1. 二叉树
二叉树是一种特殊的树。二叉树的特点是每个结点最多有两个节点,左边的叫做左节点,右边的叫做右节点,或者说每个结点最多有两棵子树。更加严格的递归定义是:二叉树要么为空,要么由根结点、左子树和右子树组成,而左子树和右子树分别是一棵二叉树。 下面这棵树就是一棵二叉树。

二叉树的使用范围最广,一棵多叉树也可以转化为二叉树
满二叉树:
树中的每个节点仅包含 0 或 2 个节点。
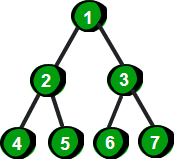
完全二叉树
除最后一层外,每一层上的结点数均达到最大值;在最后一层上只缺少右边的若干结点。

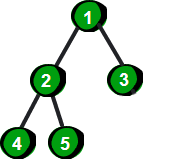

对于一个完全二叉树,我们可以通过一个一维数组存储,通过上图我们发现如果完全二叉树的一个父结点编号为 k,那么它左儿子的编号就是 2k,右儿子的编号就是 2k+1。如果已知儿子(左儿子或右儿子)的编号是 x,那么它父结点的编号就是 x/2,注意这里只取商的整数部分。另外如果一棵完全二叉树有 N 个结点,那么这个完全二叉树的高度为 log2 N 简写为 log N,即最多有 log N 层结点。完全二叉树的最典型应用就是——堆。

堆
堆是一种特殊的基于树的满足某些特性的数据结构,整个堆中的所有父子节点的键值都会满足相同的排序条件。堆更准确地可以分为最大堆与最小堆,在最大堆中,父节点的键值永远大于或者等于子节点的值,并且整个堆中的最大值存储于根节点;而最小堆中,父节点的键值永远小于或者等于其子节点的键值,并且整个堆中的最小值存储于根节点。
- 时间复杂度:
- 访问:
O(log(n)) - 搜索:
O(log(n)) - 插入:
O(log(n)) - 移除:
O(log(n)) - 移除最大值 / 最小值:
O(1)
- 访问:
2. 二叉查找树
下面的图就是两棵二叉查找树,我们可以总结一下它的特点:
- 若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值
- 若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值
- 任意节点的左、右子树也分别为二叉查找树
- 没有键值相等的节点
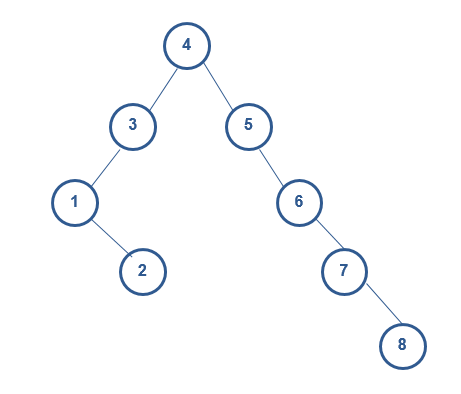
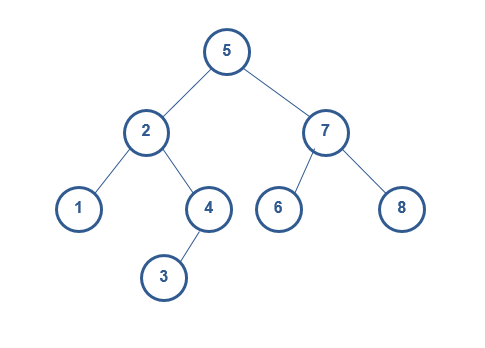

