1. 哈希索引
哈希表是数组+链表的形式。通过哈希函数计算每个节点数据中键所对应的哈希桶位置,如果出现哈希冲突,就用拉链法来解决
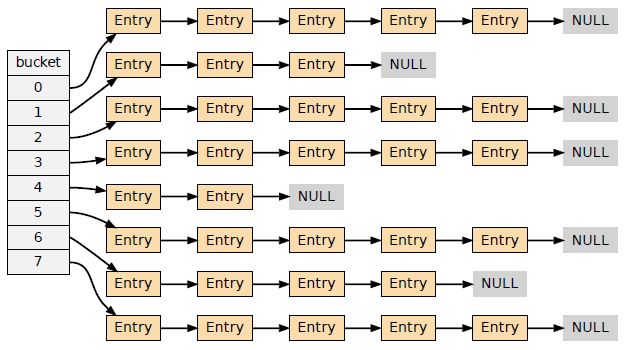
哈希索引是基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),哈希码是一个较小的值,大部分情况下不同的键值的行计算出来的哈希码是不同的,但是也会有例外,就是说不同列值计算出来的hash值一样的(即所谓的hash冲突),哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每一个数据行的指针,hash很适合做索引,为某一列或几列建立hash索引,就会利用这一列或几列的值通过一定的算法计算出一个hash值,对应一行或几行数据。
从网上找的一个图

哈希索引检索时不需要想B+Tree那样从根结点开始查找,而是经过计算直接定位,所以速度很快。
但是也有限制:
- 只支持精确查找,不能用于部分查找和范围查找。无法排序和分组。因为原来有序的键值经过哈希算法很可能打乱。
- 如果哈希冲突很多,查找速度很慢。比如在有大量重复键值的情况下。因为这时需要根据hash值找的存储数据的物理位置,然后依次遍历这些数据,找到需要的数据
Mermory默认的索引是Hash索引。
2. 自适应哈希索引
看完前面文章介绍的索引,我们 可以知道innodb使用的索引结构是B+树,但其实它还支持另一种索引:自适应哈希索引
哈希索引查找最优情况下是查找一次,而B+树最优情况下的查找次数根据层数决定,因此为了提高查询效率,InnoDB允许使用自适应哈希索引来提高性能
- 随着MySQL单表数据量增大,(尽管B+树算法极好地控制了树的层数)索引B+树的层数会逐渐增多;
- 随着索引树层数增多,检索某一个数据页需要沿着B+树从上往下逐层定位,时间成本就会上升;
- 为解决检索成本问题,MySQL就想到使用某一种缓存结构:根据某个检索条件,直接查询到对应的数据页,跳过逐层定位的步骤。这种缓存结构就是AHI。
Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,二级索引成为热数据,如果认为建立哈希索引可以提高查询效率,则自动在内存中的 自适应哈希索引缓冲区 建立哈希索引。
存储引擎会自动对索引页上的查询进行监控,如果能够通过自适应哈希索引来提高效率,便会自动创建自适应哈希索引,不需要开发人员或者运维人员做任何操作。它是对缓冲池中的 B+ 树页进行创建,且不需要对整个表建立哈希索引,因此它的速度非常快。
可以通过 innodb_adaptive_hash_index 变量决定是否打开该特性(默认开启),通过 AHI 可以有效提高读取、写入、join 的速度。
mysql> show variables like "innodb_adaptive_hash_index";
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_adaptive_hash_index | ON |
