1. Linux IO读取方式
Linux 提供了轮询、I/O 中断以及 DMA 传输这 3 种磁盘与主存之间的数据传输机制
- 轮询方式是基于死循环对 I/O 端口进行不断检测
- I/O 中断方式是指当数据到达时,磁盘主动向 CPU 发起中断请求,由 CPU 自身负责数据的传输过程
- DMA 传输则在 I/O 中断的基础上引入了 DMA 磁盘控制器,由 DMA 磁盘控制器负责数据的传输,降低了 I/O 中断操作对 CPU 资源的大量消耗
1.1. IO中断
在 DMA 技术出现之前,应用程序与磁盘之间的 I/O 操作都是通过 CPU 的中断完成的
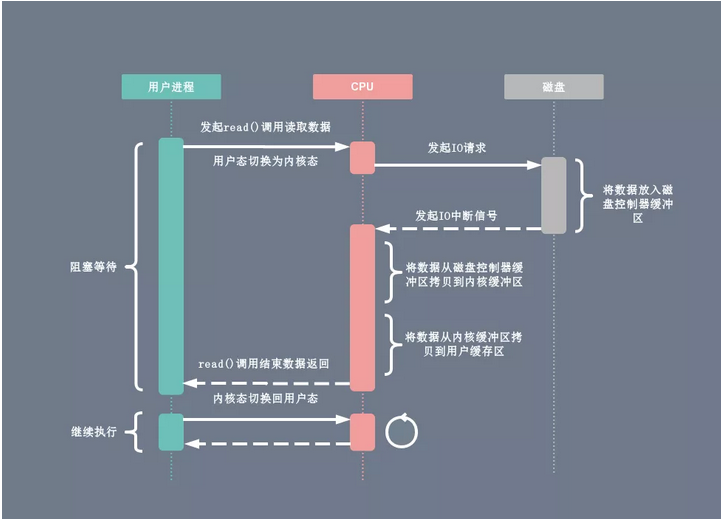
每次用户进程读取磁盘数据时,都需要 CPU 中断,然后发起 I/O 请求等待数据读取和拷贝完成,每次的 I/O 中断都导致 CPU 的上下文切换:
- 用户进程向 CPU 发起 read 系统调用读取数据,由用户态切换为内核态,然后一直阻塞等待数据的返回
- CPU 在接收到指令以后对磁盘发起 I/O 请求,将磁盘数据先放入磁盘控制器缓冲区
- 数据准备完成以后,磁盘向 CPU 发起 I/O 中断
- CPU 收到 I/O 中断以后将磁盘缓冲区中的数据拷贝到内核缓冲区,然后再从内核缓冲区拷贝到用户缓冲区
- 用户进程由内核态切换回用户态,解除阻塞状态,然后等待 CPU 的下一个执行时间钟。
计算机执行程序时,会有优先级的需求。比如,当计算机收到断电信号时(电容可以保存少许电量,供CPU运行很短的一小段时间),它应立即去保存数据,保存数据的程序具有较高的优先级。
一般而言,由硬件产生的信号需要cpu立马做出回应(不然数据可能就丢失),所以它的优先级很高。cpu理应中断掉正在执行的程序,去做出响应;当cpu完成对硬件的响应后,再重新执行用户程序。
以键盘为例,当用户按下键盘某个按键时,键盘会给cpu的中断引脚发出一个高电平。cpu能够捕获这个信号,然后执行键盘中断程序。
以网卡为例,网卡会把接收到的数据写入内存。当网卡把数据写入到内存后,网卡向cpu发出一个中断信号,操作系统便能得知有新数据到来,再通过网卡中断程序去处理数据。
1.2. DMA
DMA 的全称叫直接内存存取(Direct Memory Access),是一种允许外围设备(硬件子系统)直接访问系统主内存的机制。也就是说,基于 DMA 访问方式,系统主内存于硬盘或网卡之间的数据传输可以绕开 CPU 的全程调度。目前大多数的硬件设备,包括磁盘控制器、网卡、显卡以及声卡等都支持 DMA 技术。
整个数据传输操作在一个 DMA 控制器的控制下进行的。CPU 除了在数据传输开始和结束时做一点处理外(开始和结束时候要做中断处理),在传输过程中 CPU 可以继续进行其他的工作。这样在大部分时间里,CPU 计算和 I/O 操作都处于并行操作,使整个计算机系统的效率大大提高。
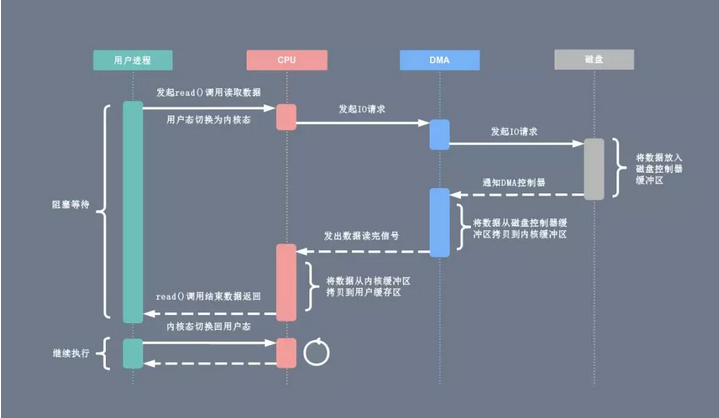
有了 DMA 磁盘控制器接管数据读写请求以后,CPU 从繁重的 I/O 操作中解脱,数据读取操作的流程如下:
