上一篇文章介绍了MySQL事务隔离,下面我们来看一下MySQL如何实现这种事务隔离
1. 概念
读锁:也叫共享锁、S锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S 锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
写锁:又称排他锁、X锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
表锁:操作对象是数据表。Mysql大多数锁策略都支持,是系统开销最低但并发性最低的一个锁策略。事务t对整个表加读锁,则其他事务可读不可写,若加写锁,则其他事务增删改都不行。
行级锁:操作对象是数据表中的一行。是MVCC技术用的比较多的。行级锁对系统开销较大,但处理高并发较好。
2. MVCC
指的是一种提高并发的技术。最早的数据库系统,只有读读之间可以并发,读写,写读,写写都要阻塞。引入多版本之后,只有写写之间相互阻塞,其他三种操作都可以并行,这样大幅度提高了InnoDB的并发度。在内部实现中,与Postgres在数据行上实现多版本不同,InnoDB是在undolog中实现的,通过undolog可以找回数据的历史版本。找回的数据历史版本可以提供给用户读(按照隔离级别的定义,有些读请求只能看到比较老的数据版本),也可以在回滚的时候覆盖数据页上的数据。在InnoDB内部中,会记录一个全局的活跃读写事务数组,其主要用来判断事务的可见性。
摘自[数据库内核月报 - 2017 / 12](http://mysql.taobao.org/monthly/2017/12)
- MySQL的大多数事务型存储引擎实现的其实都不是简单的行级锁。基于提升并发性能的考虑, 它们一般都同时实现了多版本并发控制(MVCC)。不仅是MySQL, 包括Oracle,PostgreSQL等其他数据库系统也都实现了MVCC, 但各自的实现机制不尽相同, 因为MVCC没有一个统一的实现标准。
- 可以认为MVCC是行级锁的一个变种, 但是它在很多情况下避免了加锁操作, 因此开销更低。虽然实现机制有所不同, 但大都实现了非阻塞的读操作,写操作也只锁定必要的行。
- MVCC的实现方式有多种, 典型的有乐观(optimistic)并发控制 和 悲观(pessimistic)并发控制。
- MVCC只在
READ COMMITTED和REPEATABLE READ两个隔离级别下工作。其他两个隔离级别够和MVCC不兼容, 因为READ UNCOMMITTED总是读取最新的数据行, 而不是符合当前事务版本的数据行。而SERIALIZABLE则会对所有读取的行都加锁。
摘自高性能呢MySQL
3. 版本链
对于使用InnoDB存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列(row_id并不是必要的,我们创建的表中有主键或者非NULL唯一键时都不会包含row_id列):
-
db_trx_id:6字节的事务ID,每次对某条聚簇索引记录进行改动时,都会把对应的事务id赋值给db_trx_id隐藏列。用来标识最近一次对本行记录做修改(insertupdate)的事务的标识符 db_roll_pointer:7字节的回滚指针,每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。如果一行记录被更新, 则 undo日志 包含 ‘重建该行记录被更新之前内容’ 所必须的信息。
undo日志后面有时间在补充
在InnoDB里,INSERT操作在事务提交前只对当前事务可见,因此产生的Undo日志可以在事务提交后直接删除,UPDATE和DELETE操作产生的Undo日志被归成一类,即update_undo
回滚段中的undo logs分为:
insert undo log和update undo log
- insert undo log : 事务对insert新记录时产生的undolog, 只在事务回滚时需要, 并且在事务提交后就可以立即丢弃。
- update undo log : 事务对记录进行delete和update操作时产生的undo log, 不仅在事务回滚时需要, 一致性读也需要,所以不能随便删除,只有当数据库所使用的快照中不涉及该日志记录,对应的回滚日志才会被purge线程删除。