+----------------------------+-------+
1 row in set (0.05 sec)
3. 原理解析
这一章完全摘自https://mp.weixin.qq.com/s/oXezJr5jkbE-fD7THao6CQ
AHI在实现上就是一个哈希表:从某个检索条件到某个数据页的哈希表,仿佛并不复杂,但其中的关窍在于哈希表不能太大(哈希表维护本身就有成本,哈希表太大则成本会高于收益),又不能太小(太小则缓存命中率太低,没有任何收益)。
这就是AHI(中文名:自适应哈希索引)中"自适应"的用途:建立一个"不大不小刚刚好"的哈希表。
MySQL是如何建立起一个"刚刚好"的AHI的?,如下图所示:需要经历三个关卡,才能为某个数据页建立AHI,之后的查询才能使用到该AHI。

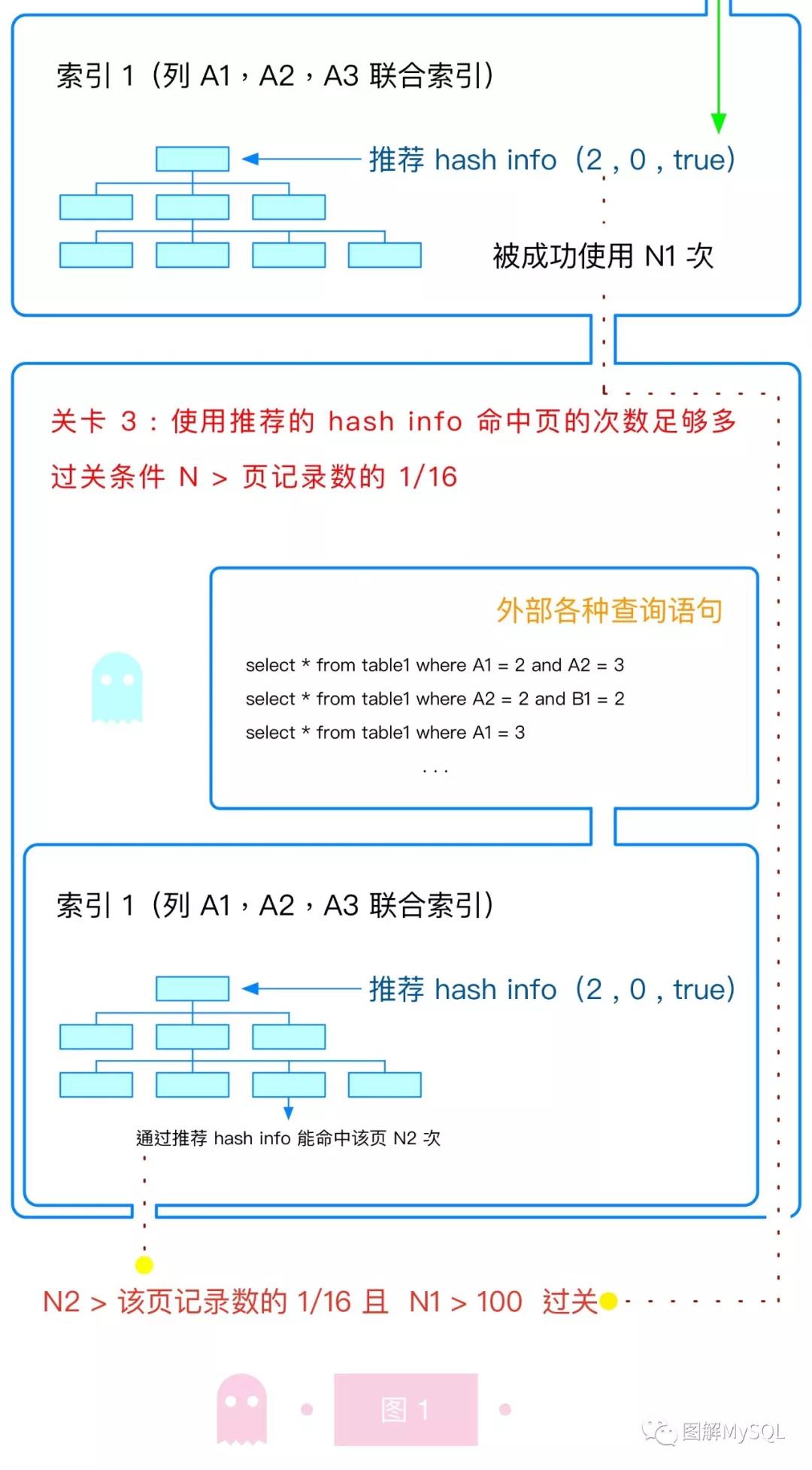
我们逐个关卡来介绍:
关卡1:某个索引树要被使用足够多次
AHI是为某个索引树建立的(当该索引树层数过多时,AHI才能发挥效用)。如果某索引只被使用一两次,就为之建立AHI,会导致AHI太多,维护成本高于收益。
因此建立AHI的第一关就是:只为频繁使用的索引树建立AHI。
关卡2:该索引树上的某个检索条件要被经常使用
显而易见,如果我们为了一个很少出现的检索条件建立AHI,肯定是入不敷出的。
在此我们插播一个新概念hash info,hash info是用来描述一次检索的条件与索引匹配程度(即此次检索是如何使用索引的)。建立AHI时,就可以根据匹配程度,抽取数据中匹配的部分,作为AHI的键。
关卡2就是为了找到经常使用的hash info。hash info 包括以下三项:
- 检索条件与索引匹配的列数
- 第一个不匹配的列中,两者匹配的字节数
- 匹配的方向是否从左往右进行
我们通过一个例子来简要介绍hash info中第一项。假设一张表table1,其索引是(A1, A2)两列构成的索引:
- 如果检索条件是(A1=1 and A2=1),那么此次检索使用了该索引的最左两列,hash info就是(2,0,true)
- 如果检索条件是(A1=1), 那么此次检索使用了该索引的最左一列,hash info就是(1,0,true)
关卡2就是为了找出经常使用的hash info,作为建立AHI的依据。
关卡3:该索引树上的某个数据页要被经常使用
如果我们为表中所有数据建立AHI,那AHI就失去了缓存的意义:内存已不足以存放其身躯,必然要放到磁盘上,那么其成本显然已经不低于收益。
回忆一下,AHI是为了缩短B+树的查询成本设计的,如果把自己再放到磁盘上,就得变成另一颗B+树(B+树算法是处理磁盘查询的高效结构),如此循环往复,呜呼哀哉。
因此我们只能为表中经常被查询的部分数据建立AHI。所以关卡3的任务就是找出哪些数据页是经常被使用的数据页。
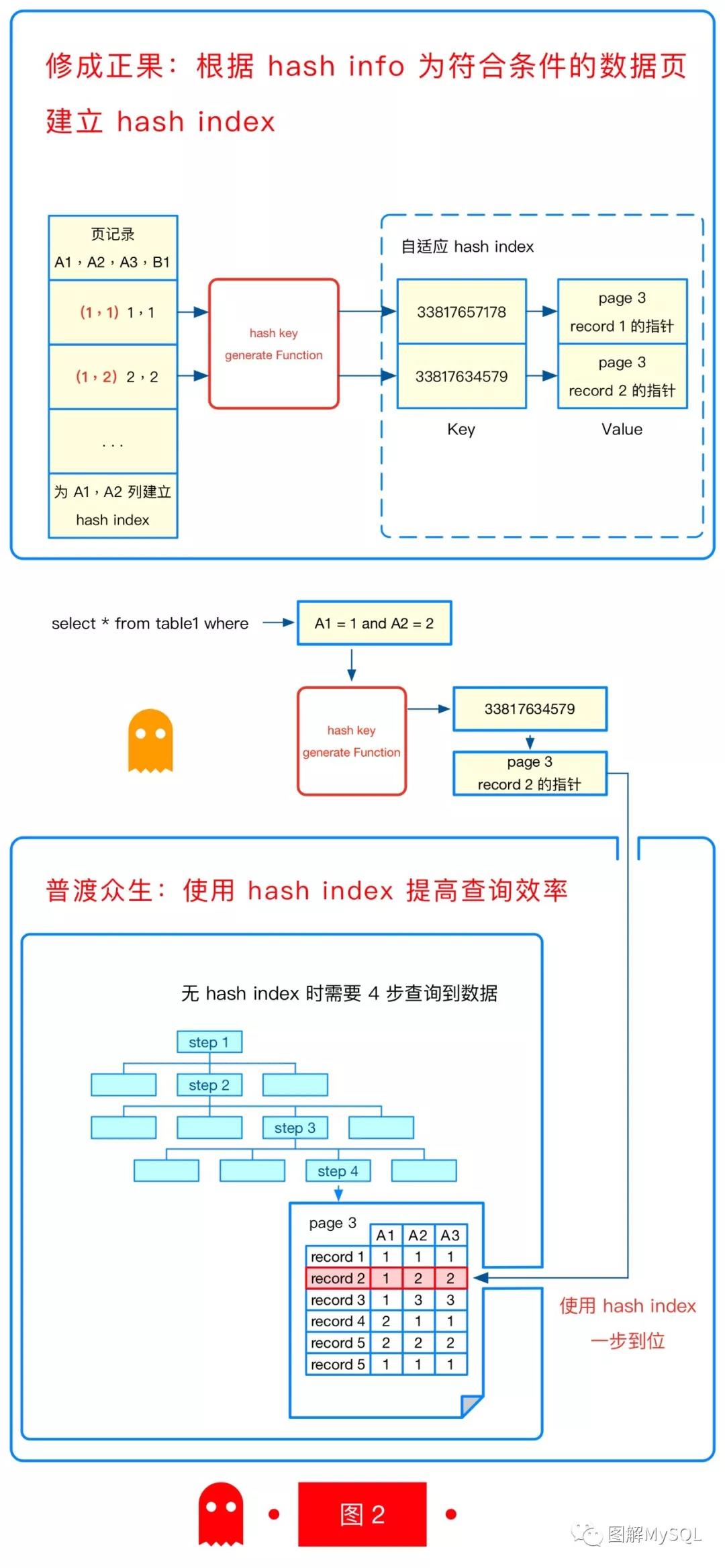