2.1. 插入
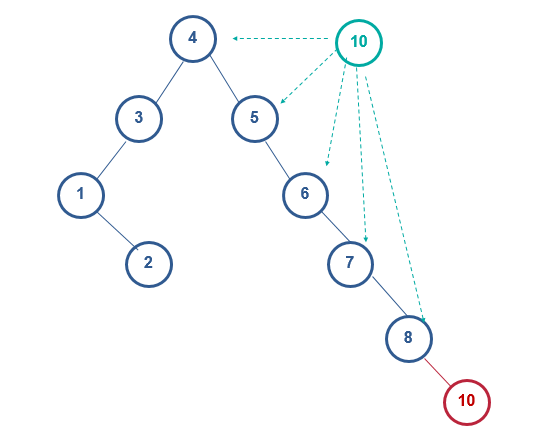
我们需要在a图插入节点10
1) 数10和根节点4比较(10>4),则10放在节点4的右子树中。
2) 接着,10和节点5比较(10>5),则10放在节点5的右子树中。
3) 依次类推:直到10和节点8比较(10>8),则10放在节点8的右子树中,成为节点8的右孩子。
在a图插入节点9
重复上述的步骤后,
4) 9比节点10比较(9<10),则10放在节点10的左子树种,成为节点10的左孩子
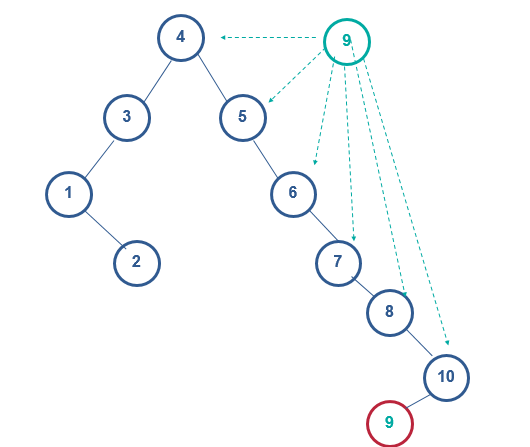
这个过程我们能够发现,动态添加任何一个数据,都会加在原树结构的叶子节点上,而不会重新建树。
2.2. 删除
当删除的节点没有子节点时,直接删除该节点
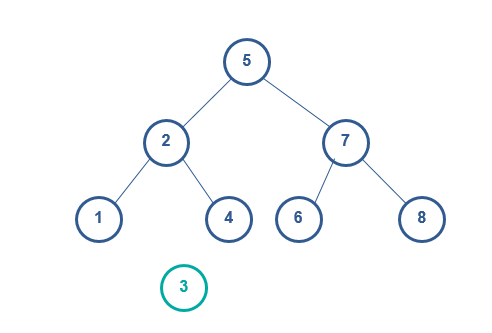
当删除的节点只有1个子节点时,将子节点替换为要删除的节点即可

当删除的节点有2个子节点时,问题就要更复杂了,需要改变子树的结构,但所需要付出的代价很小
例如我们在b图中要删除2,
1) 找的节点2的右子节点中的最小节点3
2) 用最小节点3替换节点2
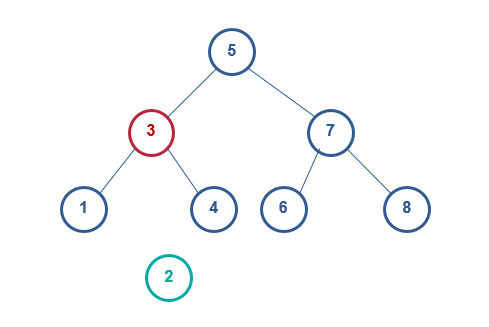
2.3. 查找
根据二叉查找树的规律,查找节点不需要遍历整个数,如果小于节点,就在左子树中查找,如果大于节点就在右子树中查找。但是不同的数据,可能查找次数不同。

最坏情况下,构成的二叉排序树蜕变为单支树,树的深度为n,其查找时间复杂度与顺序查找一样O(N)。最好的情况是二叉排序树的形态和折半查找的判定树相同,其平均查找长度和log2(N)成正比 (O(log2(n)))。 这说明:同样一组数据集合,不同的添加顺序会导致查找树的结构完全不一样,直接影响了查找效率。平衡二叉树用来解决这个问题
3. 平衡二叉树
不同结构的二叉查找树,查询效率有很大的不同,单支树结构的查找效率退化成了顺序查找。解决这个问题的关键在于最大限度的减小树的深度。
平衡二叉查找树,又称 AVL树。 它除了具备二叉查找树的基本特征之外,还具有一个非常重要的特点:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值(平衡因子 ) 不超过1。 也就是说AVL树每个节点的平衡因子只可能是-1、0和1(左子树高度减去右子树高度)。通俗来讲就是父节点的左子树和右子树的高度之差不能大于1,也就是说不能高过1层,否则该树就失衡了,此时就要旋转节点。

