我们先看两段sql
mysql> explain select commodity_id from commodity order by seller_id;
+----+-------------+-----------+------------+-------+---------------+------------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+------------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | commodity | NULL | index | NULL | idx_seller | 398 | NULL | 22911 | 100.00 | Using index |
+----+-------------+-----------+------------+-------+---------------+------------+---------+------+-------+----------+-------------+
1 row in set (0.05 sec)
mysql> explain select commodity_id from commodity order by add_on;
+----+-------------+-----------+------------+------+---------------+------+---------+------+-------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+-------+----------+----------------+
| 1 | SIMPLE | commodity | NULL | ALL | NULL | NULL | NULL | NULL | 22911 | 100.00 | Using filesort |
+----+-------------+-----------+------------+------+---------------+------+---------+------+-------+----------+----------------+
1 row in set (0.05 sec)
我们发现第一个sql显示Using index,第二个sql显示Using filesort。
MySQL 中有两种排序方式:
- 通过有序索引扫描直接返回有序数据,这种方式在使用explain分析查询的时候显示为
using index, 不需要额外的排序,操作效率较高。 - 通过对返回数据进行排序,也就是通常所说的filesort排序,所有不是通过索引直接返回排序结果的排序都叫filesort排序。 filesort并不代表通过磁盘文件进行排序,而只是进行了一个排序操作,至于排序操作是否使用了磁盘文件或者临时表等,则取决于MySQL服务器对排序参数的设置和需要排序数据的大小。
sort buffer:MySQL在需要做排序操作时会为每个线程分配一块内存进行排序,叫做sort buffer,可以通过配置参数sort_buffer_size 设置buffer的大小
mysql> show variables like '%sort_buffer%';
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| innodb_sort_buffer_size | 1048576 |
| myisam_sort_buffer_size | 262144 |
| sort_buffer_size | 720896 |
+-------------------------+---------+
3 rows in set (0.04 sec)
如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
下面的内容都是从极客时间的课程里拷贝的,比别的文章讲的更简单明了
CREATE TABLE `t` (
`id` INT ( 11 ) NOT NULL,
`city` VARCHAR ( 16 ) NOT NULL,
`name` VARCHAR ( 16 ) NOT NULL,
`age` INT ( 11 ) NOT NULL,
`addr` VARCHAR ( 128 ) DEFAULT NULL,
PRIMARY KEY ( `id` ),
