我们知道消息肯定是放在内存中的,大数据场景消息的不断发送,内存中不断存在大量的消息,很容易引起GC。
频繁的GC特别是full gc是会造成“stop the world”,也就是其他线程停止工作等待垃圾回收线程执行,继而进一步影响发送的速度影响吞吐量,那么Kafka是如何做到优化JVM的GC问题的呢?
下面介绍下Kafka客户端发送的大致过程,如下图:
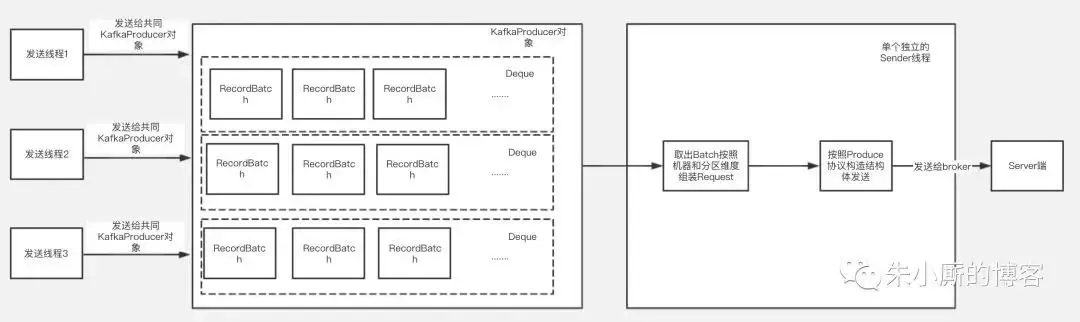
Kafka的kafkaProducer对象是线程安全的,每个发送线程在发送消息时候共用一个kafkaProducer对象来调用发送方法,最后发送的数据根据Topic和分区的不同被组装进某一个RecordBatch中。
发送的数据放入RecordBatch后会被发送线程批量取出组装成ProduceRequest对象发送给Kafka服务端。
可以看到发送数据线程和取数据线程都要跟内存中的RecordBatch打交道,RecordBatch是存储数据的对象,那么RecordBatch是怎么分配的呢?
下面我们看下Kafka的缓冲池结构,如下图所示:
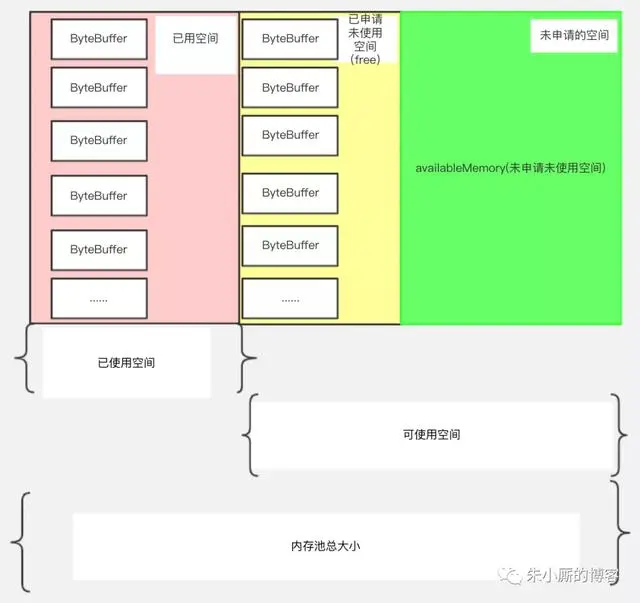
整个KafkaProducer实例中只有一个BufferPool对象。内存池总大小,它是已使用空间和可使用空间的总和,用totalMemory表示(由buffer.memory配置,默认32M)。
可使用的空间:它包含包括两个部分,绿色部分代表未申请未使用的部分,用availableMemory表示
黄色部分代表已经申请但没有使用的部分,用一个ByteBuffer双端队列(Deque)表示,在BufferPool中这个队列叫free,队列中的每个ByteBuffer的大小用poolableSize表示(由batch.size配置,默认16k),因为每次free申请内存都是以poolableSize为单位申请的,申请poolableSize大小的bytebuffer后用RecordBatch来包装起来。
已使用空间:代表缓冲池中已经装了数据的部分。
根据以上介绍,我们可以知道,总的BufferPool大小=已使用空间+可使用空间;free的大小=free.size * poolableSize(poolsize就是单位batch的size)。
如果没有使用缓冲池,那么用户发送的模型如下图,由于GC特别是Full GC的存在,如果大量发送,就可能会发生频繁的垃圾回收,导致的工作线程的停顿,会对整个发送性能,吞吐量延迟等都有影响。
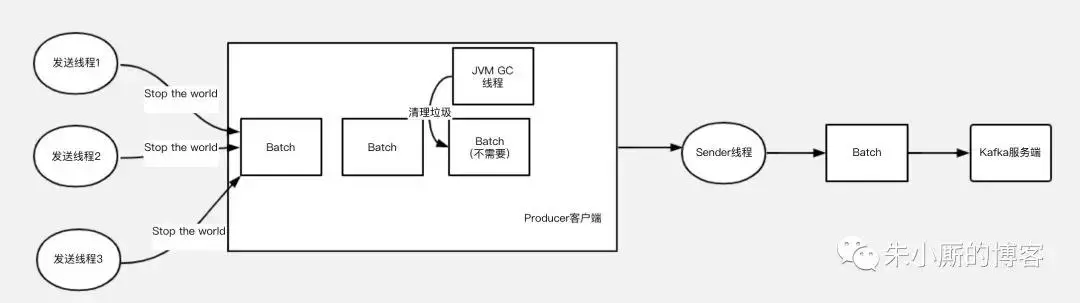
使用缓冲池后,整个使用过程可以缩略为下图:

参考资料
https://mp.weixin.qq.com/s/ewpuNa8tzGUTshTfvBXboQ
