1. 索引的优缺点
索引的优点如下:
- 索引大大减小了服务器需要扫描的数据量。
- 索引可以帮助服务器避免排序和临时表。
- 索引可以将随机 I/O 变成顺序 I/O。
索引的缺点如下:
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行 INSERT、UPDATE 和 DELETE。因为更新表时,MySQL 不仅要保存数据,还要保存索引文件。
- 建立索引会占用磁盘空间的索引文件。一般情况这个问题不算严重,但如果你在一个大表上创建了多种组合索引,且伴随大量数据量插入,索引文件大小也会快速膨胀。
- 如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
- 对于非常小的表,大部分情况下简单的全表扫描更高效。
因此应该只为最经常查询和最经常排序的数据列建立索引。(MySQL 同一个数据表里的索引总数限制为 16 个)
数据库存在的意义之一就是是解决数据存储和快速查找的。那么数据库的数据存在哪?没错,是磁盘,磁盘的优点是啥?便宜!缺点呢?相比内存访问速度慢。
2. 聚集索引与辅助索引
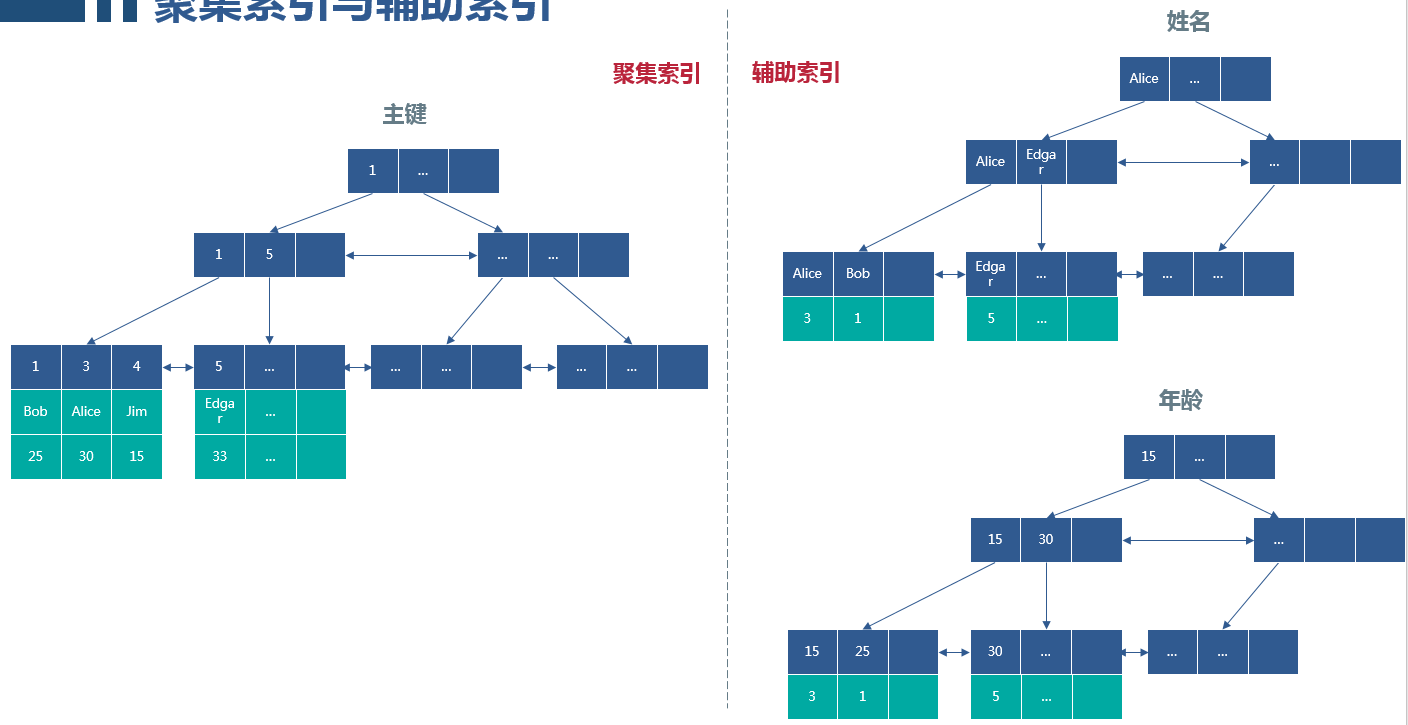
2.1. 聚集索引
- 按照表的主键构造一个B+树
- 叶子节点存放整行数据
- 一个表只有一个聚集索引
- 基于主键的排序和查找非常快
2.2. 辅助索引
- 叶子节点不包括整行数据
- 叶子节点存放了主键的值
- 一个表可以有多个辅助索引
- 搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录,又称回表
3. 联合索引
对多个字段同时建立的索引(有顺序,ABC,ACB是完全不同的两种联合索引)
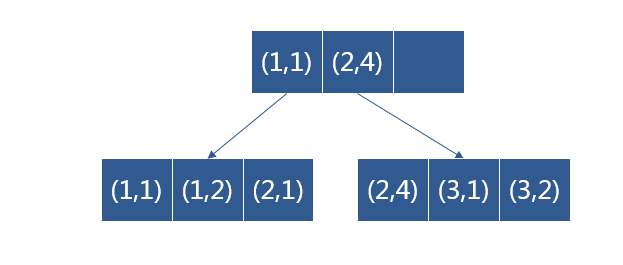
4. 覆盖索引
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为覆盖索引。即只需扫描索引而无须回表,减少IO操作
示例,在表上建一个联合索引
create index idx_seller on purchase_order(seller_id, state, add_on);
分别看下面两条语句,第二条使用了覆盖索引
mysql> EXPLAIN SELECT seller_id, state, amount from purchase_order where seller_id = 234;
+----+-------------+----------------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | purchase_order | NULL | ref | idx_seller | idx_seller | 9 | const | 109 | 100.00 | NULL |
+----+-------------+----------------+------------+------+---------------+------------+---------+-------+------+----------+-------+
1 row in set (0.01 sec)
mysql> EXPLAIN SELECT seller_id, state from purchase_order where seller_id = 234;
+----+-------------+----------------+------------+------+---------------+------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------------+------------+------+---------------+------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | purchase_order | NULL | ref | idx_seller | idx_seller | 9 | const | 109 | 100.00 | Using index |
+----+-------------+----------------+------------+------+---------------+------------+---------+-------+------+----------+-------------+
1 row in set (0.01 sec)
5. 最左匹配原则
mysql会一直向右匹配直到遇到范围查询(>、<、between)就停止匹配。范围列可以用到索引,但是范围列后面的列无法用到索引。即索引最多用于一个范围列。因此如果查询条件中有两个范围列则无法全用到索引,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,但如果建立(a,b,d,c)的索引则都可以用到而且a,b,d的顺序可以任意调整。
