1. MRR
Multi-Range Read (MRR ),是优化器将随机 IO 转化为顺序 IO 以降低查询过程中 IO 开销的一种手段
- MRR使数据访问变得较为顺序,在查询辅助索引时,首先根据得到的查询结果按照主键进行排序,并按照主键排序的顺序进行书签查找
- 减少缓冲池中页被替换的次数
- 批量处理对键值的查询操作
MRR 原理
在不使用 MRR 时,优化器需要根据二级索引返回的记录来进行“回表”,这个过程一般会有较多的随机 IO, 使用 MRR 时,SQL 语句的执行过程是这样的:
- 优化器将二级索引查询到的记录放到一块缓冲区中;
- 如果二级索引扫描到文件的末尾或者缓冲区已满,则使用快速排序对缓冲区中的内容按照主键进行排序;
- 用户线程调用 MRR 接口取 cluster index,然后根据cluster index 取行数据;
- 当根据缓冲区中的 cluster index 取完数据,则继续调用过程 2) 3),直至扫描结束;
不使用MRR时如下图所示
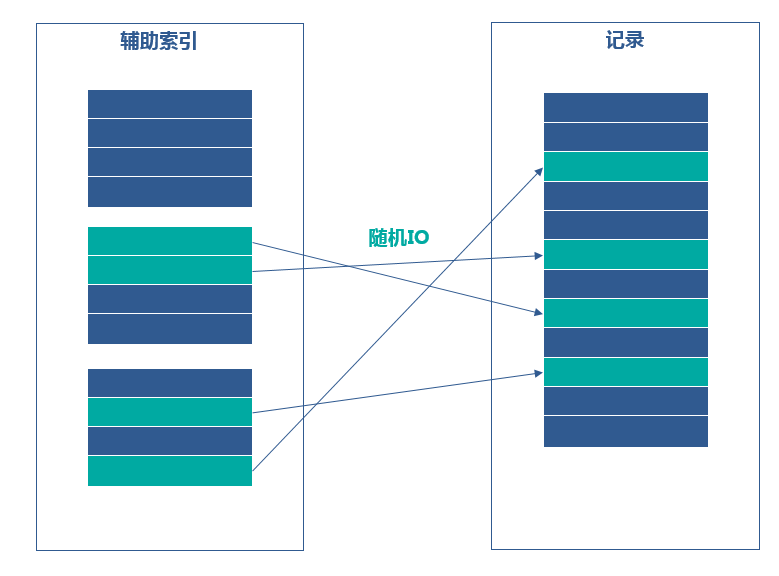
使用MRR时如下图所示

通过上述过程,优化器将二级索引随机的 IO 进行排序,转化为主键的有序排列,从而实现了随机 IO 到顺序 IO 的转化,提升性能
我们可以通过参数 optimizer_switch 的标记来控制是否使用MRR,当设置mrr=on时,表示启用MRR优化。mrr_cost_based 表示是否通过 cost base的方式来启用MRR.如果选择mrr=on,mrr_cost_based=off,则表示总是开启MRR优化。参数read_rnd_buffer_size 用来控制键值缓冲区的大小。
extra会显示Using MRR
使用条件
- 只能用于
range,ref,eq_ref类型的查询 - 只针对二级索引的范围扫描和使用二级索引进行 join 的情况。
我还没找到合适的数据测试
2. ICP
Index Condition Pushdown (ICP),索引条件下推是MySQL提供的用某一个索引对一个特定的表从表中获取元组。注意:这样的索引优化不是用于多表连接而是用于单表扫描,确切地说,是单表利用索引进行扫描以获取数据的一种方式。
The goal of ICP is to reduce the number of full-record reads and thereby reduce IO operations. For InnoDB clustered indexes, the complete record is already read into the InnoDB buffer. Using ICP in this case does not reduce IO.
优化器没有使用ICP时,数据访问和提取的过程如下:
- 当storage engine读取下一行时,首先读取索引元组(index tuple),然后使用索引元组在基表中(base table)定位和读取整行数据
- sever层评估where条件,如果该行数据满足where条件则使用,否则丢弃。
- 执行1,直到最后一行数据。

优化器使用ICP时,server层将会把能够通过使用索引进行评估的where条件下推到storage engine层。数据访问和提取过程如下:
- storage engine从索引中读取下一条索引元组
- storage engine使用索引元组评估下推的索引条件。如果没有满足wehere条件,storage engine将会处理下一条索引元组(回到上一步)。只有当索引元组满足下推的索引条件的时候,才会继续去基表中读取数据。
- 如果满足下推的索引条件,storage engine通过索引元组定位基表的行和读取整行数据并返回给server层。
- server层评估没有被下推到storage engine层的where条件,如果该行数据满足where条件则使用,否则丢弃。
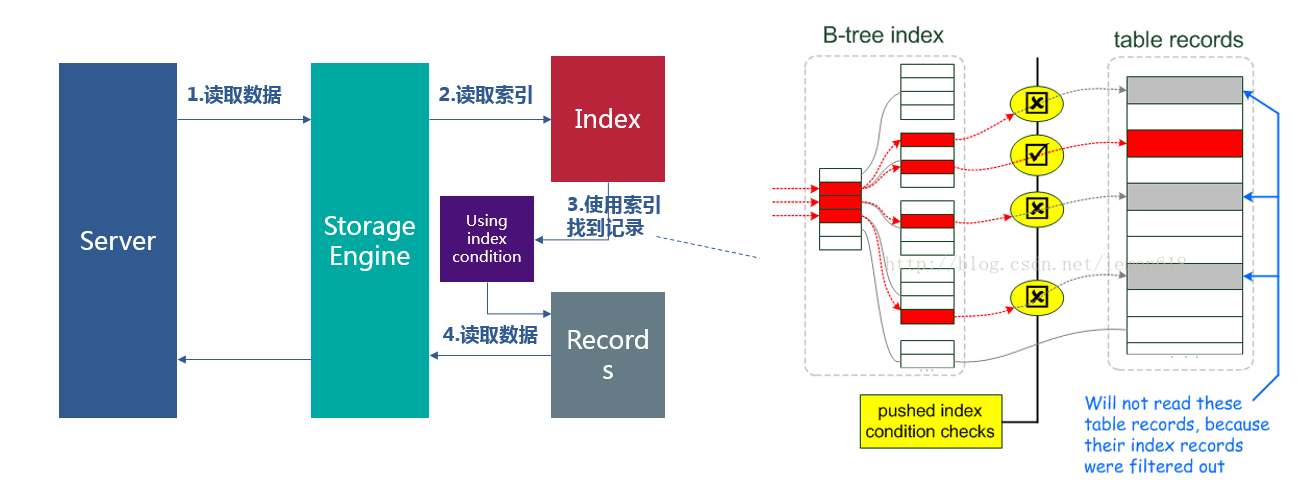
innodb引擎的表,索引下推只能用于辅助索引,对聚集索引无效。
索引条件下推是默认开启的,可以通过下面命令关闭
SET optimizer_switch = 'index_condition_pushdown=off';
使用索引条件下推的SQL,extra列会显示 Using index condition
索引下推一般可用于所求查询字段(select列)不是/不全是联合索引的字段,查询条件为多条件查询且查询条件子句(where/order by)字段全是联合索引。
所以对于 key(zipcode,lastname,firstname)下面的语句
SELECT * FROM people
WHERE zipcode='95054'
AND lastname LIKE '%etrunia%'
AND address LIKE '%Main Street%';
如果没有使用索引下推技术,则MySQL会通过zipcode='95054'从存储引擎中查询对应的元祖,返回到MySQL服务端,然后MySQL服务端基于lastname LIKE '%etrunia%'和address LIKE '%Main Street%'来判断元祖是否符合条件。
如果使用了索引下推技术,则MYSQL首先会返回符合zipcode='95054'的索引,然后根据lastname LIKE '%etrunia%'和address LIKE '%Main Street%'来判断索引是否符合条件。如果符合条件,则根据该索引来定位对应的元祖,如果不符合,则直接reject掉。