KEY `city` ( `city` )
) ENGINE = INNODB;
对于下面的查询
select city,name,age from t where city='杭州' order by name limit 1000;
通常情况下,这个语句执行流程如下所示 :
- 初始化 sort_buffer,确定放入 name、city、age 这三个字段;
- 从索引 city 找到第一个满足 city=’杭州’条件的主键 id
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到 city 的值不满足查询条件为止;
- 对
sort_buffer中的数据按照字段 name 做快速排序; - 按照排序结果取前 1000 行返回给客户端。
我们暂且把这个排序过程,称为全字段排序,执行流程的示意图如下所示
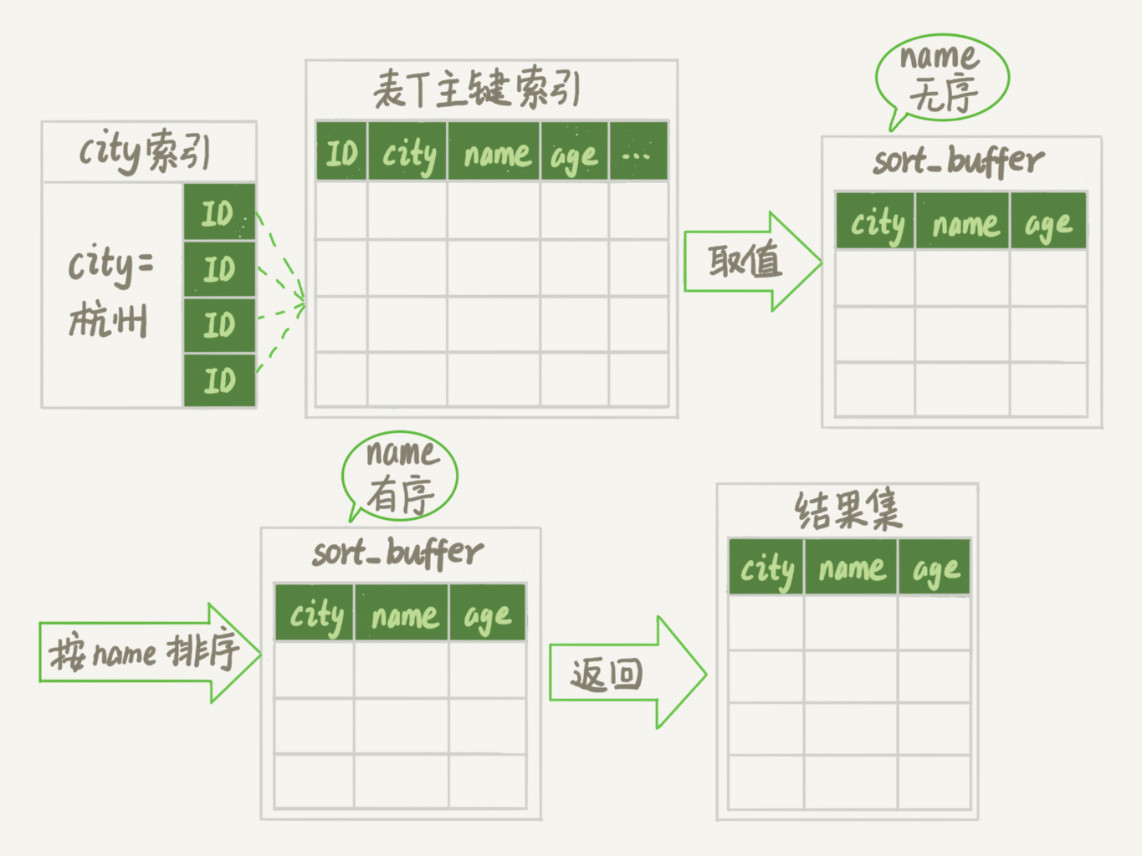
图中“按 name 排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size。
我们可以用下面介绍的方法,来确定一个排序语句是否使用了临时文件。
/* 打开optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* @a保存Innodb_rows_read的初始值 */
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 执行语句 */
select city, name,age from t where city='杭州' order by name limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
/* @b保存Innodb_rows_read的当前值 */
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 计算Innodb_rows_read差值 */
select @b-@a;
这个方法是通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从 number_of_tmp_files 中看到是否使用了临时文件。

number_of_tmp_files 表示的是,排序过程中使用的临时文件数。你一定奇怪,为什么需要 12 个文件?内存放不下时,就需要使用外部排序,外部排序一般使用归并排序算法。可以这么简单理解,MySQL 将需要排序的数据分成 12 份,每一份单独排序后存在这些临时文件中。然后把这 12 个有序文件再合并成一个有序的大文件。 如果 sort_buffer_size 超过了需要排序的数据量的大小,number_of_tmp_files 就是 0,表示排序可以直接在内存中完成。否则就需要放在临时文件中排序。sort_buffer_size 越小,需要分成的份数越多,number_of_tmp_files 的值就越大。
我们的示例表中有 4000 条满足 city=’杭州’的记录,所以你可以看到 examined_rows=4000,表示参与排序的行数是 4000 行。
sort_mode 里面的 packed_additional_fields 的意思是,排序过程对字符串做了“紧凑”处理。即使 name 字段的定义是 varchar(16),在排序过程中还是要按照实际长度来分配空间的。同时,最后一个查询语句 select @b-@a 的返回结果是 4000,表示整个执行过程只扫描了 4000 行。
这里需要注意的是,为了避免对结论造成干扰, internal_tmp_disk_storage_engine 设置成 MyISAM。否则,select @b-@a 的结果会显示为 4001。这是因为查询 OPTIMIZER_TRACE 这个表时,需要用到临时表,而 internal_tmp_disk_storage_engine 的默认值是 InnoDB。如果使用的是 InnoDB 引擎的话,把数据从临时表取出来的时候,会让 Innodb_rows_read 的值加 1。
rowid
排序在上面这个算法过程里面,只对原表的数据读了一遍,剩下的操作都是在 sort_buffer 和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
所以如果单行很大,这个方法效率不够好。那么,如果 MySQL 认为排序的单行长度太大会怎么做呢?