1.初始行
Insert user(id, name) values(1, ‘edgar’)

因为是新插入的数据,所以这行数据是第一个版本,因此它的roll_pointer为null,没有上一个版本的数据可以指向
2.更新
Update user set name = ‘bob’ where id = 1
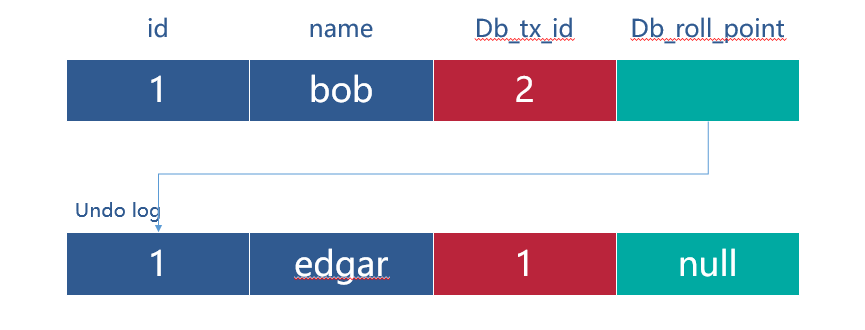
接着事务 (trx_id=2),将这行数据的值修改为 bob,同样也会记录一条 undo log,如上图所示,这条 undo log 的 roll_pointer 指针会指向上一个数据版本的 undo log,也就是指向事务 (trx_id=1) 写入的那一行 undo log。
3.再次更新
Update user set name = ‘jim’ where id = 1
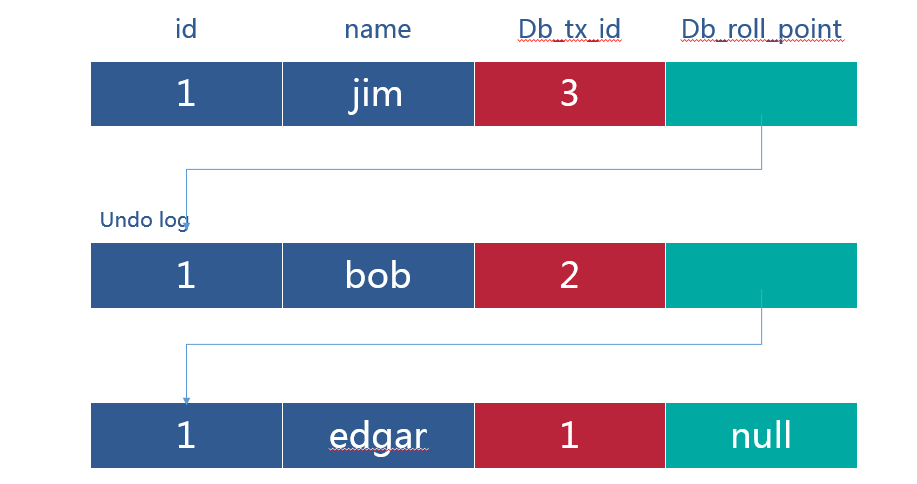
对该记录每次更新后,都会将旧值放到一条undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被roll_pointer属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id
4. Read View
这部分内容基本上摘抄自https://mp.weixin.qq.com/s/Jeg8656gGtkPteYWrG5_Nw
InnoDB的MVCC多版本(Read Committed和Repeatable Read隔离级别)是利用consistent read view(一致读视图)方式支持的。所谓consistent read view就是在某一时刻给事务系统打快照,把当时事务系统状态(包括活跃读写事务数组)记下来(我们命名为m_ids),之后的所有读操作根据其事务ID与快照中事务系统的状态作比较,以此判断read view对于事务的可见性。
这个 ReadView 会记录 4 个非常重要的属性:
- creator_trx_id: 当前事务的 id;
- m_ids: 当前系统中所有的活跃事务的 id,活跃事务指的是当前系统中开启了事务,但是还没有提交的事务;
- min_trx_id: 当前系统中,所有活跃事务中事务 id 最小的那个事务,也就是 m_id 数组中最小的事务 id;
- max_trx_id: 当前系统中事务的 id 值最大的那个事务 id 值再加 1,也就是系统中下一个要生成的事务 id。
ReadView 会根据这 4 个属性,再结合 undo log 版本链,来实现 MVCC 机制,决定让一个事务能读取到哪些数据,不能读取到哪些数据。
在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
- 如果被访问版本的
trx_id属性值小于m_ids列表中最小的事务id,表明生成该版本的事务在生成ReadView前已经提交,所以该版本可以被当前事务访问。 - 如果被访问版本的
trx_id属性值大于m_ids列表中最大的事务id,表明生成该版本的事务在生成ReadView后才生成,所以该版本不可以被当前事务访问。 - 如果被访问版本的
trx_id属性值在m_ids列表中最大的事务id和最小事务id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本,如果最后一个版本也不可见的话,那么就意味着该条记录对该事务不可见,查询结果就不包含该记录。
在MySQL中,READ COMMITTED和REPEATABLE READ隔离级别的的一个非常大的区别就是它们生成ReadView的时机不同
-
READ COMMITTED 事务中每条select语句都会创建一个ReadView
-
REPEATABLE READ 事务在begin/start transaction之后的第一条select读操作后, 会创建一个ReadView 将当前系统中活跃的其他事务记录记录起来,只生成一次
With REPEATABLE READ isolation level, the snapshot is based on the time when the first read operation is performed.
