1. 指标
- CPU 使用率描述了非空闲时间占总 CPU 时间的百分比,根据 CPU 上运行任务的不同,又被分为用户 CPU、系统 CPU、等待 I/O CPU、软中断和硬中断等。
- 用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
- 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
- 等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
- 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
- 除了上面这些,还有在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
- 平均负载(Load Average) 也就是系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载。理想情况下,平均负载等于逻辑 CPU 个数,这表示每个 CPU 都恰好被充分利用。如果平均负载大于逻辑 CPU 个数,就表示负载比较重了。
- 进程上下文切换 过多的上下文切换,会将原本运行进程的 CPU 时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。
- 无法获取资源而导致的自愿上下文切换;比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换
- 被系统强制调度导致的非自愿上下文切换。指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换
- CPU 缓存的命中率
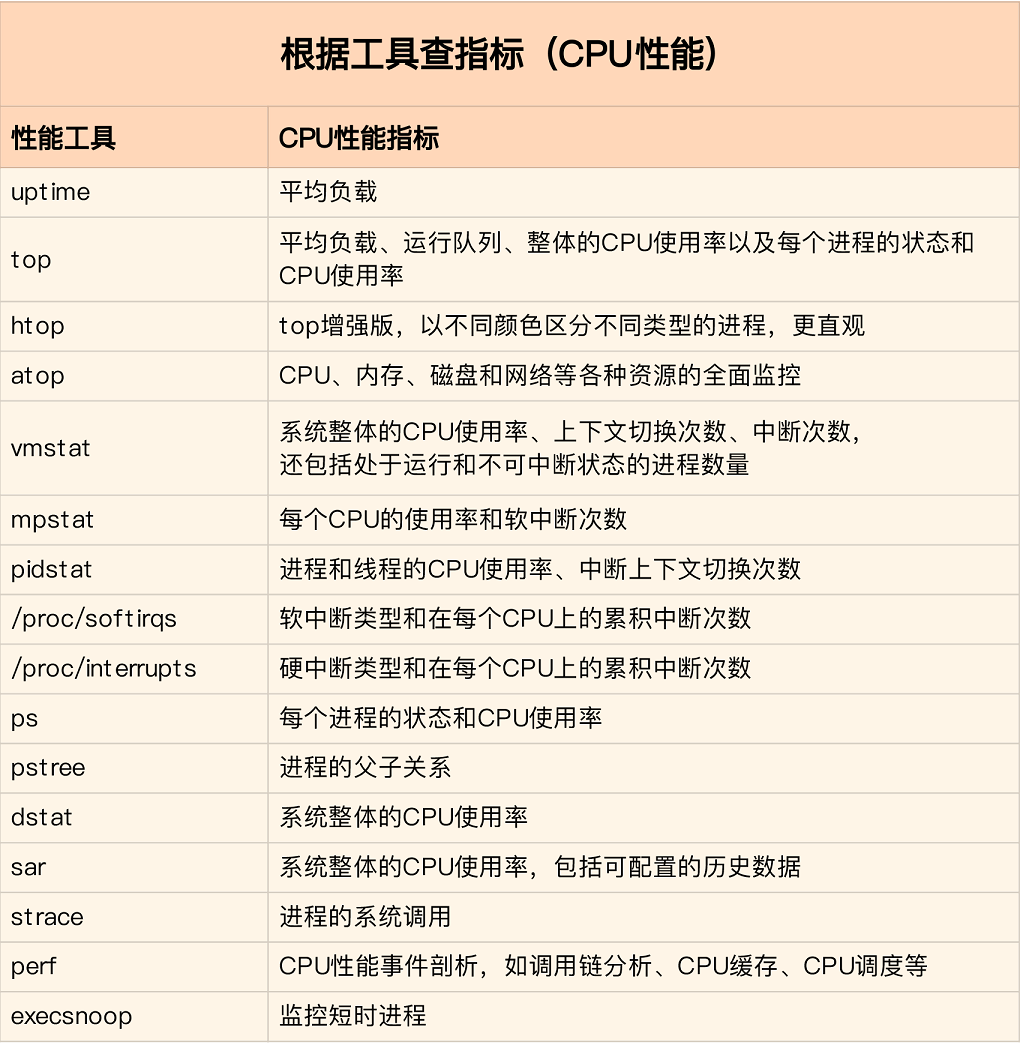
2. 排查工具

3. 排查过程
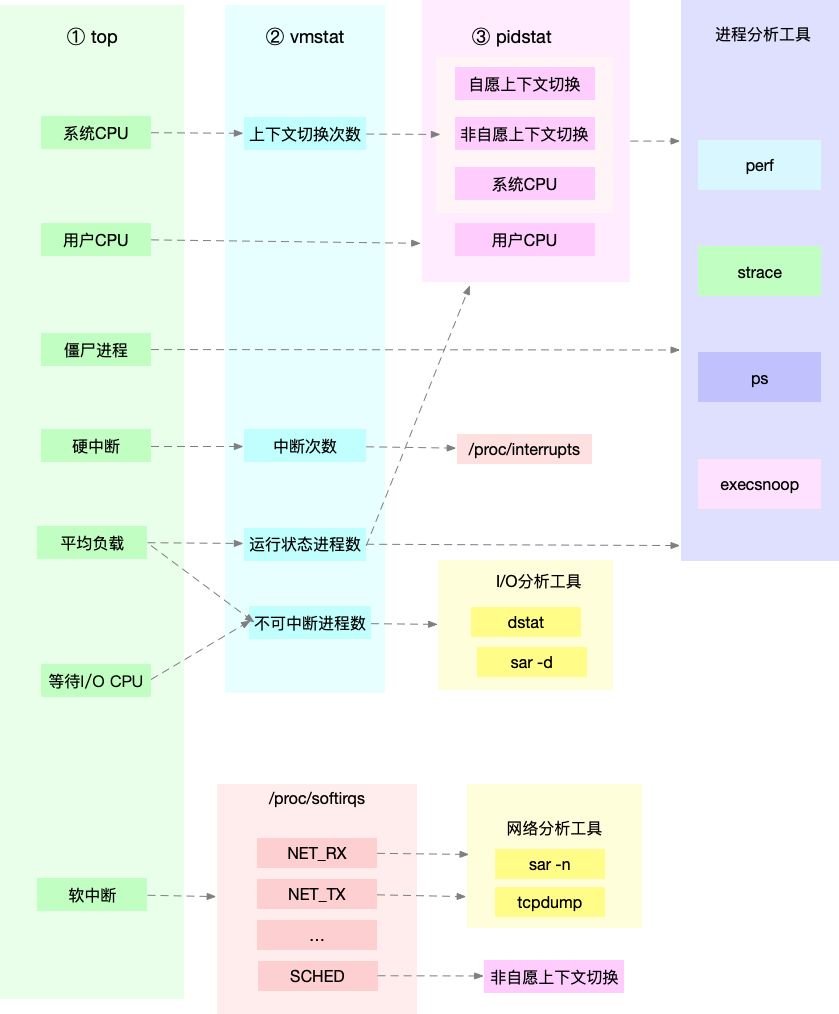
- 从 top 的输出可以得到各种 CPU 使用率以及僵尸进程和平均负载等信息。
- 从 vmstat 的输出可以得到上下文切换次数、中断次数、运行状态和不可中断状态的进程数。
- 从 pidstat 的输出可以得到进程的用户 CPU 使用率、系统 CPU 使用率、以及自愿上下文切换和非自愿上下文切换情况。
当发现 top 输出的用户 CPU 使用率有问题时,可以跟 pidstat 的输出做对比,观察是否是某个进程导致的问题。
top 输出的平均负载升高,可以跟 vmstat 输出的运行状态和不可中断状态的进程数做对比,观察是哪种进程导致的负载升高。如果是不可中断进程数增多了,那么就需要做 I/O 的分析,也就是用 dstat 或 sar 等工具,进一步分析 I/O 的情况。如果是运行状态进程数增多了,那就需要回到 top 和 pidstat,找出这些处于运行状态的到底是什么进程,然后再用进程分析工具,做进一步分析。
发现 top 输出的软中断 CPU 使用率升高时,可以查看 /proc/softirqs 文件中各种类型软中断的变化情况,确定到底是哪种软中断出的问题。比如,发现是网络接收中断导致的问题,那就可以继续用网络分析工具 sar 和 tcpdump 来分析。
4. 上下文切换
4.1. 查看上下文切换
通过vmstat可以查看系统总体的上下文切换情况
# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 2478264 78460 697404 0 0 56 12 57 95 0 0 100 0 0
system:system 有 in 和 cs 列,它报告每秒的系统操作。
in:每秒的系统中断数,包括时钟中断。cs:每秒上下文切换的次数。
pidstat 查看每个进程的情况
# 每隔5秒输出1组数据
# pidstat -w 5
Linux 5.4.0-62-generic (server-1) 01/20/2021 _x86_64_ (4 CPU)
05:59:02 AM UID PID cswch/s nvcswch/s Command
05:59:07 AM 0 7 5.59 0.00 kworker/0:1-events
05:59:07 AM 0 11 20.16 0.00 rcu_sched
05:59:07 AM 0 12 0.20 0.00 migration/0
05:59:07 AM 0 17 0.20 0.00 migration/1
05:59:07 AM 0 23 0.20 0.00 migration/2
05:59:07 AM 0 24 0.20 0.00 ksoftirqd/2