3. 测试
准备数据
create table emp(
empno smallint(5) unsigned not null auto_increment,
ename varchar(30) not null,
deptno smallint(5) unsigned not null,
job varchar(30) not null,
primary key(empno),
key idx_emp_info(deptno,ename)
)engine=InnoDB charset=utf8;
insert into emp values(1,'zhangsan',1,'CEO'),(2,'lisi',2,'CFO'),(3,'wangwu',3,'CTO'),(4,'jeanron100',3,'Enginer');
先关闭索引条件下推
SET optimizer_switch = 'index_condition_pushdown=off';
explain select * from emp where deptno between 10 and 3000 and ename ='jeanron100';的extra显示Using where
mysql> explain select * from emp where deptno between 10 and 3000 and ename ='jeanron100';
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
| 1 | SIMPLE | emp | NULL | range | idx_emp_info | idx_emp_info | 94 | NULL | 1 | 25.00 | Using where |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
1 row in set (0.11 sec)
在开启索引下推
SET optimizer_switch = 'index_condition_pushdown=on';
explain select * from emp where deptno between 10 and 3000 and ename ='jeanron100';的extra显示Using index condition
mysql> explain select * from emp where deptno between 10 and 3000 and ename ='jeanron100';
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | emp | NULL | range | idx_emp_info | idx_emp_info | 94 | NULL | 1 | 25.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
1 row in set (0.08 sec)
然而
explain select * from emp where deptno between 1 and 100 and ename ='jeanron100';的extra显示Using where
mysql> explain select * from emp where deptno between 1 and 100 and ename ='jeanron100';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | emp | NULL | ALL | idx_emp_info | NULL | NULL | NULL | 4 | 25.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set (0.08 sec)
我们可以看到两条语句范围不同一个使用了ICP,一个没有,这是为什么?仔细查看上面的语句,发现没有使用ICP的type是ALL,而ALL是不支持ICP的。为什么条件不同有的是range有的是ALL?^_^
- ICP只能用于辅助索引,不能用于聚集索引,对于Innodb的聚集索引,完整的记录已经被读取到Innodb Buffer,此时使用ICP并不能降低IO操作。
- ICP只用于单表,不是多表连接是的连接条件部分
- 如果表访问的类型为
EQ_REF,REF_OR_NULL,REF,SYSTEM,CONST可以使用ICP - 如果表访问的类型为
range如果不是index tree only(只读索引)”,则有机会使用ICP - 如果表访问的类型为
ALL,FT,INDEX_MERGE,INDEX_SCAN不可以使用ICP
4. 参考资料
https://www.cnblogs.com/ivictor/p/5197434.html
https://www.jianshu.com/p/bdc9e57ccf8b
https://blog.51cto.com/lee90/2060449
http://mdba.cn/2014/01/21/index-condition-pushdownicp%e7%b4%a2%e5%bc%95%e6%9d%a1%e4%bb%b6%e4%b8%8b%e6%8e%a8/
