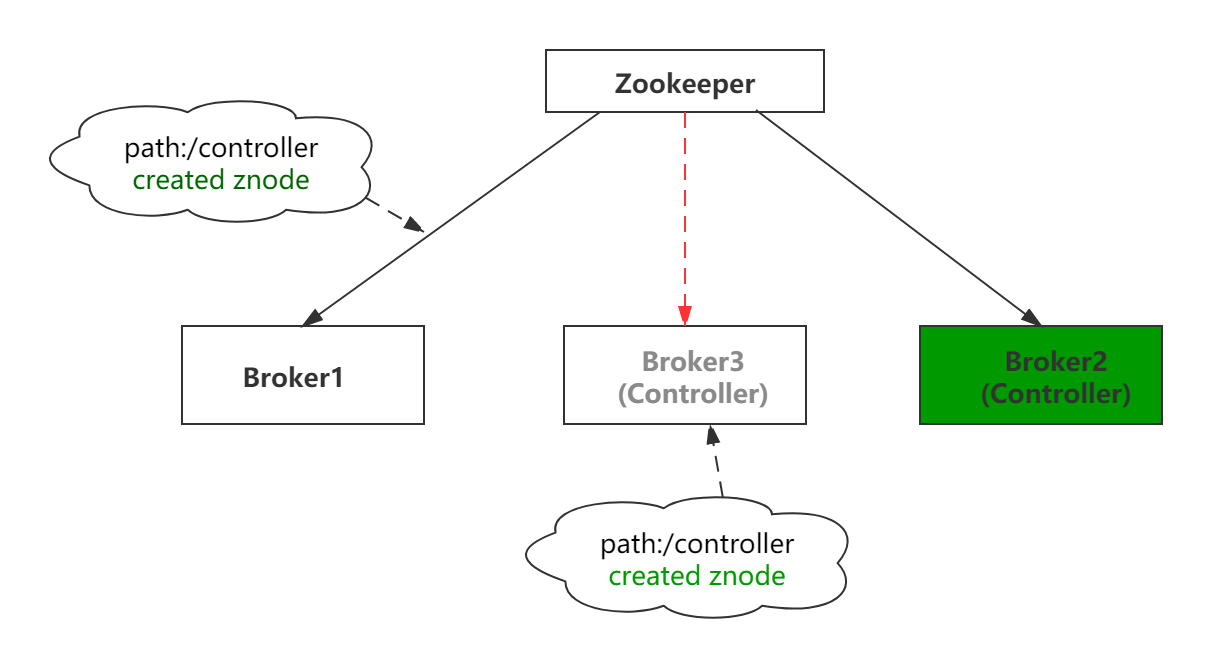
等到Broker3的GC完成之后,仍会认为自己是集群的controller,在Broker3的眼中好像什么都没有发生一样。

现在,集群中出现了两个controller,它们可能一起发出具有冲突的命令,就会出现脑裂的现象。如果对这种情况不加以处理,可能会导致严重的不一致。所以需要一种方法来区分谁是集群当前最新的Controller。
Kafka是通过使用epoch number(纪元编号,也称为隔离令牌)来完成的。epoch number只是单调递增的数字,第一次选出Controller时,epoch number值为1,如果再次选出新的Controller,则epoch number将为2,依次单调递增。
每个新选出的controller通过Zookeeper 的条件递增操作获得一个全新的、数值更大的epoch number 。其他Broker 在知道当前epoch number 后,如果收到由controller发出的包含较旧(较小)epoch number的消息,就会忽略它们,即Broker根据最大的epoch number来区分当前最新的controller。
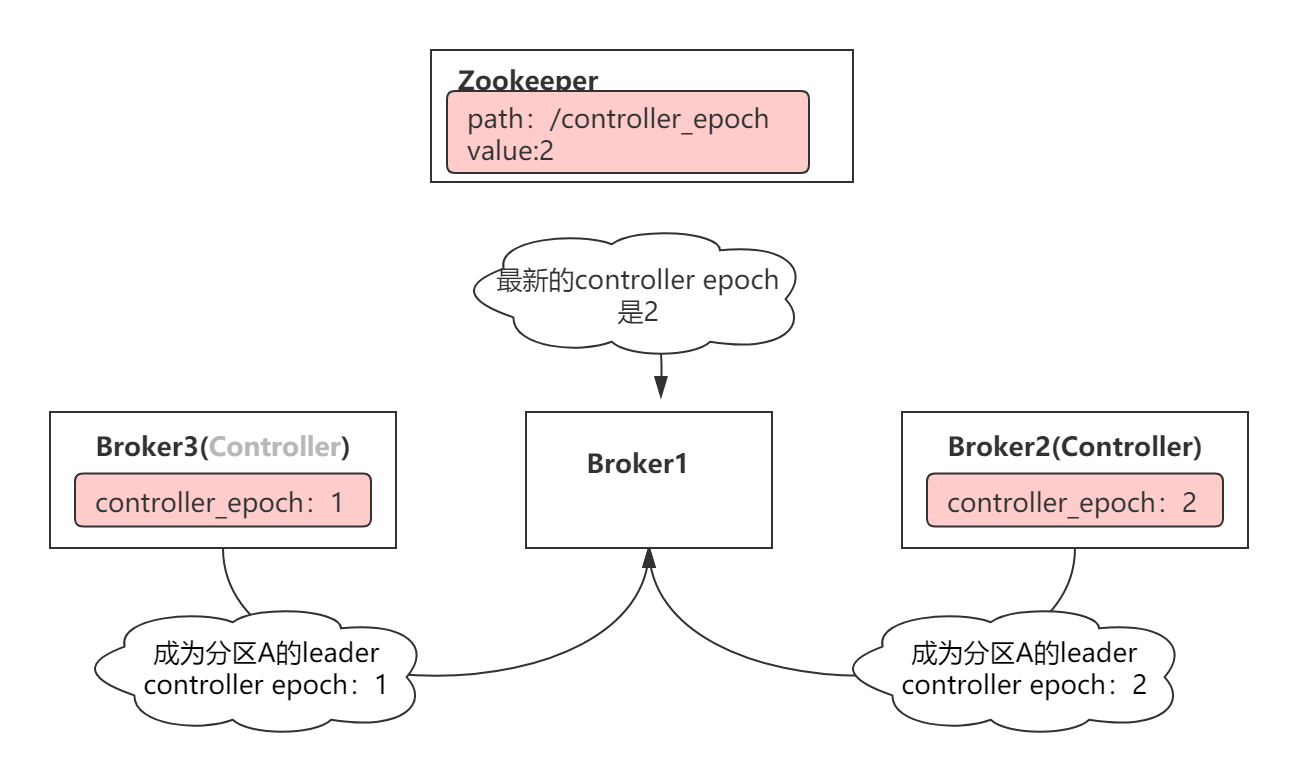
上图,Broker3向Broker1发出命令:让Broker1上的某个分区副本成为leader,该消息的epoch number值为1。于此同时,Broker2也向Broker1发送了相同的命令,不同的是,该消息的epoch number值为2,此时Broker1只听从Broker2的命令(由于其epoch number较大),会忽略Broker3的命令,从而避免脑裂的发生。
参考资料
https://jiamaoxiang.top/2020/07/06/Kafka%E7%9A%84Controller-Broker%E6%98%AF%E4%BB%80%E4%B9%88/