这个结果中有两列内容是我们的重点关注对象。一个是 cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,另一个则是 nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
-
所谓自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
-
而非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
4.2. 案例
使用 sysbench 来模拟系统多线程调度切换的情况
安装 sysbench 和 sysstat 包
apt install sysbench sysstat
以10个线程运行5分钟的基准测试,模拟多线程切换的问题
sysbench --threads=10 --max-time=300 threads run
运行 vmstat ,观察上下文切换情况
# vmstat 1 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 2481288 78908 697456 0 0 51 11 56 95 0 0 100 0 0
# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 0 2464260 79012 702260 0 0 50 11 192 1373 0 1 99 0 0
# vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 0 2464268 79020 702260 0 0 50 11 213 2075 0 1 99 0 0
4 0 0 2464260 79028 702260 0 0 0 5 38737 1237741 26 48 26 0 0
6 0 0 2464260 79028 702260 0 0 0 4 38399 1317551 29 45 26 0 0
4 0 0 2464008 79036 702260 0 0 0 4 37870 1200862 29 47 25 0 0
5 0 0 2464008 79044 702264 0 0 0 4 38405 1269030 27 47 25 0 0
3 0 0 2464008 79044 702264 0 0 0 0 35321 1214866 29 47 24 0 0
6 0 0 2464008 79052 702264 0 0 0 4 37890 1228229 28 48 24 0 0
6 0 0 2464008 79060 702264 0 0 0 38 37974 1254277 30 46 24 0 0
6 0 0 2464008 79068 702264 0 0 0 5 36275 1186124 30 46 24 0 0
4 0 0 2464008 79076 702264 0 0 0 8 35831 1210879 29 48 23 0 0
5 0 0 2463652 79084 702256 0 0 0 6 37244 1214750 28 47 25 0 0
7 0 0 2463756 79084 702268 0 0 0 0 34370 1211574 30 47 23 0 0
6 0 0 2463756 79092 702268 0 0 0 4 37001 1274843 29 47 24 0 0
6 0 0 2463756 79100 702268 0 0 0 4 37587 1252910 29 47 24 0 0
6 0 0 2463756 79108 702268 0 0 0 34 38523 1254058 28 47 26 0 0
可以发现cs 列的上下文切换次数飙升到了100多万
同时,注意观察其他几个指标:
- r 列:就绪队列的长度已经到了 6,远远超过了系统 CPU 的个数 4,所以肯定会有大量的 CPU 竞争。
- us(user)和 sy(system)列:其中系统 CPU 使用率,也就是 sy 列高达 47%,说明 CPU 主要是被内核占用了。
- in 列:中断次数也上升到了 3 万左右,说明中断处理也是个潜在的问题。
综合这几个指标,我们可以知道,系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高
到底是什么进程导致了这些问题呢?
用 pidstat 来看一下, CPU 和进程上下文切换的情况
# -w参数表示输出进程切换指标,而-u参数则表示输出CPU使用指标
# pidstat -w -u 10
Linux 5.4.0-62-generic (server-1) 01/20/2021 _x86_64_ (4 CPU)
06:08:28 AM UID PID %usr %system %guest %wait %CPU CPU Command