使用REPEATABLE READ隔离级别,快照是基于执行第一个读操作的时间。
With READ COMMITTED isolation level, the snapshot is reset to the time of each consistent read operation.
使用READ COMMITTED隔离级别,快照被重置为每个一致的读取操作的时间。
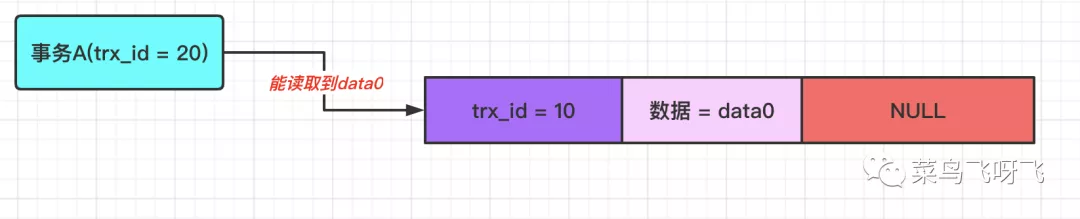
下面举几个例子,来解释一下 ReadView 机制下,数据的读取规则。先假设表中有一条数据,它的 row_trx_id=10,roll_pointer 为 null,那么此时 undo log 版本链就是下图这样:

假设现在有事务 A 和事务 B 并发执行,事务 A 的事务 id 为 20,事务 B 的事务 id 为 30。
那么此时对于事务 A 而言,它的 ReadView 中,m_ids=[20,30],min_trx_id=20,max_trx_id=31,creator_trx_id=20。
对于事务 B 而言,它的 ReadView 中,m_ids=[20,30],min_trx_id=20,max_trx_id=31,creator_trx_id=30。
如果此时事务 A(trx_id=20)去读取数据,那么在 undo log 版本链中,数据最新版本的事务 id 为 10,这个值小于事务 A 的 ReadView 里 min_trx_id 的值,这表示这个数据的版本是事务 A 开启之前,其他事务提交的,因此事务 A 可以读取到,所以读取到的值是 data0。
接着事务 B(trx_id=30)去修改数据,将数据修改为 data_B,先不提交事务。虽然不提交事务,但是仍然会记录一条 undo log,因此这条数据的 undo log 的版本链就有两条记录了,新的这条 undo log 的 roll_pointer 指针会指向前一条 undo log,示意图如下。
