1. 指标类型
1.1. 计数器(Counter)
计数器是一个数值单调递增的指标,一般这个值为 Double 或者 Long 类型。我们比较常见的有 Java 中的 AtomicLong、DoubleAdder,它们的值就是单调递增的。QPS 的值也是通过计数器的形式,然后配合上一些函数计算得出的。
1.2. 仪表盘(Gauge)
仪表盘和计数器都可以用来查询某个时间点的固定内容的数值,但和计数器不同,仪表盘的值可以随意变化,可以增加也可以减少。比如在 Java 线程池中活跃的线程数,就可以使用 ThreadPoolExecutor 的 getActiveCount 获取;比较常见的 CPU 使用率和内存占用量也可以通过仪表盘获取。

1.3. 直方图(Histogram)
直方图相对复杂一些,它是将多个数值聚合在一起的数据结构,可以表示数据的分布情况。
如下图,它可以将数据分成多个桶(Bucket),每个桶代表一个范围区间(图下横向数),比如第 1 个桶代表 0~10,第二个桶就代表 10~15,以此类推,最后一个桶代表 100 到正无穷。每个桶之间的数字大小可以是不同的,并没有规定要有规律。每个桶和一个数字挂钩(图左纵向数),代表了这个桶的数值。
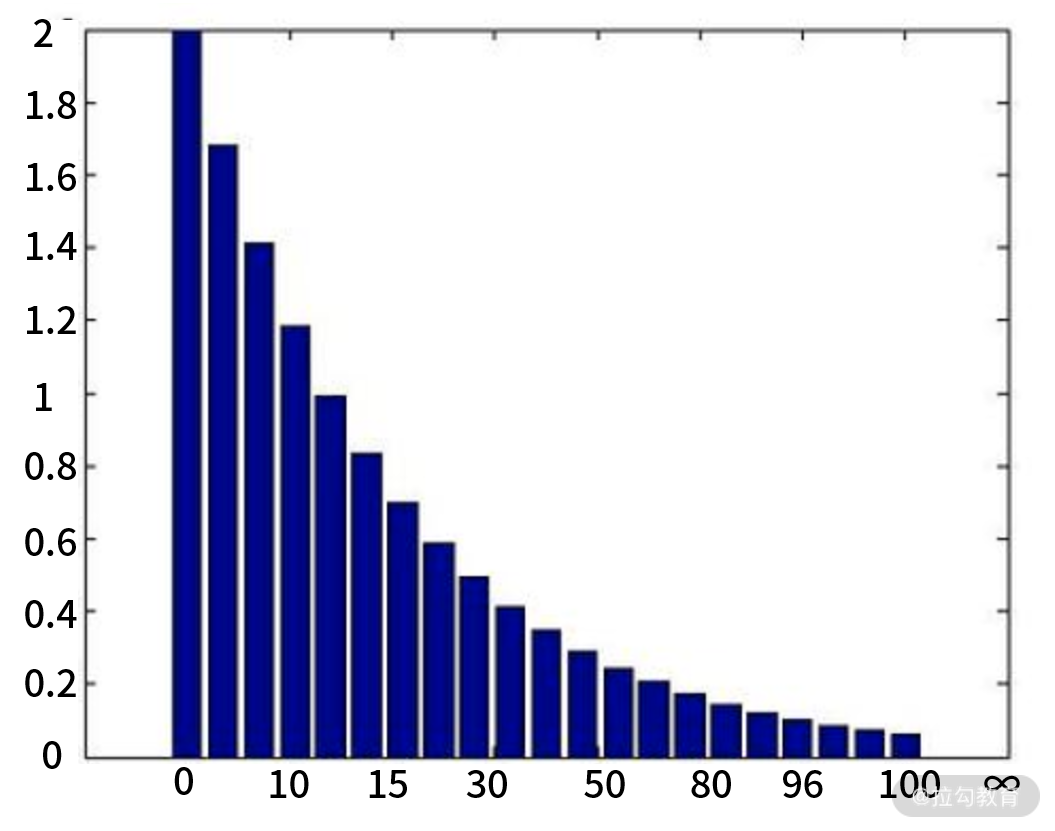
以最常见的响应耗时举例,我把响应耗时分为多个桶,比如我认为 0~100 毫秒比较快,就可以把这个范围做一个桶,然后是 100~150 毫秒,以此类推。通过这样的形式,可以直观地看到一个时间段内的请求耗时分布图,这有助于我们理解耗时情况分布。
举个例子:假设使用 Hitogram 来分析 API 调用的响应时间,使用数组 [30ms, 100ms, 300ms, 1s, 3s, 5s, 10s] 将响应时间分为 8 个区间。那么每次采集到响应时间,比如 200ms,那么对应的区间 (0, 30ms], (30ms, 100ms], (100ms, 300ms] 的计数都会加 1。最终以响应时间为横坐标,每个区间的计数值为纵坐标,就能得到 API 调用响应时间的累积直方图。
1.4. 摘要(Summary)
摘要与直方图类似,同样表示的是一段时间内的数据结果,但是数据反映的内容不太一样。摘要一般用于标识分位值,分位值就是我们常说的 TP90、TP99 等。
假设有 100 个耗时数值,将所有的数值从低到高排列,取第 90% 的位置,这个位置的值就是 TP90 的值,而这个桶的值假设是 80ms,那么就代表小于等于90%位置的请求都 ≤80ms。
用文字不太好理解,我们来看下面这张图。这是一张比较典型的分位值图,我们可以看到图中有 6 个桶,分别是 50、75、80、90、95、99,而桶的值就是相对应的耗时情况。