06:08:38 AM 0 7 0.00 0.10 0.00 0.00 0.10 0 kworker/0:1-events
06:08:38 AM 0 275 0.10 0.00 0.00 0.00 0.10 1 irq/16-vmwgfx
06:08:38 AM 0 759 0.00 0.10 0.00 0.00 0.10 0 vmtoolsd
06:08:38 AM 112 973 0.00 0.20 0.00 0.00 0.20 1 mysqld
06:08:38 AM 0 2053 0.00 0.10 0.00 0.00 0.10 3 kworker/u256:0-events_power_efficient
06:08:38 AM 0 3411 0.00 0.10 0.00 0.00 0.10 2 kworker/2:0-events
06:08:38 AM 0 4048 137.66 224.78 0.00 0.00 362.44 1 sysbench
06:08:38 AM 0 4061 0.00 0.10 0.00 0.00 0.10 0 pidstat
06:08:28 AM UID PID cswch/s nvcswch/s Command
06:08:38 AM 0 7 6.29 0.00 kworker/0:1-events
06:08:38 AM 0 10 0.30 0.00 ksoftirqd/0
06:08:38 AM 0 11 27.27 0.00 rcu_sched
06:08:38 AM 0 12 0.30 0.00 migration/0
06:08:38 AM 0 17 0.30 0.00 migration/1
06:08:38 AM 0 18 0.10 0.00 ksoftirqd/1
06:08:38 AM 0 23 0.30 0.00 migration/2
06:08:38 AM 0 24 0.20 0.00 ksoftirqd/2
06:08:38 AM 0 29 0.30 0.00 migration/3
06:08:38 AM 0 275 4.60 0.00 irq/16-vmwgfx
06:08:38 AM 0 344 0.10 0.00 kworker/2:1H-kblockd
06:08:38 AM 0 354 0.20 0.00 kworker/0:1H-kblockd
06:08:38 AM 0 417 0.20 0.00 kworker/1:1H-kblockd
06:08:38 AM 0 430 0.30 0.00 jbd2/dm-0-8
06:08:38 AM 0 432 0.10 0.00 kworker/3:1H-kblockd
06:08:38 AM 0 500 0.50 0.30 systemd-journal
06:08:38 AM 0 713 1.20 0.00 multipathd
06:08:38 AM 0 759 11.89 0.00 vmtoolsd
06:08:38 AM 0 778 2.00 0.00 kworker/3:4-events
06:08:38 AM 0 868 0.10 0.00 irqbalance
06:08:38 AM 0 1406 0.30 0.00 sshd
06:08:38 AM 0 2053 5.19 0.00 kworker/u256:0-events_power_efficient
06:08:38 AM 0 2902 8.19 0.10 kworker/1:1-events
06:08:38 AM 0 3411 3.90 0.00 kworker/2:0-events
06:08:38 AM 0 3738 9.39 0.00 kworker/u256:1-events_power_efficient
06:08:38 AM 0 3746 0.20 0.10 vmstat
06:08:38 AM 0 4061 0.10 0.10 pidstat
从 pidstat 的输出你可以发现,CPU 使用率的升高果然是 sysbench 导致的,它的 CPU 使用率已经达到了 100%。但上下文切换则是来自其他进程。sysbench的上下文切换此时
pidstat 默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标。
加上-t参数后,可以看到虽然 sysbench 进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多。看来,上下文切换罪魁祸首,还是过多的 sysbench 线程。
06:15:21 AM UID TGID TID %usr %system %guest %wait %CPU CPU Command
...