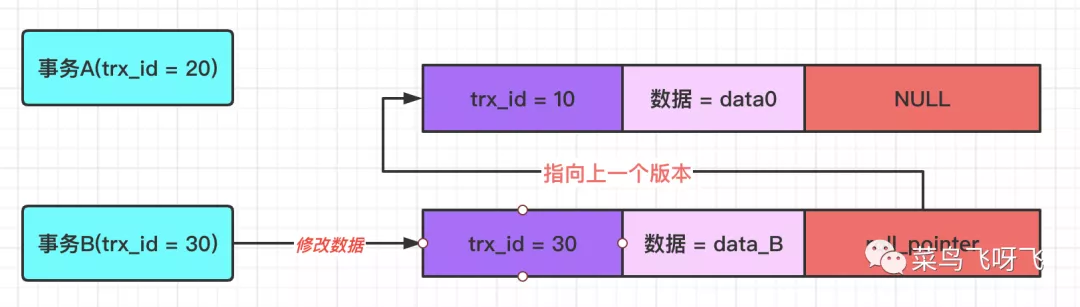
接着事务 A(trx_id=20)去读取数据,那么在 undo log 版本链中,数据最新版本的事务 id 为 30,这个值处于事务 A 的 ReadView 里 min_trx_id 和 max_trx_id 之间,因此还需要判断这个数据版本的值是否在 m_ids 数组中,结果发现,30 确实在 m_ids 数组中,这表示这个版本的数据是和自己同一时刻启动的事务修改的,因此这个版本的数据,数据 A 读取不到。所以需要沿着 undo log 的版本链向前找,接着会找到该行数据的上一个版本,也就是 trx_id=10 的版本,由于这个版本的数据的 trx_id=10,小于 min_trx_id 的值,因此事务 A 能读取到该版本的值,即事务 A 读取到的值是 data0。
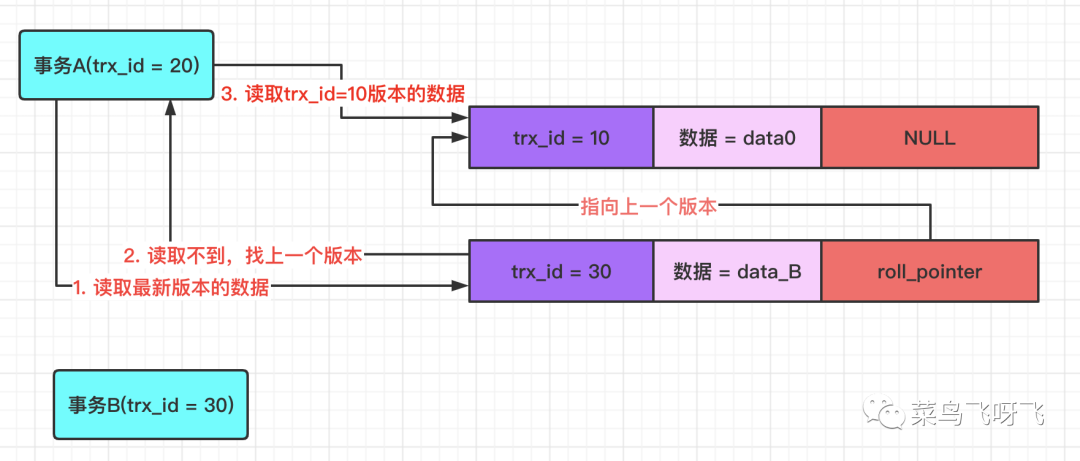
紧接着事务 B 提交事务,那么此时系统中活跃的事务就只有 id 为 20 的事务了,也就是事务 A。那么此时事务 A 再去读取数据,它能读取到什么值呢?还是 data0。为什么呢?
虽然系统中当前只剩下 id 为 20 的活跃事务了,但是事务 A 开启的瞬间,它已经生成了 ReadView ,后面即使有其他事务提交了,但是事务 A 的 ReadView 不会修改,也就是 m_ids 不会变,还是 m_ids=[20,30],所以此时事务 A 去根据 undo log 版本链去读取数据时,还是不能读取最新版本的数据,只能往前找,最终还是只能读取到 data0。
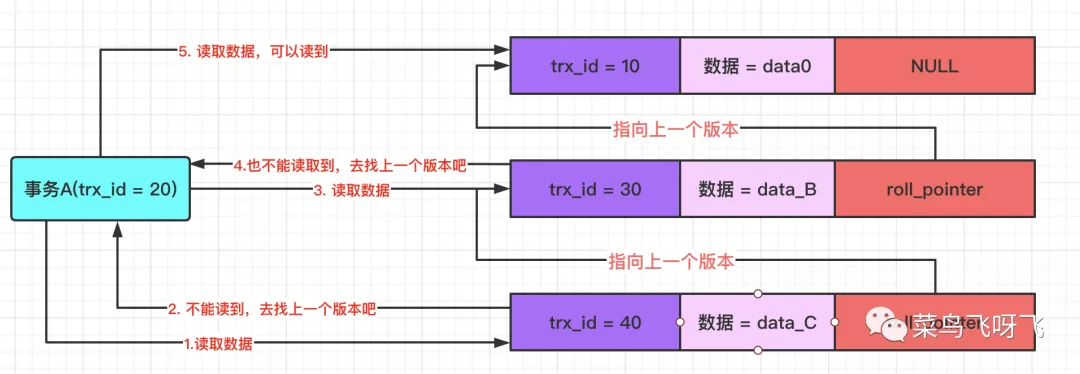
接着系统中,新开了一个事务 C,事务 id 为 40,它的 ReadView 中,m_ids=[20,40],min_trx_id=20,max_trx_id=41,creator_trx_id=40。