max_length_for_sort_data:MySQL 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。
mysql> SHOW VARIABLES LIKE '%max_length_for_sort_data%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| max_length_for_sort_data | 4096 |
+--------------------------+-------+
1 row in set (0.05 sec)
city、name、age 这三个字段的定义总长度是 36,我把 max_length_for_sort_data 设置为 16,我们再来看看计算过程有什么改变。
SET max_length_for_sort_data = 16;
新的算法放入 sort_buffer 的字段,只有要排序的列(即 name 字段)和主键 id。但这时,排序的结果就因为少了 city 和 age 字段的值,不能直接返回了,整个执行流程就变成如下所示的样子:
- 初始化 sort_buffer,确定放入两个字段,即 name 和 id;
- 从索引 city 找到第一个满足 city=’杭州’条件的主键id;
- 到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到不满足 city=’杭州’条件为止;
- 对 sort_buffer 中的数据按照字段 name 进行排序;
- 遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
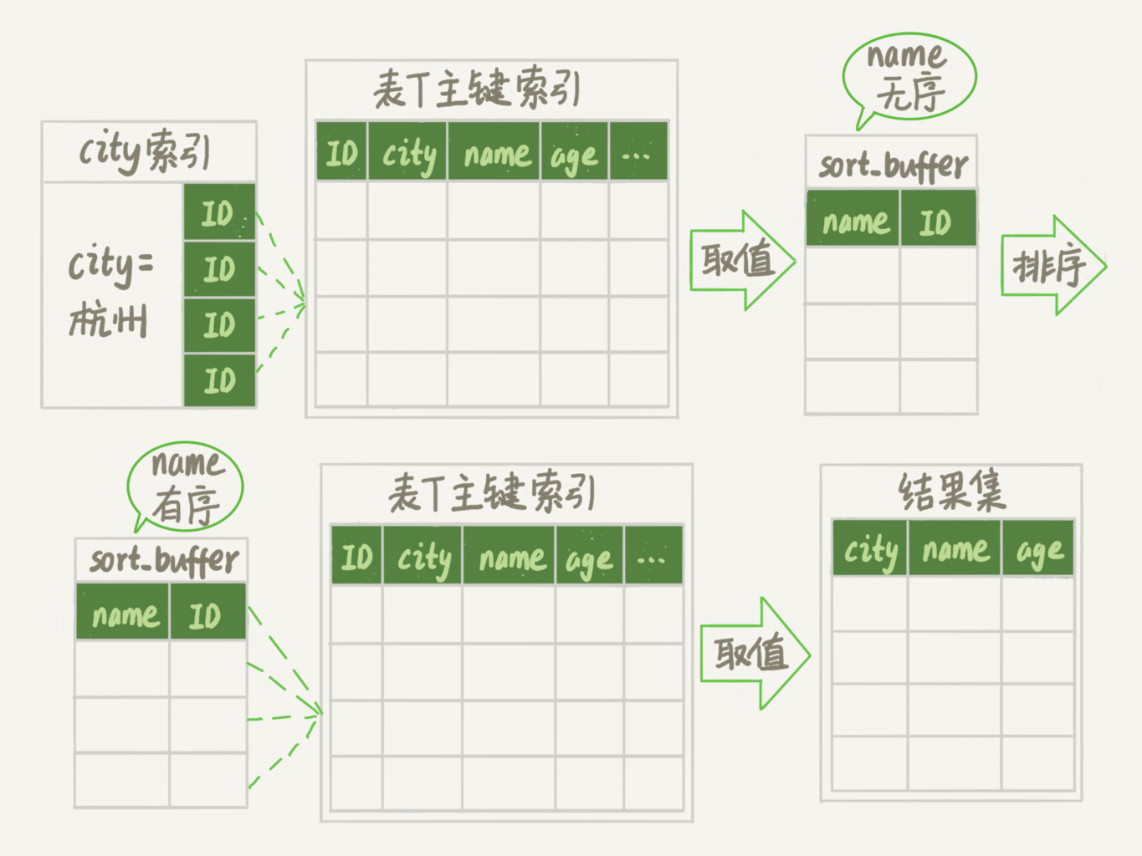
对比上面全字段排序流程图你会发现,rowid 排序多访问了一次表 t 的主键索引,就是步骤 7。
需要说明的是,最后的“结果集”是一个逻辑概念,实际上 MySQL 服务端从排序后的 sort_buffer 中依次取出 id,然后到原表查到 city、name 和 age 这三个字段的结果,不需要在服务端再耗费内存存储结果,是直接返回给客户端的。
这个时候执行 select @b-@a, examined_rows 的值还是 4000,表示用于排序的数据是 4000 行。但是 select @b-@a 这个语句的值变成 5000 了。因为这时候除了排序过程外,在排序完成后,还要根据 id 去原表取值。由于语句是 limit 1000,因此会多读 1000 行。

从 OPTIMIZER_TRACE 的结果中,你还能看到另外两个信息也变了。
sort_mode变成了<sort_key, rowid>,表示参与排序的只有 name 和 id 这两个字段。number_of_tmp_files变成 10 了,是因为这时候参与排序的行数虽然仍然是 4000 行,但是每一行都变小了,因此需要排序的总数据量就变小了,需要的临时文件也相应地变少了。
全字段排序 VS rowid 排序
如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法,这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。如果 MySQL 认为内存足够大,会优先选择全字段排序,把需要的字段都放到 sort buffer 中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。对于 InnoDB 表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择。