通过分位值图,我们可以看到最小值和最大值以外的一些数据,这些数据在系统调优的时候也有重要参考价值。
在这里面我需要补充一个知识点,叫作长尾效应。长尾效应是指少部分类数据在一个数据模型中占了大多数样本,在数据模型中呈现出长长的尾巴的现象。如图所示,最上面的 TP99 相当于这个图表的尾巴,可以看到,1% 用户访问的耗时比其他 5 个桶加起来的都要长。这个时候你如果通过指标查看某个接口的平均响应时间,其实意义不大,因为这 1% 的用户访问已经超出了平均响应时间,所以平均响应时间已经无法反映数据的真实情况了。这时用户会出现严重的量级分化,而量化分级也是我们在进行系统调优时需要着重关注的。
这种情况我们一般很难通过拨测、自己访问来复现。但我们通过观测这一部分内容,通过链路追踪的方式可以定位到问题的根源。
2. 常用指标
2.1. QPS
Query Per Second,每秒查询的数量。QPS 在系统中很常见,它不再是单单和“查询”这个特殊条件绑定。QPS 现在也与请求量挂钩,我们可以通过这个值查看某个接口的请求量。假设我们在 1 秒内进行了 1 次接口调用,就可以认为在这 1 秒内,QPS 增加了 1。如果系统进行过压测,那么也可以估算出 QPS 的峰值,从而预估系统的容量。
2.2. SLA
Service Level Agreement,服务等级协议。
https://edgar615.github.io/ha-sla.html
2.3. Apdex
Application Performance Index,应用性能指数。Apdex 会用响应耗时来判断用户对应用性能的满意度,并通过可量化的形式展现出来。通过这个量化的值,我们可以快速感知用户的满意程度。这也是首次和用户的使用体验相结合的一个指标。
Apdex 分为 3 个区间:
- 满意(Satisfactory):用户对于这样的响应时间是十分满意的,感觉十分流畅
- 容忍(Tolerating):稍微慢了一点儿,但是可以接受
- 失望(Frustrating):实在太慢,快要放弃了
这个衡量用户是否满意的值是怎样计算出来的呢?
它需要管理人员给一个时间单位 T,来表示当小于或等于多少秒的时候用户的感觉非常好的。映射到 3 个区间内,Apdex 规定,符合满意程度的是 1T,符合容忍程度的是 1T~4T,失望则大于 4T。通过这样的形式,我们就能得知当前请求是属于哪个区间的。
比如我们要计算某个时间段内的 Adpex 值,就可以通过这样的公式来计算:
(满意数量 + (容忍数量 / 2)) / 总数 = Apdex 值
通过这个公式,我们可以得出服务整体的 Apdex 值,这个值会在 0~1 的范围内。值越接近 1 代表用户的满意度越高。通过这样可自定义阈值的计算方式,如何衡量业务的满意度也有了一个可量化的标准。
3. 参考资料
《分布式链路追踪实战 》
