完全复制自https://mp.weixin.qq.com/s/uCtEqI9woo1_urdz9lxGCg
1. 索引页创建
在InnoDB中,所有的数据就是一个索引。假设您已经安装了MySQL,5.7最新版本,您在windmills schema中有一个名为wmills的表。在数据目录中(通常是/var/lib/mysql/)您会看到它包含有:
data/
windmills/
wmills.ibd
wmills.frm
这是因为参数innodb_file_per_table从MySQL5.6开始已经设置为1。这样设置,schema中每个表都是一个文件(如果是分区表,则有多个文件)。
这里重要的是名为wmills.ibd的文件。这个文件被分为N个段。每个段都与一个索引相关联。
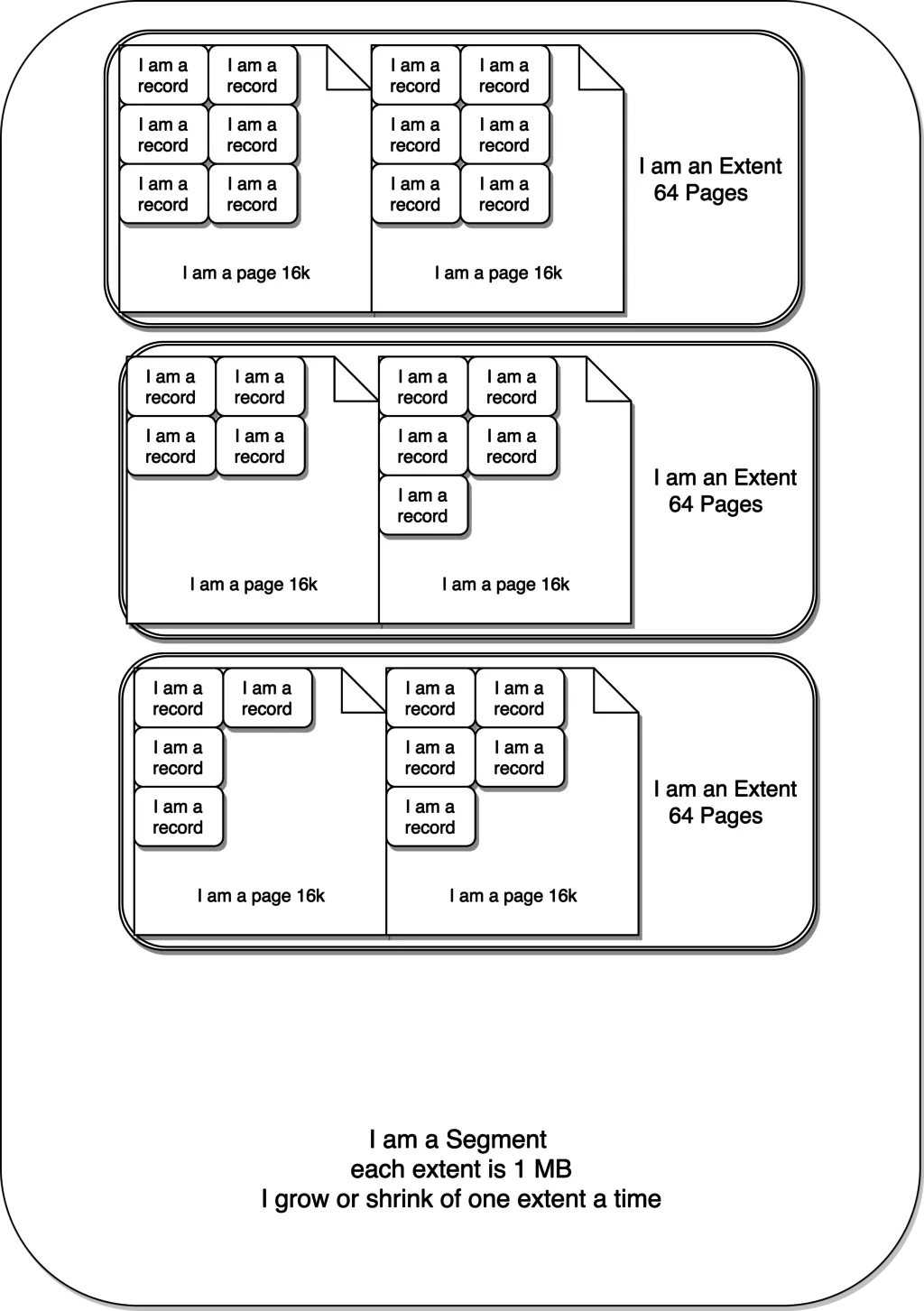
尽管文件不会因删除数据而收缩,段本身会增长或收缩,下一级为区。一个区仅存在一个段中,并且固定尺寸为1MB(在默认页大小的情况下)。页是区的下一级,默认大小为16KB。
因此,一个区最多可包含64页。一个页可以包含2到N行。一个页可以容纳的行数与行大小有关,这是表结构设计时定义的。InnoDB中有一个规则,至少要在一个页中容纳两行。因此,行大小限制为8000字节。
如图所示:
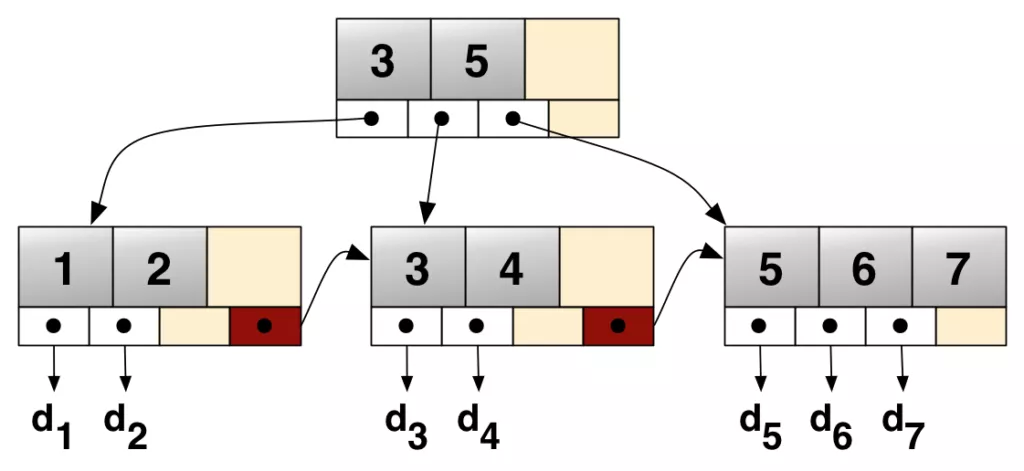
InnoDB使用B+树。每个页(叶子节点)包含由主键组织的2~N行。树有专门的页管理不同的子树。这些被称为内部节点(INodes)。
个图片仅是示例,并不能说明下面的实际输出。
细节如下:
ROOT NODE #3: 4 records, 68 bytes
NODE POINTER RECORD ≥ (id=2) → #197
INTERNAL NODE #197: 464 records, 7888 bytes
NODE POINTER RECORD ≥ (id=2) → #5
LEAF NODE #5: 57 records, 7524 bytes
RECORD: (id=2) → (uuid="884e471c-0e82-11e7-8bf6-08002734ed50", millid=139, kwatts_s=1956, date="2017-05-01", location="For beauty's pattern to succeeding men.Yet do thy", active=1, time="2017-03-21 22:05:45", strrecordtype="Wit")