那么如何是二叉查找树在添加数据的同时保持平衡呢?基本思想就是:当在二叉排序树中插入一个节点时,首先检查是否因插入而破坏了平衡,若破坏,则找出其中的最小不平衡二叉树,在保持二叉排序树特性的情况下,调整最小不平衡子树中节点之间的关系,以达到新的平衡。所谓最小不平衡子树 指离插入节点最近且以平衡因子的绝对值大于1的节点作为根的子树。
平衡因子
每个结点的平衡因子就是该结点的左子树的高度减去右子树的高度,平衡二叉树的每个结点的平衡因子的绝对值不会超过2
3.1. 查找
与二叉搜索树相同
3.2. 旋转
在平衡二叉树中插入结点与二叉查找树最大的不同在于要随时保证插入后整棵二叉树是平衡的。那么调整不平衡树的基本方法就是: 旋转 。
左旋:逆时针旋转两个节点,让一个节点被其右子节点取代,而该节点成为右子节点的左子节点。
左旋操作步骤如下:首先断开节点 PL 与右子节点 G 的关系,同时将其右子节点的引用指向节点 C2;然后断开节点 G 与左子节点 C2 的关系,同时将 G 的左子节点的应用指向节点 PL。

右旋:顺时针旋转两个节点,让一个节点被其左子节点取代,而该节点成为左子节点的右子节点。