06:15:26 AM 0 3848 - 0.20 0.00 0.00 0.00 0.20 2 sshd
06:15:26 AM 0 - 3848 0.20 0.00 0.00 0.00 0.20 2 |__sshd
06:15:26 AM 0 4215 - 135.80 226.60 0.00 0.00 362.40 1 sysbench
06:15:26 AM 0 - 4216 15.20 21.60 0.00 15.60 36.80 2 |__sysbench
06:15:26 AM 0 - 4217 14.40 22.00 0.00 15.00 36.40 0 |__sysbench
06:15:26 AM 0 - 4218 12.20 23.40 0.00 16.20 35.60 3 |__sysbench
06:15:26 AM 0 - 4219 11.80 23.60 0.00 16.00 35.40 0 |__sysbench
06:15:26 AM 0 - 4220 14.00 22.20 0.00 15.00 36.20 2 |__sysbench
06:15:26 AM 0 - 4221 13.40 22.80 0.00 16.20 36.20 1 |__sysbench
06:15:26 AM 0 - 4222 12.60 23.40 0.00 14.60 36.00 2 |__sysbench
06:15:26 AM 0 - 4223 13.40 23.60 0.00 15.00 37.00 1 |__sysbench
06:15:26 AM 0 - 4224 13.00 23.00 0.00 15.80 36.00 1 |__sysbench
06:15:26 AM 0 - 4225 15.60 21.20 0.00 14.20 36.80 0 |__sysbench
06:15:21 AM UID TGID TID cswch/s nvcswch/s Command
...
06:15:26 AM 0 - 4216 27409.60 97346.60 |__sysbench
06:15:26 AM 0 - 4217 27027.80 85588.20 |__sysbench
06:15:26 AM 0 - 4218 27240.60 101332.40 |__sysbench
06:15:26 AM 0 - 4219 28357.60 105195.00 |__sysbench
06:15:26 AM 0 - 4220 27338.20 88289.20 |__sysbench
06:15:26 AM 0 - 4221 26175.80 101377.60 |__sysbench
06:15:26 AM 0 - 4222 26723.80 85640.20 |__sysbench
06:15:26 AM 0 - 4223 26702.60 88723.80 |__sysbench
06:15:26 AM 0 - 4224 26750.80 99777.80 |__sysbench
06:15:26 AM 0 - 4225 27905.80 80694.00 |__sysbench
06:15:26 AM 0 4232 - 0.20 109.20 pidstat
06:15:26 AM 0 - 4232 0.20 109.20 |__pidstat
06:15:26 AM 0 4233 - 22.00 6.60 sshd
06:15:26 AM 0 - 4233 22.00 6.60 |__sshd
06:15:26 AM 0 4443 - 0.20 151.00 pidstat
06:15:26 AM 0 - 4443 0.20 151.00 |__pidstat
观察中断的变化情况
# -d 参数表示高亮显示变化的区域
# watch -d cat /proc/interrupts
Every 2.0s: cat /proc/interrupts server-1: Wed Jan 20 06:35:10 2021
CPU0 CPU1 CPU2 CPU3
0: 3 0 0 0 IO-APIC 2-edge timer
1: 0 0 0 9 IO-APIC 1-edge i8042
6: 0 93 0 0 IO-APIC 6-edge floppy
8: 1 0 0 0 IO-APIC 8-edge rtc0
9: 0 0 0 0 IO-APIC 9-fasteoi acpi
12: 0 0 15 0 IO-APIC 12-edge i8042
14: 0 0 0 0 IO-APIC 14-edge ata_piix
15: 0 0 0 0 IO-APIC 15-edge ata_piix
16: 0 24589 0 123 IO-APIC 16-fasteoi vmwgfx, snd_ens1371
17: 24760 0 0 0 IO-APIC 17-fasteoi ehci_hcd:usb1, ioc0
18: 0 66 0 0 IO-APIC 18-fasteoi uhci_hcd:usb2
19: 0 0 55 20603 IO-APIC 19-fasteoi ens33
读取interrupts会依次显示irq编号,每个cpu对该irq的处理次数,中断控制器的名字,irq的名字,以及驱动程序注册该irq时使用的名字。
/proc/irq目录下面会为每个注册的irq创建一个以irq编号为名字的子目录,每个子目录下分别有以下条目:
- smp_affinity irq和cpu之间的亲缘绑定关系;
- smp_affinity_hint 只读条目,用于用户空间做irq平衡只用;
- spurious 可以获得该irq被处理和未被处理的次数的统计信息;
- handler_name 驱动程序注册该irq时传入的处理程序的名字;
# ls /proc/irq/0/
affinity_hint effective_affinity effective_affinity_list node smp_affinity smp_affinity_list spurious
如果想查看具体某个进程的上下文切换总情况,可以在/proc接口下直接看,不过这个是总值。
# grep switches /proc/973/status
voluntary_ctxt_switches: 388
nonvoluntary_ctxt_switches: 113
4.3. 总结
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题;
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈;
- 中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。
5. CPU 使用率
5.1. 使用率计算
Linux 作为一个多任务操作系统,将每个 CPU 的时间划分为很短的时间片,再通过调度器轮流分配给各个任务使用,因此造成多任务同时运行的错觉。为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiffies 记录了开机以来的节拍数。每发生一次时间中断,Jiffies 的值就加 1。
节拍率 HZ 是内核的可配选项,可以设置为 100、250、1000 等。不同的系统可能设置不同数值,你可以通过查询 /boot/config 内核选项来查看它的配置值。例如节拍率设置成了 250,也就是每秒钟触发 250 次时间中断。
# grep CONFIG_HZ /boot/config-$(uname -r)
# CONFIG_HZ_PERIODIC is not set
# CONFIG_HZ_100 is not set
CONFIG_HZ_250=y
# CONFIG_HZ_300 is not set
# CONFIG_HZ_1000 is not set
CONFIG_HZ=250
同时,正因为节拍率 HZ 是内核选项,所以用户空间程序并不能直接访问。为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,它总是固定为 100,也就是 1/100 秒。这样,用户空间程序并不需要关心内核中 HZ 被设置成了多少,因为它看到的总是固定值 USER_HZ。