对于查询来说in不算范围查询,但是对于排序来说in是范围查询
5.1. 索引查找
对于key(A,B,C)
完全使用索引的查询
- A>5
- A=5 AND B>6
- A=5 AND B=6 AND C = 7
- A=5 AND B IN (2,3) AND C > 5
部分使用索引的查询
- A>5 AND B=2 –范围列后面的列无法用到索引
- A=5 AND B>6 AND C = 7
- A=5 AND C = 7 –中间某个条件未提供
不使用索引的查询
- B>5 –没有指定索引第一列
- B=5 AND C=7
5.2. 索引排序
对于KEY(A,B)
使用索引的排序
- ORDER BY A –索引第一列排序
- A=5 ORDER BY B –精确匹配索引第一列,用第二列排序
- ORDER BY A DESC, B DESC –两列按相同的顺序排序
- A > 5 ORDER BY A –第一列按范围查询,同时第一列排序
不使用索引的排序
- B>5 –索引第二列排序
- A>5 ORDER BY B –第一列按范围查询,第二列排序
- A IN (1,2) ORDER BY B –第一列in查询,第二列排序,对于排序来说in是范围查询
- ORDER BY A ASC, B DESC –两列按不同的顺序排序
- ORDER BY A ASC, D ASC –使用了非索引字段
5.3. 小技巧
=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
A BETWEEN 2 AND 4 AND B = 5 只有A使用了索引,改为 好像MySQL5.6会通过索引下推优化优化这个语句 ,在索引内部就判断了B是否等于5,对应不等于5的记录直接跳过A IN (2, 4) AND B = 5 都可以使用索引
可以伪造IN来填补查询形成最左前缀匹配,例如SELECT * FROM PEOPLE WHERE CITY=“WH”可以改成SELECT * FROM PEOPLE WHERE GENDER IN(“M”,”F”) AND CITY=“WH”。只有在缺少列的值值比较少的情况下,可以考虑用“IN”来填补从而形成最左前缀
SELECT * FROM TBL WHERE A IN (1,2) ORDER BY B LIMIT 5;可以改为
(SELECT * FROM TBL WHERE A=1 ORDER BY B LIMIT 5)
UNION ALL
(SELECT * FROM TBL WHERE A=2 ORDER BY B LIMIT 5)
ORDER BY B LIMIT 5;
上述语句仅会对10条数据进行filesort
SELECT * FROM TBL WHERE A=5 AND B=6 使用索引KEY(A,B)更合适。但是SELECT * FROM TBL WHERE A=5 OR B=6使用KEY(A),KEY(B)两个索引更合适
6. 索引失效的情况
- 对索引列运算,运算包括(+、-、*、/、!、<>、%、like’%_‘(%放在前面)
- 类型错误,如字段类型为varchar,where条件用number
- 对索引应用内部函数,这种情况下应该要建立基于函数的索引。例如 select * from template t where ROUND (t.logicdb_id) = 1,此时应该建ROUND (t.logicdb_id)为索引,MySQL8.0开始支持函数索引,5.7可以通过虚拟列的方式来支持,之前只能新建一个ROUND (t.logicdb_id)列然后去维护;
- 如果条件有or,即使其中有条件带索引也不会使用(这也是为什么建议少使用or的原因),如果想使用or,又想索引有效,只能将or条件中的每个列加上索引;
- 如果列类型是字符串,那一定要在条件中数据使用引号,否则不使用索引;
- B-tree索引 is null不会走,is not null会走,索引不会包含有 NULL 值的列
7. 怎么建立索引
- 索引并非越多越好,大量的索引不仅占用磁盘空间,而且还会影响insert,delete,update等语句的性能
- 避免对经常更新的表做更多的索引,并且索引中的列尽可能少;
- 对经常用于查询的字段创建索引,避免添加不必要的索引
- 少量的数据(几百条),没必要建索引,由于数据较少,全表扫描花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果
- 尽量选择区分度高的列作为索引,区分度的公式是
count(distinct col)/count(*),表示字段不重复的基数,基数越大我们扫描的记录数越少
8. 参考资料
https://mp.weixin.qq.com/s/w-M1mfj1UdpltD9gazSSKw
https://mp.weixin.qq.com/s/1ZWOLPV4fCqi2EebU_C9YA