- 用户进程向 CPU 发起 read 系统调用读取数据,由用户态切换为内核态,然后一直阻塞等待数据的返回
- CPU 在接收到指令以后对 DMA 磁盘控制器发起调度指令
- DMA 磁盘控制器对磁盘发起 I/O 请求,将磁盘数据先放入磁盘控制器缓冲区,CPU 全程不参与此过程
- 数据读取完成后,DMA 磁盘控制器会接受到磁盘的通知,将数据从磁盘控制器缓冲区拷贝到内核缓冲区
- DMA 磁盘控制器向 CPU 发出数据读完的信号,由 CPU 负责将数据从内核缓冲区拷贝到用户缓冲区
- 用户进程由内核态切换回用户态,解除阻塞状态,然后等待 CPU 的下一个执行时间钟。
2. 缓存 I/O (Buffered I/O)
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。写的过程就是数据流反方向。
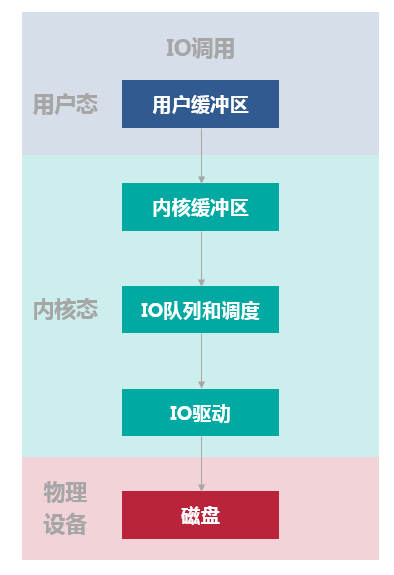
对于读操作:当应用程序要去读取某块数据的时候,如果这块数据已经在页缓存中,那直接返回,而不需要经过硬盘的读取操作了。如果这块数据不在页缓存中,就需要从硬盘中读取数据到页缓存。
对于写操作:应用程序会将数据先写到页缓存中,数据是否会被立即写到磁盘,这取决于所采用的写操作机制。
- 同步写机制( synchronous writes ):数据会立即被写回到磁盘上,应用程序会一直等到数据被写完为止;
- 延迟写机制( deferred writes ):应用程序不需要等到数据全部被写回到磁盘,数据只要被写到页缓存中去就可以了。在延迟写机制的情况下,操作系统会定期地将放在页缓存中的数据刷到磁盘上。与异步写机制( asynchronous writes )不同的是,延迟写机制在数据完全写到磁盘上的时候不会通知应用程序,而异步写机制在数据完全写到磁盘上的时候是会返回给应用程序的。所以延迟写机制本身是存在数据丢失的风险的,而异步写机制则不会有这方面的担心。(写接口返回的时候,页缓存的数据还没刷到硬盘,正好断电。)
缓存 I/O 有以下这些优点:
- 缓存 I/O 使用了操作系统内核缓冲区,在一定程度上分离了应用程序空间和实际的物理设备。
- 缓存 I/O 可以减少读盘的次数,从而提高性能。
在缓存 I/O 机制中,DMA 方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输,这样的话,数据在传输过程中需要在应用程序地址空间和页缓存之间进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
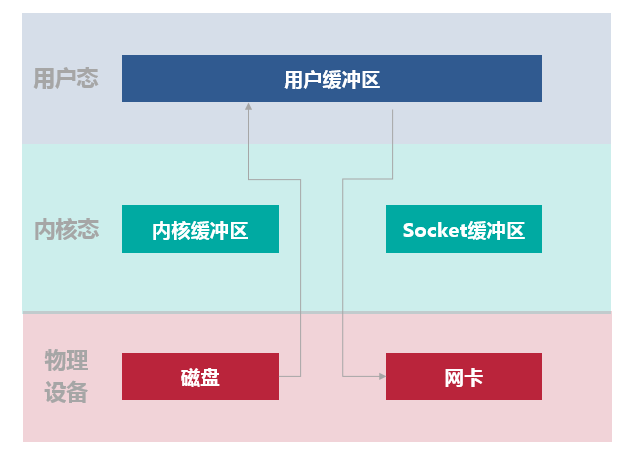
假如一个应用需要从某个磁盘文件中读取内容通过网络发出去如下图所示:整个过程涉及 2 次 CPU 拷贝、2 次 DMA 拷贝,总共 4 次拷贝,以及 4 次上下文切换。
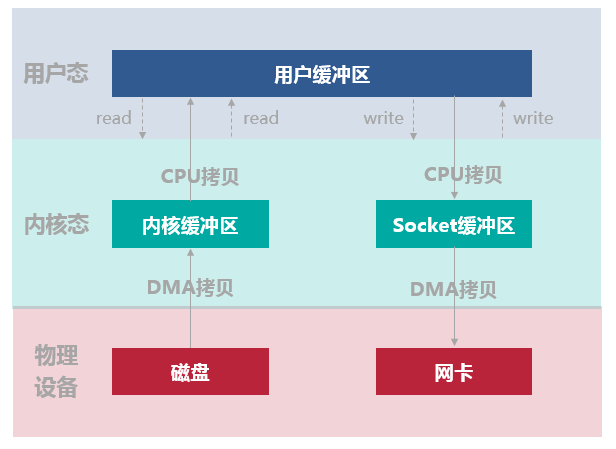
