1. buffer.memory
Kafka的客户端发送数据到服务器,一般都是要经过缓冲的,也就是说,你通过KafkaProducer发送出去的消息都是先进入到客户端本地的内存缓冲里,然后把很多消息收集成一个一个的Batch,再发送到Broker上去的。
所以这个buffer.memory的本质就是用来约束KafkaProducer能够使用的内存缓冲的大小的,他的默认值是32MB。
在内存缓冲里大量的消息会缓冲在里面,形成一个一个的Batch,每个Batch里包含多条消息。
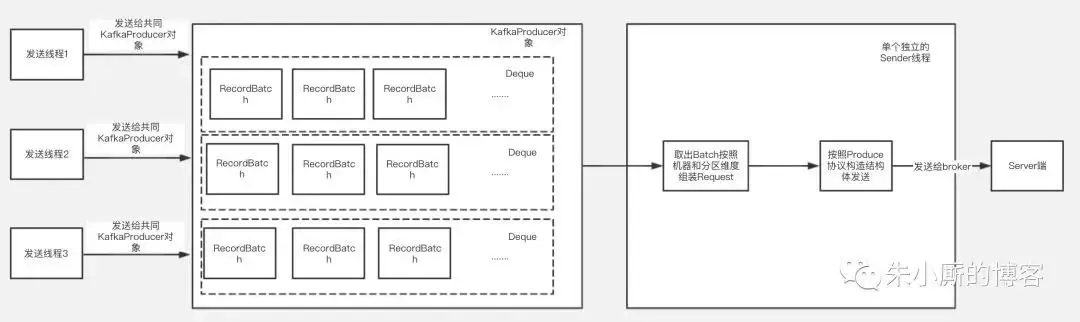
那么如果要是内存设置的太小,可能导致一个问题:消息快速的写入内存缓冲里面,但是Sender线程来不及把Request发送到Kafka服务器。
这样会造成内存缓冲很快就被写满,一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息了。
所以对于“buffer.memory”这个参数应该结合自己的实际情况来进行压测,你需要测算一下在生产环境,你的用户线程会以每秒多少消息的频率来写入内存缓冲。
比如说每秒300条消息,那么你就需要压测一下,假设内存缓冲就32MB,每秒写300条消息到内存缓冲,是否会经常把内存缓冲写满?经过这样的压测,你可以调试出来一个合理的内存大小。
如果生产者发送消息的速度超过了将消息发送到broker的速度,或者存在网络问题,send()方法调用会被阻塞max.block.ms参数配置的时常,默认1分钟。
2. batch.size
batch.size决定了你的每个Batch要存放多少数据就可以发送出去了。
比如说你要是给一个Batch设置成是16KB的大小,那么里面凑够16KB的数据就可以发送了。
这个参数的默认值是16KB,一般可以尝试把这个参数调节大一些,然后利用自己的生产环境发消息的负载来测试一下。
比如说发送消息的频率就是每秒300条,那么如果比如“batch.size”调节到了32KB,或者64KB,是否可以提升发送消息的整体吞吐量。
因为理论上来说,提升batch的大小,可以允许更多的数据缓冲在里面,那么一次Request发送出去的数据量就更多了,这样吞吐量可能会有所提升。
但是这个东西也不能无限的大,过于大了之后,要是数据老是缓冲在Batch里迟迟不发送出去,那么岂不是你发送消息的延迟就会很高。
比如说,一条消息进入了Batch,但是要等待5秒钟Batch才凑满了64KB,才能发送出去。那这条消息的延迟就是5秒钟。
所以需要在这里按照生产环境的发消息的速率,调节不同的Batch大小自己测试一下最终出去的吞吐量以及消息的 延迟,设置一个最合理的参数。
3. linger.ms
要是一个Batch迟迟无法凑满,此时就需要引入另外一个参数了:linger.ms。
他的含义就是说一个Batch被创建之后,最多过多久,不管这个Batch有没有写满,都必须发送出去了。
给大家举个例子,比如说batch.size是16kb,但是现在某个低峰时间段,发送消息很慢。这就导致可能Batch被创建之后,陆陆续续有消息进来,但是迟迟无法凑够16KB,难道此时就一直等着吗?
