1. Monitoring
Monitoring(监控)举例来说就是:定期体检。使用监控系统把需要关注的指标采集起来,形成报告,并对需要关注的异常数据进行分析形成告警。
特点是:
- 低频
- 定期
- 定量
这也是Prometheus的架构做得非常简单的原因,Monitoring的需求并没有包含非常高的并发量和通讯量。反过来说:高并发、大数据量的需求并不适用于Monitoring这个点。
2. Tracing
Tracing(链路追踪)举例来说就是:对某一项工作的定期汇报。某个工作开始做了A,制作A事件的报告,收集起来,然后这个工作还有B、C、D等条目,一个个处理,然后都汇总进报告,最终的结果就是一个Tracing。
特点是:
- 高频
- 巨量
- 有固定格式
因为Tracing是针对某一个事件(一般来说就是一个API),而这个API可能会和很多组件进行沟通,后续的所有的组件沟通无论是内部还是外部的IO,都算作这个API调用的Tracing的一部分。可以想见在一个业务繁忙的系统中,API调用的数量已经是天文数字,而其衍生出来的Tracing记录更是不得了的量。其特点就是高频、巨量,一个API会衍生出大量的子调用。
也因此适合用来做Monitoring的系统就不一定适合做Tracing了,用Prometheus这样的系统来做Tracing肯定完蛋(Prometheus只有拉模式,全部都是HTTP请求,高并发直接挂掉)。一般来说Tracing系统都会在本地磁盘IO上做日志(最高效、也是最低的Cost),然后再通过本地Agent慢慢把文本日志数据发送到聚合服务器上,甚至可能在聚合服务器和本地的Agent之间还需要做消息队列,让聚合服务器慢慢消化巨量的消息。
Tracing在现在的业界是有标准的:OpenTracing,因此它不是很随意的日志/事件聚合,而是有格式要求的日志/事件聚合,这就是Tracing和Logging最大的不同。
3. Logging
Logging(日志)举例来说就是:废品回收站。各种各样的物品都会汇总进入到配品回收站里,然后经过分门别类归纳整理,成为各种可回收资源分别回收到商家那里。一般来说我们在大型系统中提到Logging说的都不是简单的日志,而是日志聚合系统。
从本质上来说,Monitoring和Tracing都是Logging,Logging是这三者中覆盖面最大的超集,而前两者则是其一部分的子集。Logging最麻烦的是,开发者也不会完全知道最后记录进入到日志系统里的一共会有哪些东西,只有在使用(检索)的时候才可能需要汇总查询总量中的一部分。
要在一般的Loggin系统中进行Monitoring也是可以的,直接把聚合进来的日志数据提取出来,定期形成数据报告,就是监控了。Tracing也是一样,只要聚合进了Logging系统,有了原始数据,后面要做都是可以做的。因此Logging系统最为通用,其特点和Tracing基本一致,也是需要处理高频并发和巨大的数据量。
4. 总结
这样一看就很清楚了,每个组件都有其存在的必要性:
- Monitoring系统(Prometheus)从根本的需求和基本设计上就不可能支持Tracing和Logging:低频 vs 高频、低量 vs 高量,其从设计到实现就只为了监控服务
- Tracing系统(Jaeger)对提供的数据有格式要求,且处理方式和一般的Logging也不同,有更限定的应用范围
- Logging系统(ELK)可以处理前两者的需求,但前两者的领域有更专业的工具就不推荐直接使用普通的日志聚合系统了;Logging系统一般用来处理大型系统的日志聚合以及检索查询

我们一般可以将数据的来源分为 2 个级别:
请求级别: 数据来源于真实的请求,比如一次 HTTP 调用,RPC 调用;
聚合级别: 真实的请求指标,或是系统的一些参数数据聚合,比如 QPS、CPU 数值。
根据这 2 个级别,我们可以对上面的 3 个内容加以细化,其中链路追踪是请求级别,因为它和每个请求都挂钩;日志和统计指标可以是请求级别,也可以是聚合级别,因为它们可能是真实的请求,也可能是系统在对自身诊断时记录下来的信息。
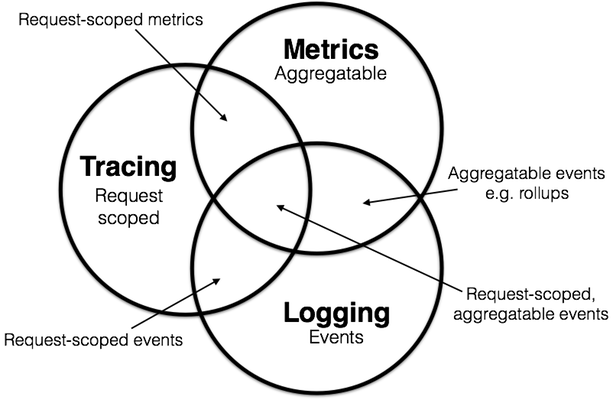

-
链路追踪+统计指标(Request-scoped metrics),请求级别的统计:在链路追踪的基础上,与相关的统计数据结合,从而得知数据与数据、应用与应用之间的关系。
-
链路追踪+日志(Request-scoped events),请求级别的事件:这是链路中一个比较常见的组合模式。日志本身是每一条单独存在的,将链路追踪收集到的信息集成在日志中,可以让日志之间具备关联性,使其具有除了事件维度以外的另一个新的维度,上下文信息。
-
日志+统计指标(Aggregatable events),聚合级别的事件:这是在日志中的比较常见的组合。通过解析这部分具有统计指标的信息,我们可以获取相关的指标数据。
-
三者结合(Request-scoped,aggregatable events):三者结合可以理解为请求级别+聚合级别的事件,由此就形成了一个丰富的、全局的观测体系。
根据以上这 3 个概念,我们再来想想它们最终会输出的数据量(Volume)。
统计指标是数值的形式,同时又可以压缩,所以它所需的存储量是最小的;日志的输出量最大,但相对的,它也有比较全的内容记录;链路追踪则正好处于二者之间,它不会像日志一样大量地输出,也不像统计指标一样节能。
5. 参考资料
https://xenojoshua.com/2019/04/monitoring-tracing-logging/
http://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
《分布式链路追踪实战 》
