1. IO协议栈图:

IO协议栈简化图:
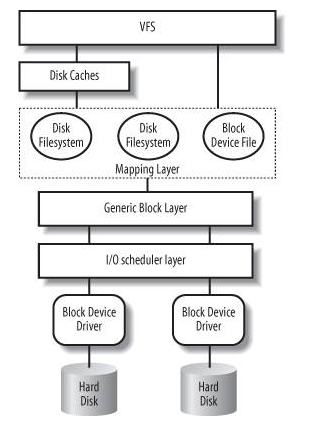
IO各层输入输出:
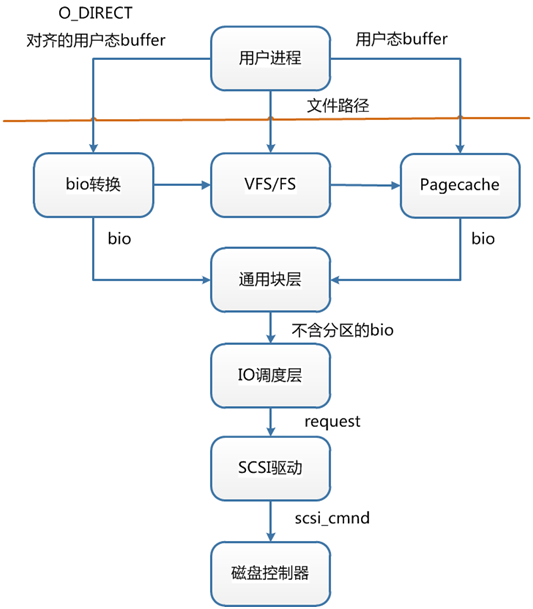
2. Buffered IO、mmap、Direct IO

-
Buffered IO:假设要去读一个冷文件(Cache中不存在),打开文件内核后建立了一系列的数据结构,接下来调用,到达文件系统这一层,发现
Page Cache中不存在该位置的磁盘映射,然后创建相应的Page Cache并和相关的扇区关联。然后请求继续到达块设备层,在 IO 队列里排队,接受一系列的调度后到达设备驱动层,此时一般使用DMA方式读取相应的磁盘扇区到 Cache 中,然后拷贝数据到用户提供的用户态buffer 中去。从磁盘到Page Cache算第一次的话,从Page Cache到用户态buffer就是第二次了。 - MMAP:
mmap直接把Page Cache映射到了用户态的地址空间里了,所以mmap的方式读文件是没有第二次拷贝过程的。 - Direct IO:直接让用户态和块 IO 层对接,直接放弃
Page Cache,从磁盘直接和用户态拷贝数据。写操作直接映射进程的buffer到磁盘扇区,以 DMA 的方式传输数据,减少了原本需要到Page Cache层的一次拷贝,提升了写的效率。对于读而言,第一次肯定也是快于传统的方式的,但是之后的读就不如传统方式了。
除了传统的 Buffered IO 可以比较自由的用偏移+长度的方式读写文件之外,mmap和 Direct IO 均有数据按页对齐的要求,Direct IO 还限制读写必须是底层存储设备块大小的整数倍(甚至 Linux 2.4 还要求是文件系统逻辑块的整数倍)。所以接口越来越底层,换来表面上的效率提升的背后,需要在应用程序这一层做更多的事情。
3. Page Cache 的同步
广义上 Cache 的同步方式有两种,即Write Through(写穿)和Write back(写回). 从名字上就能看出这两种方式都是从写操作的不同处理方式引出的概念(纯读的话就不存在 Cache 一致性了,不是么)。对应到 Linux 的Page Cache上所谓Write Through就是指write操作将数据拷贝到Page Cache后立即和下层进行同步的写操作,完成下层的更新后才返回。而Write back正好相反,指的是写完Page Cache就可以返回了。Page Cache到下层的更新操作是异步进行的。
Linux下Buffered IO默认使用的是Write back机制,即文件操作的写只写到Page Cache就返回,之后Page Cache到磁盘的更新操作是异步进行的。Page Cache中被修改的内存页称之为脏页(Dirty Page),脏页在特定的时候被一个叫做 pdflush (Page Dirty Flush)的内核线程写入磁盘,写入的时机和条件如下:
- 当空闲内存低于一个特定的阈值时,内核必须将脏页写回磁盘,以便释放内存。
- 当脏页在内存中驻留时间超过一个特定的阈值时,内核必须将超时的脏页写回磁盘。
- 用户进程调用
sync、fsync、fdatasync系统调用时,内核会执行相应的写回操作。
刷新策略由以下几个参数决定(数值单位均为1/100秒):
# flush每隔5秒执行一次
$ sysctl vm.dirty_writeback_centisecs
vm.dirty_writeback_centisecs = 500
# 内存中驻留30秒以上的脏数据将由flush在下一次执行时写入磁盘
$ sysctl vm.dirty_expire_centisecs
vm.dirty_expire_centisecs = 3000
# 若脏页占总物理内存10%以上,则触发flush把脏数据写回磁盘
$ sysctl vm.dirty_background_ratio
vm.dirty_background_ratio = 10
4. 参考资料
https://mp.weixin.qq.com/s?__biz=Mzg2NjE5NDQyOA==&mid=2247483824&idx=1&sn=48d3fd8374c035361a9df4e67b6528df&scene=21#wechat_redirect