右旋操作步骤如下:首先断开节点 G 与左子节点 PL 的关系,同时将其左子节点的引用指向节点 C2;然后断开节点 PL 与右子节点 C2 的关系,同时将 PL 的右子节点的应用指向节点 G。
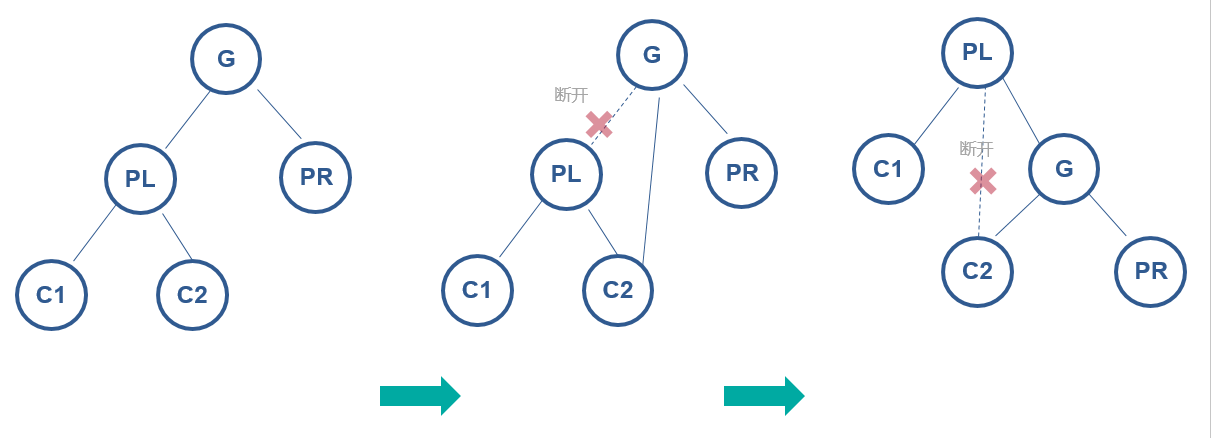
3.3. 失衡
有了旋转的概念后,我们接着了解如何通过旋转来修复一棵失衡的二叉树,这里假设结点X是失衡点,它必须重新恢复平衡,由于任意结点的孩子结点最多有两个,而且导致失衡的必要条件是X结点的两棵子树高度差为2(大于1),因此一般只有以下4种情况可能导致X点失去平衡:
- 在结点X的左孩子结点的左子树中插入元素
- 在结点X的左孩子结点的右子树中插入元素
- 在结点X的右孩子结点的左子树中插入元素
- 在结点X的右孩子结点的右子树中插入元素
对于上述失衡,其中1和4是对称的,只需要做单旋转即可,2和3是对称的,需要双旋转
左左插入,右旋
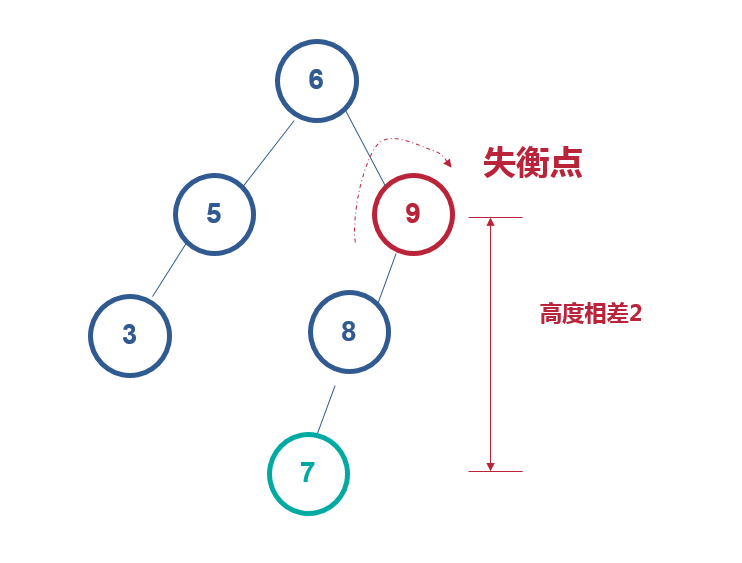
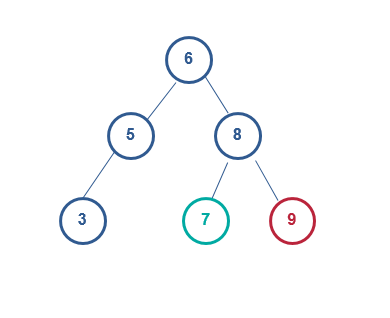
找到失衡点9,右旋
右右插入,左旋
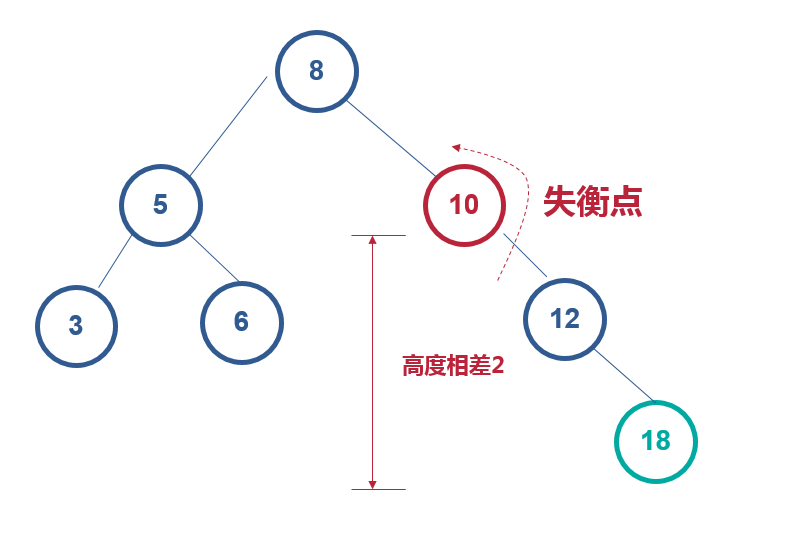
找到失衡点10,左旋