修成正果:终于开始建立AHI
终于可以开始建立AHI了, 我们举个例子说明如何建立AHI。假设以上三个关卡的通关情况如下:
- 表table1具有4列:A1,A2,A3,B1。具有两个索引 Idx1(A1,A2,A3) 和 Idx2(B1)
- 关卡1:选出的索引是 Idx1
- 关卡2:选出的hash info是 (2, 0, true) (很多查询命中了Idx1的最左两列)
- 关卡3:选出了某个数据页P3, 其中包含数据 (1,1,1,1) 和 (1,2,2,2) 等等
那么建立AHI的过程是: 在内存中,为数据页P3中的每一行数据建立索引
- 对于数据(1,1,1,1),根据hash info,选取前两列建立AHI的一项:(1,1)的哈希值->P3
- 对于数据(1,2,2,2),根据hash info,选取前两列建立AHI的一项:(1,2)的哈希值->P3
- 以此类推
普度众生:终于可以使用AHI
我们终于可以AHI加速查询了,假设查询条件是A1=1 and A2=2,其满足条件:
- 命中了索引Idx1
- 索引Idx1上的hash info是(2, 0, true), 查询条件(A1=1 and A2=2)根据hash info转成(1,2)的哈希值
- 根据此哈希值在AHI中查询, 可查询到数据页为P3
从以上过程可以看出,如果命中了AHI,就可以跳过图2中查询索引树的4个步骤,一次到位找到数据页,提升性能。
4. 监控
可以通过SHOW ENGINE INNODB STATUS 命令查看,在INSERT BUFFER AND ADAPTIVE HASH INDEX 段中
mysql> SHOW ENGINE INNODB STATUS;
...
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 48 merges
merged operations:
insert 53, delete mark 2, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 763673, node heap has 3 buffer(s)
Hash table size 763673, node heap has 114 buffer(s)
Hash table size 763673, node heap has 23 buffer(s)
Hash table size 763673, node heap has 125 buffer(s)
Hash table size 763673, node heap has 8 buffer(s)
Hash table size 763673, node heap has 8 buffer(s)
Hash table size 763673, node heap has 43 buffer(s)
Hash table size 763673, node heap has 68 buffer(s)