Linux 通过 /proc 虚拟文件系统,向用户空间提供了系统内部状态的信息,而 /proc/stat 提供的就是系统的 CPU 和任务统计信息。
# cat /proc/stat | grep ^cpu
cpu 81286 254 132723 1988754 241 0 268 0 0 0
cpu0 20427 70 33018 496850 41 0 127 0 0 0
cpu1 20387 31 33127 497200 131 0 70 0 0 0
cpu2 20186 71 33187 497381 32 0 36 0 0 0
cpu3 20286 81 33390 497321 36 0 34 0 0 0
第一列表示的是 CPU 编号,如 cpu0、cpu1 ,而第一行没有编号的 cpu ,表示的是所有 CPU 的累加。其他列则表示不同场景下 CPU 的累加节拍数,它的单位是 USER_HZ,也就是 10 ms(1/100 秒),所以这其实就是不同场景下的 CPU 时间。
一些重要指标
- user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
- system(通常缩写为 sys),代表内核态 CPU 时间。
- idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
- iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
- irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
- softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
- steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
- guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
- guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比,用公式来表示就是:
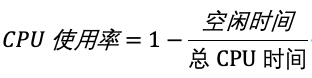
根据这个公式,我们就可以从 /proc/stat 中的数据,很容易地计算出 CPU 使用率。当然,也可以用每一个场景的 CPU 时间,除以总的 CPU 时间,计算出每个场景的 CPU 使用率.
事实上,为了计算 CPU 使用率,性能工具一般都会取间隔一段时间(比如 3 秒)的两次值,作差后,再计算出这段时间内的平均 CPU 使用率,即

这个公式,就是我们用各种性能工具所看到的 CPU 使用率的实际计算方法。现在,我们知道了系统 CPU 使用率的计算方法,那进程的呢?跟系统的指标类似,Linux 也给每个进程提供了运行情况的统计信息,也就是 /proc/[pid]/stat
# cat /proc/973/stat
973 (mysqld) S 1 973 973 0 -1 4194560 95829 0 286 0 222 1117 0 0 20 0 37 0 1051 2123689984 97069 18446744073709551615 94446528815104 94446591063376 140732488853840 0 0 0 543239 4096 9448 0 0 0 17 1 0 0 17 0 0 94446592556896 94446596241728 94446620098560 140732488859344 140732488859361 140732488859361 140732488859623 0
线程cpu的统计值位于/proc/{pid}/task/{threadId}/stat下:
# cat /proc/973/task/1116/stat
1116 (mysqld) S 1 973 973 0 -1 4194368 1 0 0 0 26 0 0 0 20 0 37 0 1183 2123689984 97069 18446744073709551615 94446528815104 94446591063376 140732488853840 0 0 0 543239 4096 9448 1 0 0 -1 3 0 0 0 0 0 94446592556896 94446596241728 94446620098560 140732488859344 140732488859361 140732488859361 140732488859623 0
5.2. 查看使用率
- top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。
- ps 则只显示了每个进程的资源使用情况。
top
# top
top - 06:52:31 up 1:42, 4 users, load average: 0.01, 0.02, 0.24
Tasks: 234 total, 1 running, 233 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.1 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3907.9 total, 2369.9 free, 761.7 used, 776.4 buff/cache
MiB Swap: 3908.0 total, 3908.0 free, 0.0 used. 2896.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
759 root 0 -20 161120 7188 6104 S 0.3 0.2 0:03.66 vmtoolsd
973 mysql 20 0 2073916 388276 39060 S 0.3 9.7 0:12.92 mysqld
3411 root 20 0 0 0 0 I 0.3 0.0 0:01.41 kworker/2:0-events
4028 root 20 0 0 0 0 I 0.3 0.0 0:01.67 kworker/u25
top的细节参考https://edgar615.github.io/linux-monitor-top.html
top 并没有细分进程的用户态 CPU 和内核态 CPU,要看更具体的信息,可以通过pidstat
# 每隔1秒输出一组数据,共输出5组
# pidstat 1 5
Linux 5.4.0-62-generic (server-1) 01/20/2021 _x86_64_ (4 CPU)
07:00:08 AM UID PID %usr %system %guest %wait %CPU CPU Command
07:00:09 AM 0 759 0.00 1.00 0.00 0.00 1.00 3 vmtoolsd
07:00:09 AM 0 8947 0.00 1.00 0.00 0.00 1.00 2 pidstat
07:00:09 AM UID PID %usr %system %guest %wait %CPU CPU Command
07:00:10 AM 0 8947 0.00 1.00 0.00 0.00 1.00 2 pidstat
07:00:10 AM UID PID %usr %system %guest %wait %CPU CPU Command
07:00:11 AM UID PID %usr %system %guest %wait %CPU CPU Command
07:00:12 AM 112 973 0.00 1.00 0.00 0.00 1.00 1 mysqld
07:00:12 AM 0 8947 0.00 1.00 0.00 0.00 1.00 2 pidstat
07:00:12 AM UID PID %usr %system %guest %wait %CPU CPU Command