左右插入,先绕X的左子节点Y左旋转,接着再绕X右旋转
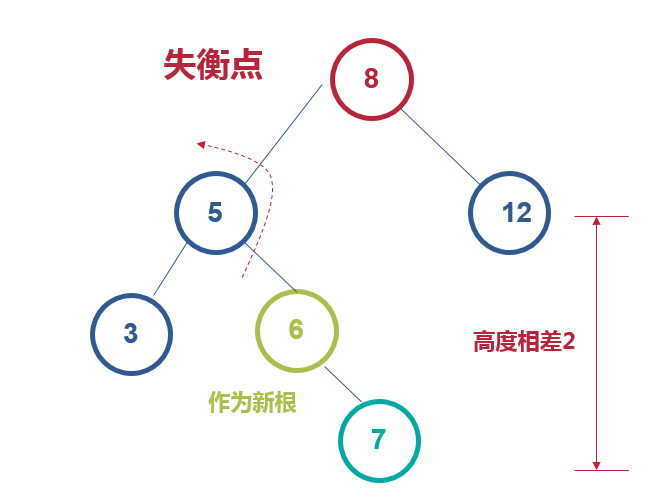
绕5左旋

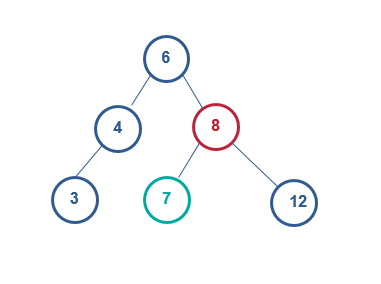
绕8右旋
右左插入,先绕X的右子节点Y右旋转,接着再绕X左旋转
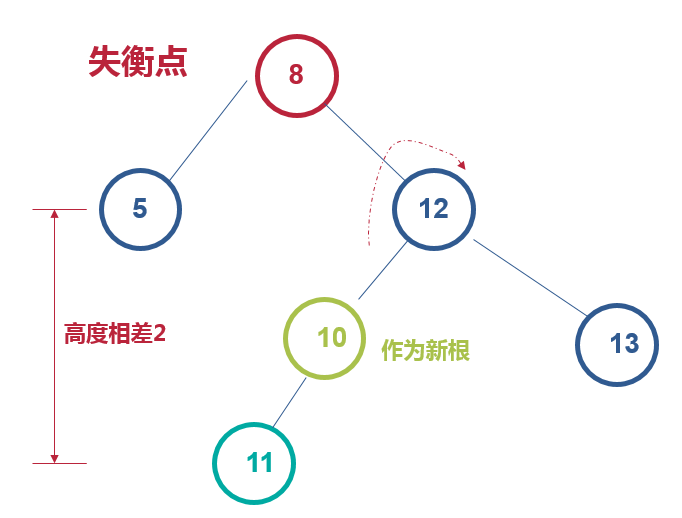
绕12右旋
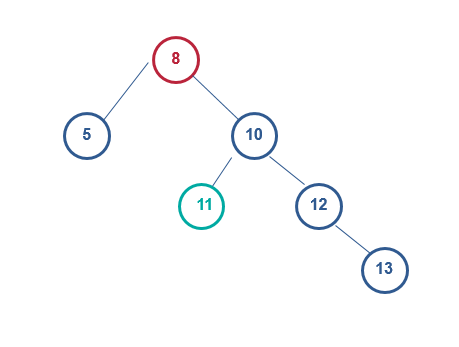
绕8左旋

平衡二叉树的优势在于不会出现普通二叉查找树的最差情况。其查找的时间复杂度为O(logN)。但是为了保证高度平衡,动态插入和删除的代价也随之增加
但是数据库数据是存储在磁盘上的,当数据量较大的时候,树的高度会比较高,我们查询的时候,不可能将整个数据全部加载到内存中,只能逐一加载每一个页,而且每个节点只存储一个记录,会导致一次查询产生多次磁盘IO
为了减少磁盘IO次数,我们就需要把原本瘦高的二叉树,变为胖矮的树。这就是B-树的特征。
4. 参考资料
https://troywu0.gitbooks.io/spark/content/%E4%BA%8C%E5%8F%89%E6%90%9C%E7%B4%A2%E6%A0%91.html
https://troywu0.gitbooks.io/spark/content/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91.html
https://zhuanlan.zhihu.com/p/25239615
https://juejin.im/entry/586876771b69e6006b42b94f