当然不是,假设你现在设置linger.ms是50ms,那么只要这个Batch从创建开始到现在已经过了50ms了,哪怕他还没满16KB,也要发送他出去了。
所以linger.ms决定了你的消息一旦写入一个Batch,最多等待这么多时间,他一定会跟着Batch一起发送出去。
避免一个Batch迟迟凑不满,导致消息一直积压在内存里发送不出去的情况。这是一个很关键的参数。
这个参数一般要非常慎重的来设置,要配合batch.size一起来设置。
举个例子,首先假设你的Batch是32KB,那么你得估算一下,正常情况下,一般多久会凑够一个Batch,比如正常来说可能20ms就会凑够一个Batch。
那么你的linger.ms就可以设置为25ms,也就是说,正常来说,大部分的Batch在20ms内都会凑满,但是你的linger.ms可以保证,哪怕遇到低峰时期,20ms凑不满一个Batch,还是会在25ms之后强制Batch发送出去。
如果要是你把linger.ms设置的太小了,比如说默认就是0ms,或者你设置个5ms,那可能导致你的Batch虽然设置了32KB,但是经常是还没凑够32KB的数据,5ms之后就直接强制Batch发送出去,这样也不太好其实,会导致你的Batch形同虚设,一直凑不满数据。
4. max.request.size
“max.request.size”这个参数决定了每次发送给Kafka服务器请求的最大大小,同时也会限制你一条消息的最大大小也不能超过这个参数设置的值,这个其实可以根据你自己的消息的大小来灵活的调整。
给大家举个例子,你们公司发送的消息都是那种大的报文消息,每条消息都是很多的数据,一条消息可能都要20KB。
此时你的batch.size是不是就需要调节大一些?比如设置个512KB?然后你的buffer.memory是不是要给的大一些?比如设置个128MB?
只有这样,才能让你在大消息的场景下,还能使用Batch打包多条消息的机制。但是此时“max.request.size”是不是也得同步增加?
因为可能你的一个请求是很大的,默认他是1MB,你是不是可以适当调大一些,比如调节到5MB?
5. 重试机制
retries和retries.backoff.ms决定了重试机制,也就是如果一个请求失败了可以重试几次,每次重试的间隔是多少毫秒。
这个大家适当设置几次重试的机会,给一定的重试间隔即可,比如给100ms的重试间隔。
6. 持久化机制
ack参数决定了发送出去的消息要采用什么样的持久化策略,
8. compression.type
默认情况下,消息发送时不会被压缩。该参数可以设置为snappy 、gzip 或lz4 ,它指定了消息被发送给broker 之前使用哪一种压缩算也进行压缩。使用压缩可以降低网络传输开销和存储开销,而这往往是向Kafka 发送消息的瓶颈所在。
9. max.block.ms
该参数指定了在调用send()方法或使用partitionsFor()方法获取元数据时生产者的阻塞时间。当生产者的发送缓冲区已满,或者没有可用的元数据时,这些方法就会被阻塞。在阻塞时间达到max.block.ms时,生产者会抛出超时异常。
10. max.in.flight.requests.per.connection
该参数指定了生产者在收到服务器晌应之前可以发送多少个消息。它的值越高,就会占用越多的内存,不过也会提升吞吐量。把它设为1可以保证消息是按照发送的顺序写入服务器的,即使发生了重试。
因为如果将两个批次发送到单个分区,并且第一个批次失败并被重试,但是,接着第二个批次写入成功,则第二个批次中的记录可能会首先出现,这样就会发生乱序。
如果没有启用幂等功能,但仍然希望按顺序发送消息,则应将此设置配置为1。但是,如果已经启用了幂等,则无需显式定义此配置。
11. enable.idempotence
在某些情况下,实际上已将消息提交给了所有同步副本,但是由于网络问题,Broker无法向Producer发送确认ack。由于我们设置retries=3,所以producer将重新发送消息3次,这可能会导致topic中消息重复。
比如有一个producer向该topic发送1M消息,并且在提交消息之后但在生产者收到所有确认ack之前,broker失败了。在这种情况下,由于重试机制,最终可能在该topic上收到超过1M的消息,这也称为at-lease-once语义。
当然,我们想要实现的是exactly-once语义,即:即便生产者重新发送消息,消费者也应该只收到一次相同的消息。
此时需要进行幂等操作,所谓幂等,即指一次执行一个操作或多次执行一个操作具有相同的效果。配置幂等很简单,通过配置enable.idempotence=true即可,默认为false。
那么,幂等是如何实现的呢?由于消息是分batch(批次)发送的,每个batch(批次)都有一个序列号。在Broker端,会追踪每个分区的最大序列号。如果出现序列号较小或相等的batch(批次),broker将不会将该batch(批次)写入topic。这样,除了保证了幂等性,还可以确保batch(批次)的顺序。
12. 参考资料
https://mp.weixin.qq.com/s/awBlZ8v7ksfOlK1JpQ-sUA