- 用户进程通过 read() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU 将读缓冲区(read buffer)中的数据拷贝到用户空间(user space)的用户缓冲区(user buffer)。
- 上下文从内核态(kernel space)切换回用户态(user space),read 调用执行返回。
- 用户进程通过 write() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 将用户缓冲区(user buffer)中的数据拷贝到内核空间(kernel space)的网络缓冲区(socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),write 系统调用执行返回。
对于某些特殊的应用程序来说,避开操作系统内核缓冲区而直接在应用程序地址空间和磁盘之间传输数据会比使用操作系统内核缓冲区获取更好的性能。
3. 直接IO
凡是通过直接I/O方式进行数据传输,数据直接从用户态地址空间写入到磁盘中,直接跳过内核缓冲区。对于一些应用程序,例如:数据库。他们更倾向于自己的缓存机制,这样可以提供更好的缓冲机制提高数据库的读写性能。
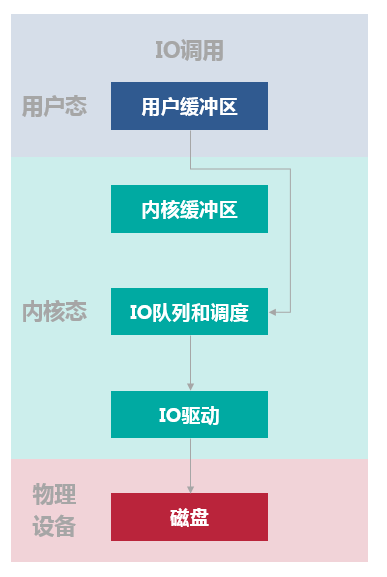
- 优点:通过减少操作系统内核缓冲区和应用程序地址空间的数据拷贝次数,降低了对文件读取和写入时所带来的 CPU 的使用以及内存带宽的占用。这对于某些特殊的应用程序,不失为一种好的选择。如果要传输的数据量很大,使用直接 I/O 的方式进行数据传输,而不需要操作系统内核地址空间拷贝数据操作的参与,这将会大大提高性能。
- 缺点:直接IO的开销也很大,应用程序没有控制好读写,将会导致磁盘读写的效率低下。磁盘的读写是通过磁头的切换到不同的磁道上读取和写入数据,如果需要写入数据在磁盘位置相隔比较远,就会导致寻道的时间大大增加,写入读取的效率大大降低。解决这个问题需要和异步 I/O 结合使用。
如下图所示的数据读写流程,整个过程不涉及CPU 拷贝和上下文切换。
4. 内存映射mmp
在Linux中内存区域( memory region )是可以跟一个普通的文件或者块设备文件的某一个部分关联起来的,若进程要访问内存页中某个字节的数据,操作系统就会将访问该内存区域的操作转换为相应的访问文件的某个字节的操作。Linux 中提供了系统调用 mmap() 来实现这种文件访问方式。与标准的访问文件的方式相比,内存映射方式可以减少标准访问文件方式中 read() 系统调用所带来的数据拷贝操作,即减少数据在用户地址空间和操作系统内核地址空间之间的拷贝操作。映射通常适用于较大范围,对于相同长度的数据来讲,映射所带来的开销远远低于 CPU 拷贝所带来的开销。当大量数据需要传输的时候,采用内存映射方式去访问文件会获得比较好的效率。
在内存映射的过程中,并没有实际的数据拷贝,文件没有被载入内存,只是逻辑上被放入了内存。进程最终是怎么直接通过内存操作访问到硬盘上的文件这个问题我没有深入学习
内存映射,简而言之就是将用户空间的一段内存区域映射到内核空间,映射成功后,用户对这段内存区域的修改可以直接反映到内核空间,同样,内核空间对这段区域的修改也直接反映用户空间。那么对于内核空间<—->用户空间两者之间需要大量数据传输等操作的话效率是非常高的。