表结构如下:
CREATE TABLE `wmills` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`uuid` char(36) COLLATE utf8_bin NOT NULL,
`millid` smallint(6) NOT NULL,
`kwatts_s` int(11) NOT NULL,
`date` date NOT NULL,
`location` varchar(50) COLLATE utf8_bin DEFAULT NULL,
`active` tinyint(2) NOT NULL DEFAULT '1',
`time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`strrecordtype` char(3) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`id`),
KEY `IDX_millid` (`millid`)
) ENGINE=InnoDB;
所有类型的B+树都有一个称为根节点的入口点。我们已经在第3页找到了它。根页包含了索引ID、INodes数量等信息。INode页包含关于页本身、值的范围等信息。最后,我们有叶节点,这是我们可以找到数据的地方。在本例中,我们可以看到叶节点5有57条记录,总共7524字节。这行下面是一条记录,您可以看到行数据。
这里的概念是,当您在表和行中组织数据时,InnoDB在分支节点、页和记录中组织数据。记住InnoDB不能以单行基础上工作是非常重要的。InnoDB总是在页上操作。一旦页被加载,它就会扫描页以寻找所请求的行/记录。
页可以是空,也可以是被填充满(100%)。行记录由主键组织。例如,如果您的表使用自增值,您将有序列ID=1,2,3,4等。
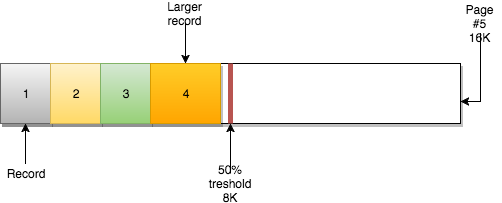
页还有另一个重要属性:MERGE_THRESHOLD。这个参数的默认值是页的50%,它在InnoDB页合并活动中起着非常重要的作用:

在插入数据时,如果插入的记录可以容纳在该页内,则按顺序填充该页。
当页已经满时,下一条记录将插入到下一页:

鉴于B+树的特点,该结构不仅可以自上而下沿着子树查找,还可以水平跨叶节点查找。这是因为每个叶节点页都有一个指向包含序列中下一个记录的页的指针。
例如,第5页指向下一页第6页。第6页指向前一页(第5页),并指向下一页(第7页)。
链表的这种机制允许快速、有序的扫描(例如,范围扫描)。如之前所述,这是在插入基于自增主键的表发生的情况。但是如果我开始删除值时会发生什么呢?
2. 页合并
当您删除一条记录时,不会实际删除该记录,而是将记录标记为已删除,并且该记录使用的空间可回收。

当一个页删除足够多的数据,达到合并阈值(默认是页大小的50%),InnoDB开始找相邻的页(之前和之后的)查看它们是否有机会合并两个页,优化空间使用率。

在这个例子中,第6页占用空间不足一半。第5页删除了很多记录,也使用了不足50%。从InnoDB的角度看,它们是可以合并的:
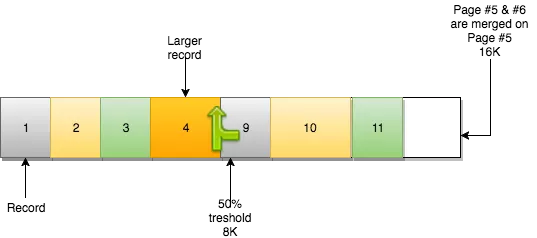
合并操作的结果是:第5页包含了之前的数据和第6页的数据。第6页变成了空页,可用于新数据。

当我们更新一条记录,新记录的大小使页面低于阈值时,也会发生相同的过程。
规则是:如果在相邻页有更新和删除操作,将产生合并。如果合并成功,在INFORMATION_SCHEMA.INNODB_METRICS表中的index_page_merge_successful指标将会增加。
3. 页分裂
如上所述,一个页最多可以填充100%。发生这种情况时,下一页将获取新记录。
但是如果我们遇到以下情况呢?

第10页没有足够的空间容纳新的记录(或者更新的记录)。遵循下一页的逻辑,这个记录应该在第11页上。然而:

第11页也已满,数据不能乱序插入。那该怎么办呢?
还记得我们说过的链表吗?此时第10页之前的页为第9页,之后的页为第11页。
InnoDB将做的是(简化版):
- 创建一个新页。
- 确定原始页(第10页)可以在哪里拆分(在记录级别)
- 移动记录
- 重新定义页之间关系

新的第12页被创建:

第11页保持原样。改变的是页之间的关系:
- 第10页之前的页为第9页,之后的页为第12页
- 第12页之前的页为第10页,之后的页是第11页
- 第11页之前的页为第12页,之后的页为第13页
B+树的路径仍然遵循逻辑组织,因此仍然可以看到一致性。但是,页面的物理位置是无序的,在大多数情况下是在不同的程度的。
通常,我们可以说:页分裂发生在插入或者更新,并导致页错位(在许多情况下,程度不同)。
InnoDB在INFORMATION_SCHEMA.INNODB_METRICS表中记录了页分裂的次数。查看index_page_splits和index_page_reorg_attempts/successful指标。
一旦分裂的页创建,将其回收的唯一方法是将创建的页降至合并阈值下。当这发生时,InnoDB通过合并操作将数据从分裂页迁移走。
另外一个组织数据的方法是OPTIMIZE TABlE。这是一个代价比较大和长的过程,但通常是处理太多页比较稀疏的唯一方法。
另一个需要记住的是,在合并和分裂时,InnoDB在索引树上需要加一个X的闩。在繁忙的系统上,这很容易成为一个问题。这会导致索引闩争用。如果没有合并和分裂(也就是写入),只有一个单独的页,在InnoDB中被称为“乐观”更新,此时的闩为共享闩。合并和分裂被称为“悲观”更新,此时的闩为排他闩。