10.20 hash searches/s, 11.00 non-hash searches/s
...
可以通过 information_schema.innodb_metrics 来监控 AHI 模块的运行状态,首先打开监控。
----- 打开所有与AHI相关的监控项
mysql> SET GLOBAL innodb_monitor_enable=module_adaptive_hash;
Query OK, 0 rows affected (0.00 sec)
----- 查看监控项是否已经开启
mysql> SELECT name,status FROM information_schema.innodb_metrics WHERE subsystem='adaptive_hash_index';
+------------------------------------------+----------+
| name | status |
+------------------------------------------+----------+
| adaptive_hash_searches | enabled |
| adaptive_hash_searches_btree | enabled |
| adaptive_hash_pages_added | disabled |
| adaptive_hash_pages_removed | disabled |
| adaptive_hash_rows_added | disabled |
| adaptive_hash_rows_removed | disabled |
| adaptive_hash_rows_deleted_no_hash_entry | disabled |
| adaptive_hash_rows_updated | disabled |
+------------------------------------------+----------+
8 rows in set (0.09 sec)
----- 重置所有的计数
mysql> SET GLOBAL innodb_monitor_reset_all = 'adaptive_hash%';
Query OK, 0 rows affected (0.00 sec)
该表搜集了 AHI 子系统诸如 AHI 查询次数,更新次数等信息,可以很好的监控其运行状态,在某些负载下,AHI 并不适合打开,关闭 AHI 可以避免额外的维护开销。
5. 参考资料
https://www.cnblogs.com/geaozhang/p/7252389.html
https://jin-yang.github.io/post/mysql-innodb-adaptive-hash-index_init.html
https://zhuanlan.zhihu.com/p/64027532
https://mp.weixin.qq.com/s/oXezJr5jkbE-fD7THao6CQ