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 759 0.00 0.20 0.00 0.00 0.20 - vmtoolsd
Average: 112 973 0.00 0.20 0.00 0.00 0.20 - mysqld
Average: 0 8947 0.00 0.60 0.00 0.00 0.60 - pidstat
perf
perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
安装
apt -y install linux-tools-generic
perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数
# perf top
Samples: 794 of event 'cpu-clock:pppH', 4000 Hz, Event count (approx.): 131461888 lost: 0/0 drop: 0/0
Overhead Shared Object Symbol
20.85% [kernel] [k] __lock_text_start
13.71% perf [.] __symbols__insert
8.12% [kernel] [k] e1000_xmit_frame
7.80% perf [.] rb_next
4.16% [kernel] [k] clear_page_orig
2.34% [kernel] [k] module_get_kallsym
2.25% [kernel] [k] e1000_clean
1.87% [kernel] [k] queue_work_on
1.56% perf [.] rb_insert_color
1.34% [kernel] [k] kallsyms_expand_symbol.constprop.0
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。比如这个例子中,perf 总共采集了 794 个 CPU 时钟事件,而总事件数则为 131461888。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
- 第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
- 第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
- 第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
- 最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示
# perf record # 按Ctrl+C终止采样
[ perf record: Woken up 44 times to write data ]
[ perf record: Captured and wrote 11.855 MB perf.data (253566 samples) ]
# perf report # 展示类似于perf top的报告
我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题
5.3. 案例
top - 07:39:37 up 2:29, 4 users, load average: 4.26, 1.56, 0.56
Tasks: 253 total, 6 running, 247 sleeping, 0 stopped, 0 zombie
%Cpu0 : 97.7 us, 1.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.7 si, 0.0 st
%Cpu1 : 97.0 us, 2.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 1.0 si, 0.0 st
%Cpu2 : 98.0 us, 1.0 sy, 0.0 ni, 0.3 id, 0.0 wa, 0.0 hi, 0.7 si, 0.0 st
%Cpu3 : 96.0 us, 2.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 2.0 si, 0.0 st
MiB Mem : 3907.9 total, 1538.4 free, 846.0 used, 1523.6 buff/cache
MiB Swap: 3908.0 total, 3908.0 free, 0.0 used. 2779.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
11255 daemon 20 0 336692 13088 5412 R 80.4 0.3 1:03.88 php-fpm
11254 daemon 20 0 336692 13088 5412 R 79.7 0.3 1:04.18 php-fpm
11257 daemon 20 0 336692 16248 8572 R 79.4 0.4 1:03.50 php-fpm
11256 daemon 20 0 336692 13024 5348 R 77.7 0.3 1:03.64 php-fpm
11258 daemon 20 0 336692 13024 5348 R 76.1 0.3 1:04.78 php-fpm
11019 systemd+ 20 0 34016 4536 2280 S 1.7 0.1 0:02.03 nginx
1002 root 20 0 1315896 110060 51340 S 1.3 2.8 0:13.57 dockerd
perf查看哪个函数导致了 CPU 使用率升高
# -g开启调用关系分析,-p指定php-fpm的进程号11255
$ perf top -g -p 11255
按方向键切换到 php-fpm,再按下回车键展开 php-fpm 的调用关系,找到对应函数。
6. 软中断
top - 08:20:13 up 3:09, 4 users, load average: 0.06, 0.08, 0.36
Tasks: 251 total, 2 running, 249 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.3 us, 0.3 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu2 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 0.0 sy, 0.0 ni, 34.1 id, 0.0 wa, 0.0 hi, 65.9 si, 0.0 st
MiB Mem : 3907.9 total, 1291.9 free, 849.5 used, 1766.5 buff/cache
MiB Swap: 3908.0 total, 3908.0 free, 0.0 used. 2788.7 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
30 root 20 0 0 0 0 R 8.6 0.0 0:08.51 ksoftirqd/3
888 root 20 0 1120812 49000 26956 S 0.7 1.2 0:39.87 containerd
713 root rt 0 345796 18196 8284 S 0.3 0.5 0:05.08 multipathd
873 syslog 20 0 224324 5660 3832 S 0.3 0.1 0:00.99 rsyslogd
通过65.9 si可以发现,系统发送了软中断。而CPU使用率最高的也是软中断进程
30 root 20 0 0 0 0 S 5.3 0.0 0:12.22 ksoftirqd/3
通过/proc/softirqs观察中断变化频率
# watch -d cat /proc/softirqs
Every 2.0s: cat /proc/softirqs server-1: Wed Jan 20 08:23:46 2021