下图所示的数据读写流程,整个过程会发生 4 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝。
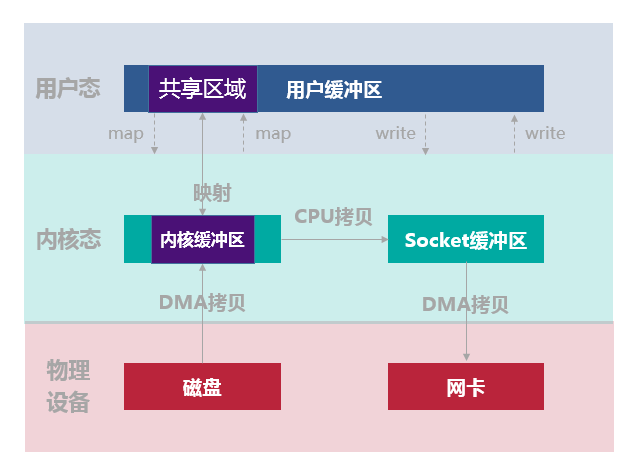
- 用户进程通过 mmap() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- 将用户进程的内核空间的读缓冲区(read buffer)与用户空间的缓存区(user buffer)进行内存地址映射。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- 上下文从内核态(kernel space)切换回用户态(user space),mmap 系统调用执行返回。
- 用户进程通过 write() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 将读缓冲区(read buffer)中的数据拷贝到网络缓冲区(socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),write 系统调用执行返回。
从硬盘上将文件读入内存,都要经过文件系统进行数据拷贝,并且数据拷贝操作是由文件系统和硬件驱动实现的,理论上来说,拷贝数据的效率是一样的。但是通过内存映射的方法访问硬盘上的文件,效率要比read和write系统调用高:
- read/write是系统调用,read()首先将文件内容从硬盘拷贝到内核空间的一个缓冲区,然后再将这些数据拷贝到用户空间,在这个过程中,实际上完成了 两次数据拷贝
- mmap()也是系统调用,mmap()中没有进行数据拷贝,真正的数据拷贝是在缺页中断处理时进行的,由于mmap()将文件直接映射到用户空间,所以中断处理函数根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了 一次数据拷贝 。
mmap 主要的用处是提高 I/O 性能,特别是针对大文件。对于小文件,内存映射文件反而会导致碎片空间的浪费。因为内存映射总是要对齐页边界,最小单位是 4 KB,一个 5 KB 的文件将会映射占用 8 KB 内存,也就会浪费 3 KB 内存。
mmap 隐藏着一个陷阱,当 mmap 一个文件时,如果这个文件被另一个进程所截获,那么 write 系统调用会因为访问非法地址被 SIGBUS 信号终止,SIGBUS 默认会杀死进程并产生一个 coredump,如果服务器被这样终止了,那损失就可能不小了。
解决这个问题通常使用文件的租借锁:
首先为文件申请一个租借锁,当其他进程想要截断这个文件时,内核会发送一个实时的 RT_SIGNAL_LEASE 信号,告诉当前进程有进程在试图破坏文件,这样 write 在被 SIGBUS 杀死之前,会被中断,返回已经写入的字节数,并设置 errno 为 success。