然后事务 C(trx_id=40)将数据修改为 data_C,并提交事务。此时 undo log 版本链就变成了如下图所示。

此时事务 A(trx_id=20)去读取数据,那么在 undo log 版本链中,数据最新版本的事务 id 为 40,由于此时事务 A 的 ReadView 中的 max_trx_id=31,40 大于 31,这表示当前版本的数据时在事务 A 之后提交的,因此对于事务 A 肯定是不能读取到的。所以此时事务 A 只能根据 roll_pointer 指针,沿着 undo log 版本向前找,结果发现上一个版本的 trx_id=30,自己还是不能读取到,所以再继续往前找,最终可以读取到 trx_id=10 的版本数据,因此最终事务 A 只能读取到 data0。
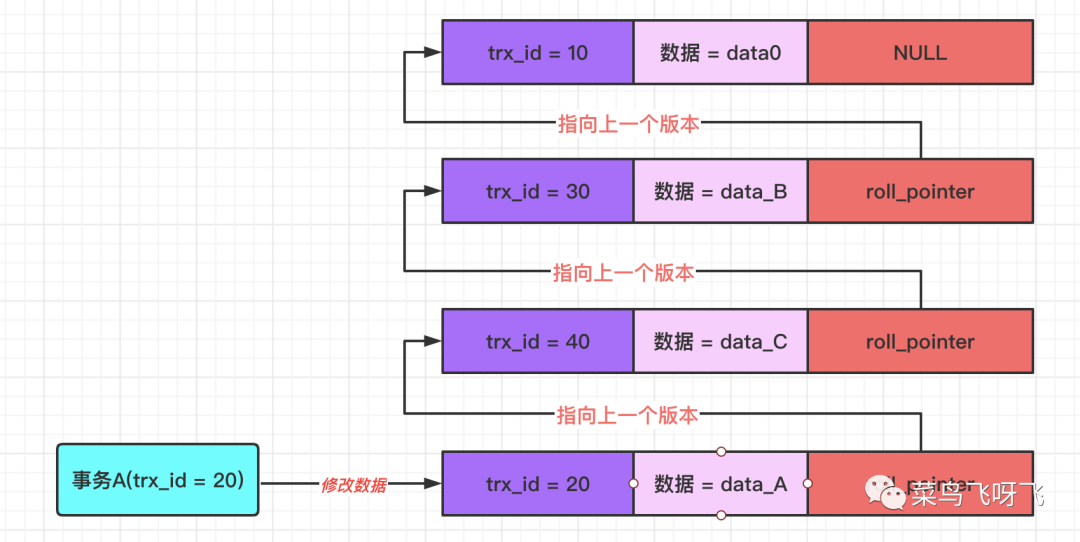
接着事务 A(trx_id=20)去修改数据,将数据修改为 data_A,那么就会记录一条 undo log,示意图如下:
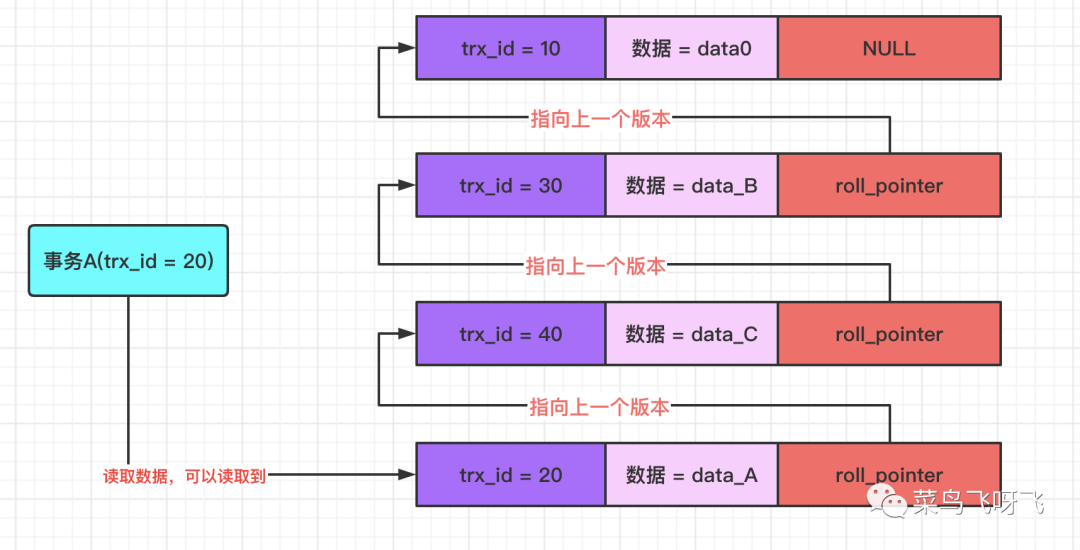
然后事务 A(trx_id=20)再去读取数据,在 undo log 版本链中,数据最新版本的事务 id 为 20,事务 A 一对比,发现该版本的事务 id 与自己的事务 id 相等,这表示这个版本的数据就是自己修改的,既然是自己修改的,那就肯定能读取到了,因此此时读取到是 data_A。
5 参考资料
https://yq.aliyun.com/articles/560506
https://mp.weixin.qq.com/s/Jeg8656gGtkPteYWrG5_Nw
https://segmentfault.com/a/1190000012650596
https://mp.weixin.qq.com/s/DOlCuvnWm87zeE51baDqhA