CPU0 CPU1 CPU2 CPU3
TIMER: 519376 419087 421025 473029
NET_TX: 19 10 2195 45
NET_RX: 54896 47633 50567 8444939
BLOCK: 53416 329 12114 318
TASKLET: 1624 40 1 963
SCHED: 339235 244227 241522 251107
RCU: 307974 298292 293993 626377
你可以发现, TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁)等这几个软中断都在不停变化。
其中,NET_RX,也就是网络数据包接收软中断的变化速率最快。而其他几种类型的软中断,是保证 Linux 调度、时钟和临界区保护这些正常工作所必需的,所以它们有一定的变化倒是正常的。
接下来我们通过sar分析网络接收的软中断
sar 可以用来查看系统的网络收发情况,还有一个好处是,不仅可以观察网络收发的吞吐量(BPS,每秒收发的字节数),还可以观察网络收发的 PPS,即每秒收发的网络帧数。
# sar -n DEV 1
Linux 5.4.0-62-generic (server-1) 01/20/2021 _x86_64_ (4 CPU)
08:26:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
08:26:50 AM br-6d212538ddbf 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:26:50 AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:26:50 AM ens33 25969.00 12984.00 1521.62 760.88 0.00 0.00 0.00 1.25
08:26:50 AM veth40f795e 12984.00 25968.00 735.41 1369.39 0.00 0.00 0.00 0.11
08:26:50 AM docker0 12984.00 25968.00 557.89 1369.39 0.00 0.00 0.00 0.00
08:26:50 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
08:26:51 AM br-6d212538ddbf 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:26:51 AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:26:51 AM ens33 25774.00 12890.00 1510.28 755.70 0.00 0.00 0.00 1.24
08:26:51 AM veth40f795e 12885.00 25769.00 729.81 1358.91 0.00 0.00 0.00 0.11
08:26:51 AM docker0 12885.00 25769.00 553.65 1358.91 0.00 0.00 0.00 0.00
- 第一列:表示报告的时间。
- 第二列:IFACE 表示网卡。
- 第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是 PPS。
- 第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS。
通过sar我们可以发现ens33每秒接收的网络帧数比较大,发送的网络帧数则比较小。而且BPS相对PPS来说比较小。
我们稍微计算一下,1510*1024/25774= 59 字节,说明平均每个网络帧只有 59 字节,这显然是很小的网络帧,也就是我们通常所说的小包问题。
接下来我们就要想办法知道这是一个什么样的网络帧,以及从哪里发过来的。
下面使用 tcpdump 抓取 ens33上的包就可以了。我们事先已经知道, Nginx 监听在 80 端口,它所提供的 HTTP 服务是基于 TCP 协议的,所以我们可以指定 TCP 协议和 80 端口精确抓包。
# -i eth0 只抓取eth0网卡,-n不解析协议名和主机名
# tcp port 80表示只抓取tcp协议并且端口号为80的网络帧
$ tcpdump -i ens33 -n tcp port 80
08:35:06.708146 IP 192.168.159.132.5314 > 192.168.159.131.80: Flags [R], seq 1214503484, win 0, length 0
08:35:06.708146 IP 192.168.159.132.5503 > 192.168.159.131.80: Flags [S], seq 1746361991, win 512, length 0
08:35:06.708146 IP 192.168.159.132.5315 > 192.168.159.131.80: Flags [R], seq 1615350817, win 0, length 0
08:35:06.708407 IP 192.168.159.132.5509 > 192.168.159.131.80: Flags [S], seq 986949918, win 512, length 0
08:35:06.708407 IP 192.168.159.132.5510 > 192.168.159.131.80: Flags [S], seq 574806384, win 512, length 0
08:35:06.708407 IP 192.168.159.132.5511 > 192.168.159.131.80: Flags [S], seq 1949585932, win 512, length 0
08:35:06.708452 IP 192.168.159.132.5517 > 192.168.159.131.80: Flags [S], seq 354236879, win 512, length 0
08:35:06.708496 IP 192.168.159.132.5524 > 192.168.159.131.80: Flags [S], seq 214370582, win 512, length 0
08:35:06.708496 IP 192.168.159.132.5318 > 192.168.159.131.80: Flags [R], seq 360044204, win 0, length 0
08:35:06.708496 IP 192.168.159.132.5525 > 192.168.159.131.80: Flags [S], seq 1644257155, win 512, length 0
08:35:06.708528 IP 192.168.159.132.5530 > 192.168.159.131.80: Flags [S], seq 1844130897, win 512, length 0
08:35:06.708528 IP 192.168.159.132.5319 > 192.168.159.131.80: Flags [R], seq 904888346, win 0, length 0
08:35:06.708549 IP 192.168.159.132.5533 > 192.168.159.131.80: Flags [S], seq 1579228269, win 512, length 0
08:35:06.708702 IP 192.168.159.132.5326 > 192.168.159.131.80: Flags [R], seq 2103907437, win 0, length 0
08:35:06.708702 IP 192.168.159.132.5539 > 192.168.159.131.80: Flags [S], seq 385935966, win 512, length 0
...