通常的做法是在 mmap 之前加锁,操作完之后解锁:
5. Sendfile
Sendfile 系统调用在 Linux 内核版本 2.1 中被引入,目的是简化通过网络在两个通道之间进行的数据传输过程。Sendfile 系统调用的引入,不仅减少了 CPU 拷贝的次数,还减少了上下文切换的次数。与 mmap 内存映射方式不同的是, Sendfile 调用中 I/O 数据对用户空间是完全不可见的。也就是说,这是一次完全意义上的数据传输过程。
下图所示的数据读写流程,整个过程会发生 2 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝。
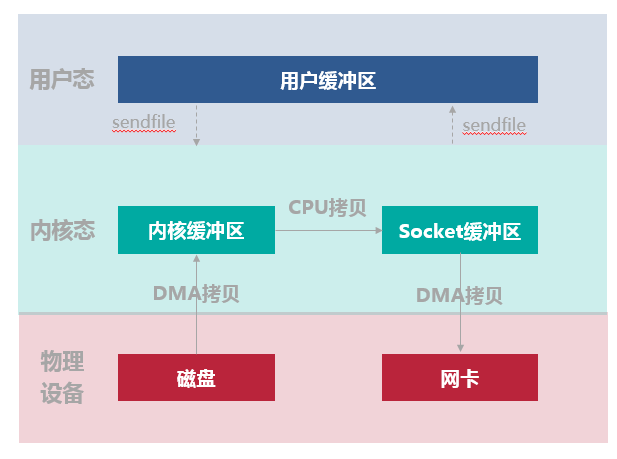
- 用户进程通过 sendfile() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU 将读缓冲区(read buffer)中的数据拷贝到的网络缓冲区(socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),Sendfile 系统调用执行返回。
Sendfile 存在的问题是用户程序不能对数据进行修改,而只是单纯地完成了一次数据传输过程。因此只能适用于那些不需要用户态处理的应用程序
6. Sendfile+DMA gather copy
Linux 2.4 版本的内核对 Sendfile 系统调用进行修改,为 DMA 拷贝引入了 gather 操作。它将内核空间(kernel space)的读缓冲区(read buffer)中对应的数据描述信息(内存地址、地址偏移量)记录到相应的网络缓冲区( socket buffer)中,由 DMA 根据内存地址、地址偏移量将数据批量地从读缓冲区(read buffer)拷贝到网卡设备中。这样就省去了内核空间中仅剩的 1 次 CPU 拷贝操作
下图所示的数据读写流程,整个过程会发生 2 次上下文切换和 2 次 DMA 拷贝。
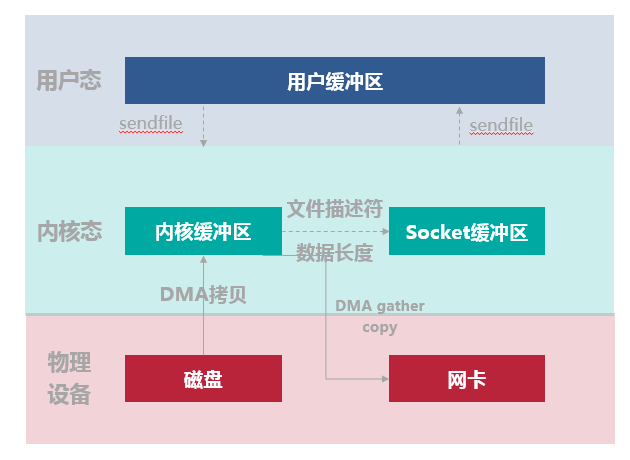
- 用户进程通过 sendfile() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU 把读缓冲区(read buffer)的文件描述符(file descriptor)和数据长度拷贝到网络缓冲区(socket buffer)。
- 基于已拷贝的文件描述符(file descriptor)和数据长度,CPU 利用 DMA 控制器的 gather/scatter 操作直接批量地将数据从内核的读缓冲区(read buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),Sendfile 系统调用执行返回。
Sendfile+DMA gather copy 拷贝方式同样存在用户程序不能对数据进行修改的问题,而且本身需要硬件的支持,它只适用于将数据从文件拷贝到 socket 套接字上的传输过程。
7. Splice
Sendfile 只适用于将数据从文件拷贝到 socket 套接字上,同时需要硬件的支持,这也限定了它的使用范围。Linux 在 2.6.17 版本引入 Splice 系统调用,不仅不需要硬件支持,还实现了两个文件描述符之间的数据零拷贝。
下图所示的数据读写流程,整个过程会发生 2 次上下文切换和 2 次 DMA 拷贝。
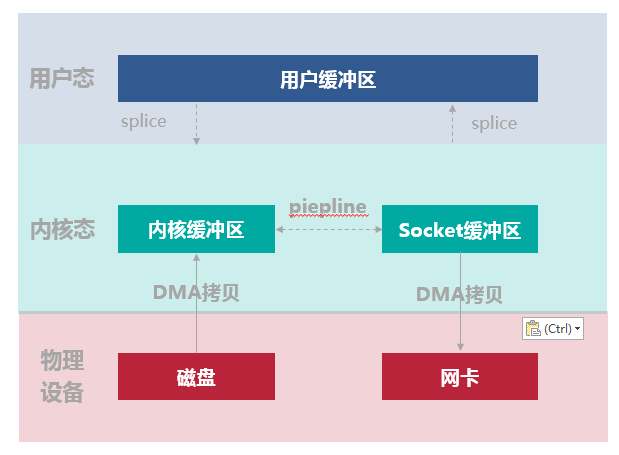
- 用户进程通过 splice() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU 在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),Splice 系统调用执行返回。
Splice 拷贝方式也同样存在用户程序不能对数据进行修改的问题。除此之外,它使用了 Linux 的管道缓冲机制,可以用于任意两个文件描述符中传输数据,但是它的两个文件描述符参数中有一个必须是管道设备。
8. 写时复制
在某些情况下,内核缓冲区可能被多个进程所共享,如果某个进程想要这个共享区进行 write 操作,由于 write 不提供任何的锁操作,那么就会对共享区中的数据造成破坏,写时复制的引入就是 Linux 用来保护数据的。
写时复制指的是当多个进程共享同一块数据时,如果其中一个进程需要对这份数据进行修改,那么就需要将其拷贝到自己的进程地址空间中。
这样做并不影响其他进程对这块数据的操作,每个进程要修改的时候才会进行拷贝,所以叫写时拷贝。这种方法在某种程度上能够降低系统开销,如果某个进程永远不会对所访问的数据进行更改,那么也就永远不需要拷贝。
缺陷:需要 MMU 的支持,MMU 需要知道进程地址空间中哪些页面是只读的,当需要往这些页面写数据时,发出一个异常给操作系统内核,内核会分配新的存储空间来供写入的需求。
9. 缓冲区共享
缓冲区共享方式完全改写了传统的 I/O 操作,因为传统 I/O 接口都是基于数据拷贝进行的,要避免拷贝就得去掉原先的那套接口并重新改写。所以这种方法是比较全面的零拷贝技术,目前比较成熟的一个方案是在 Solaris 上实现的 fbuf(Fast Buffer,快速缓冲区)。
fbuf 的思想是每个进程都维护着一个缓冲区池,这个缓冲区池能被同时映射到用户空间(user space)和内核态(kernel space),内核和用户共享这个缓冲区池,这样就避免了一系列的拷贝操作。
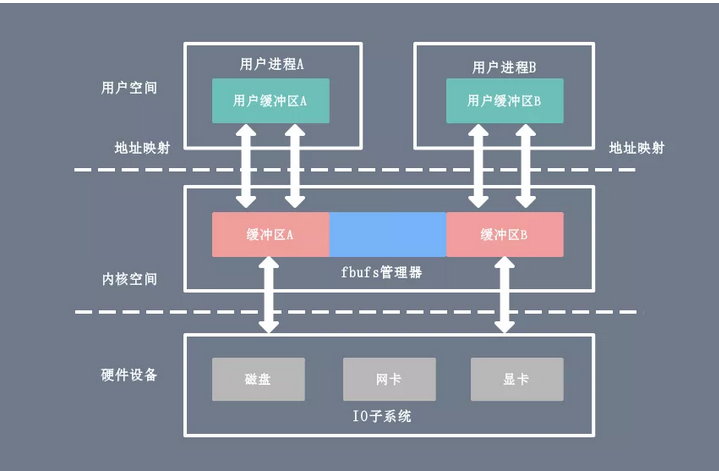
缺陷:缓冲区共享的难度在于管理共享缓冲区池需要应用程序、网络软件以及设备驱动程序之间的紧密合作,而且如何改写 API 目前还处于试验阶段并不成熟。
10. 参考资料
https://mp.weixin.qq.com/s/mZujKx1bKl1T6gEI1s400Q
https://cloud.tencent.com/developer/news/406991
https://www.ibm.com/developerworks/cn/linux/l-cn-directio/index.html