Flags [S] 则表示这是一个 SYN 包。现在我们可以确定就是从 192.168.159.131 这个地址发送过来的 SYN FLOOD 攻击。
7. IOWAIT
Tasks: 254 total, 1 running, 249 sleeping, 0 stopped, 4 zombie
%Cpu0 : 0.4 us, 32.0 sy, 0.0 ni, 57.2 id, 0.4 wa, 0.0 hi, 10.0 si, 0.0 st
%Cpu1 : 0.0 us, 29.9 sy, 0.0 ni, 50.8 id, 19.3 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 0.3 us, 0.3 sy, 0.0 ni, 96.7 id, 1.3 wa, 0.0 hi, 1.3 si, 0.0 st
%Cpu3 : 0.3 us, 17.5 sy, 0.0 ni, 63.9 id, 18.2 wa, 0.0 hi, 0.0 si, 0.0 st
发现CPU的IOWAI比较高。
使用dstat 命令,观察 CPU 和 I/O 的使用情况
# 间隔1秒输出10组数据
# dstat 1 10
You did not select any stats, using -cdngy by default.
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
8 3 89 0 0| 15M 117k| 0 0 | 0 0 |4676 87k
0 0 100 0 0| 0 0 | 60B 326B| 0 0 | 528 946
2 18 67 14 0| 862M 0 | 60B 166B| 0 0 |1036 795
4 36 42 19 0|1698M 0 | 126B 370B| 0 0 |1596 955
0 0 100 0 0| 0 48k| 60B 150B| 0 0 | 366 598
0 0 100 0 0| 0 0 | 60B 134B| 0 0 | 285 514
0 0 100 0 0| 0 0 | 60B 118B| 0 0 | 289 527
2 20 66 12 0| 809M 0 | 60B 118B| 0 0 | 879 710
3 42 36 18 0|1751M 0 | 60B 134B| 0 0 |1489 890
0 0 100 0 0| 0 24k| 60B 134B| 0 0 | 365 597
从 dstat 的输出,我们可以看到,每当 iowait 升高(wai)时,磁盘的读请求(read)都会很大。这说明 iowait 的升高跟磁盘的读请求有关,很可能就是磁盘读导致的。
通过top观察 D 状态(不可中断状态睡眠状态)的进程:
通过pidstat -d -p <pid>查找
# pidstat -d -p 15188 1 20
Linux 5.4.0-62-generic (server-1) 01/20/2021 _x86_64_ (4 CPU)
08:49:30 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
08:49:31 AM 0 15188 0.00 0.00 0.00 0 app
08:49:32 AM 0 15188 0.00 0.00 0.00 0 app
08:49:33 AM 0 15188 0.00 0.00 0.00 0 app
08:49:34 AM 0 15188 0.00 0.00 0.00 0 app
08:49:35 AM 0 15188 0.00 0.00 0.00 0 app
08:49:36 AM 0 15188 0.00 0.00 0.00 0 app
kB_rd 表示每秒读的 KB 数, kB_wr 表示每秒写的 KB 数,iodelay 表示 I/O 的延迟(单位是时钟周期)。它们都是 0,那就表示此时没有任何的读写,说明问题不是 15188进程导致的。
直接观察所有进程的 I/O 使用情况
# pidstat -d 1 20
Linux 5.4.0-62-generic (server-1) 01/20/2021 _x86_64_ (4 CPU)
08:50:28 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
08:50:29 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
08:50:30 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
08:50:31 AM 0 15264 589824.00 0.00 0.00 42 app
08:50:31 AM 0 15265 589824.00 0.00 0.00 42 app
可以看到app进程在执行IO操作
8. 参考资料
《Linux性能优化实战》