如果 sort buffer 无法存放所有数据,那么,当 sort buffer 被填满时,需要对 sort buffer 中的元组进行快速排序,并将排序结果写到一个单独临时文件中,同时保存该文件指针,直到所有的数据都被读取完成,最后对文件进行归并排序。
对于rowid排序来说,临时文件需要利用磁盘外部排序,将row id写入到结果文件中;然后根据结果文件中的row ID按序读取用户需要返回的数据。由于rowID不是顺序的,导致回表时是随机IO,为了进一步优化性能(变成顺序IO),MySQL会读一批row ID,并将读到的数据按排序字段顺序插入缓存区中(内存大小read_rnd_buffer_size )。
对于全字段排序来讲,其元组数据的长度会比 rowid排序更长,同时 sort buffer 能存放的元组数据更少,意味着产生的临时文件更多.因此,额外的磁盘 I/O 有可能会造成 全字段排序变得更慢,而不是更快。
其实,并不是所有的 order by 语句,都需要排序操作的。从上面分析的执行过程,我们可以看到,MySQL 之所以需要生成临时表,并且在临时表上做排序操作,其原因是原来的数据都是无序的。
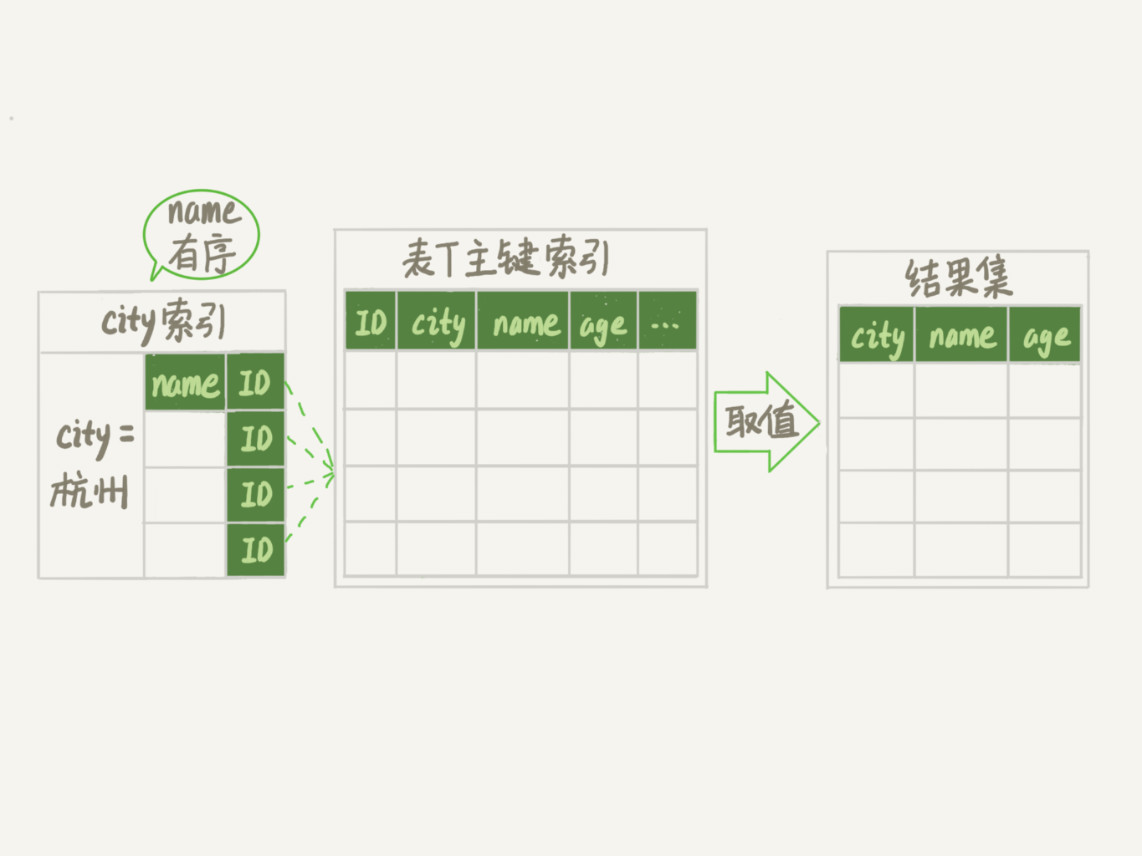
alter table t add index city_user(city, name);
这样整个查询过程的流程就变成了:
- 从索引 (city,name) 找到第一个满足 city=’杭州’条件的主键 id;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,作为结果集的一部分直接返回;
- 从索引 (city,name) 取下一个记录主键 id;
- 重复步骤 2、3,直到查到第 1000 条记录,或者是不满足 city=’杭州’条件时循环结束。
优先队列排序
5.6版本后针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式–优先队列,这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有元素参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
外部文件排序
我们先看一下普通外部排序
两路外部排序
假设内存只有100M,但是排序的数据有900M,那么对应的外部排序算法如下:
- 从要排序的900M数据中读取100MB数据到内存中,并按照传统的内部排序算法(快速排序)进行排序;
- 将排序好的数据写入磁盘;
- 重复1,2两步,直到每个100MB chunk大小排序好的数据都被写入磁盘;
- 每次读取排序好的chunk中前10MB(= 100MB / (9 chunks + 1))数据,一共9个chunk需要90MB,剩下的10MB作为输出缓存;
- 对这些数据进行一个“9路归并”,并将结果写入输出缓存。如果输出缓存满了,则直接写入最终排序结果文件并清空输出缓存;如果9个10MB的输入缓存空了,从对应的文件再读10MB的数据,直到读完整个文件。最终输出的排序结果文件就是900MB排好序的数据了。
多路外部排序
两路外部排序算法有一个问题,假设要排序的数据是50GB而内存只有100MB,那么每次从500个排序好的分片中取200KB(100MB / 501 约等于200KB)就是很多个随机IO。效率非常慢,对应可以这样来改进:
- 从要排序的50GB数据中读取100MB数据到内存中,并按照传统的内部排序算法(快速排序)进行排序;
- 将排序好的数据写入磁盘;
- 重复1,2两步,直到每个100MB chunk大小排序好的数据都被写入磁盘;
- 每次取25个分片进行归并排序,这样就形成了20个(500/25=20)更大的2.5GB有序的文件;
- 对这20个2.5GB的有序文件进行归并排序,形成最终排序结果文件。
对应的数据量更大的情况可以进行更多次归并。
MySQL外部排序
我们已rowid排序为例,看一下MySQL外部排序怎么做的
- 根据索引或者全表扫描,按照过滤条件获得需要查询的数据;
- 将要排序的列值和row ID组成键值对,存入sort buffer中;
- 如果sort buffer内存大于这些键值对的内存,就不需要创建临时文件了。否则,每次sort buffer填满以后,需要直接用qsort(快速排序模式)在内存中排好序,作为一个block写到临时文件中。跟正常的外部排序写到多个文件中不一样,MySQL只会写到一个临时文件中,并通过保存文件偏移量的方式来模拟多个文件归并排序;
- 重复上述步骤,直到所有的行数据都正常读取了完成;
- 每MERGEBUFF (7) 个block抽取一批数据进行排序,归并排序到另外一个临时文件中,直到所有的数据都排序好到新的临时文件中;
- 重复以上归并排序过程,直到剩下不到MERGEBUFF2 (15)个block。通俗一点解释:
- 第一次循环中,一个block对应一个sort buffer(大小为 sort_buffer_size )排序好的数据;每7个做一个归并。
- 第二次循环中,一个block对应MERGEBUFF (7) 个sort buffer的数据,每7个做一个归并。
- …
- 直到所有的block数量小于MERGEBUFF2 (15)。
- 最后一轮循环,仅将row ID写入到结果文件中;
- 根据结果文件中的row ID按序读取用户需要返回的数据。为了进一步优化性能,MySQL会读一批row ID,并将读到的数据按排序字段要求插入缓存区中(内存大小 read_rnd_buffer_size )。
trace结果解释
回过头来看一下trace的结果。
是否存在磁盘外部排序
number_of_tmp_files 表示有多少个分片,如果 number_of_tmp_files 不等于0,表示一个 sort_buffer_size 大小的内存无法保存所有的键值对,也就是说,MySQL在排序中使用到了磁盘来排序。
是否存在优先队列优化排序
由于我们的这个SQL里面没有对数据进行分页限制,所以 filesort_priority_queue_optimization 并没有启用
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
},
而正常情况下,使用了Limit会启用优先队列的优化。优先队列类似于FIFO先进先出队列。算法稍微有点改变,以rowid排序模式为例。
sort_buffer_size 足够大
如果Limit限制返回N条数据,并且N条数据比 sort_buffer_size 小,那么MySQL会把sort buffer作为priority queue,在第二步插入priority queue时会按序插入队列;在第三步,队列满了以后,并不会写入外部磁盘文件,而是直接淘汰最尾端的一条数据,直到所有的数据都正常读取完成。
算法如下:
- 根据索引或者全表扫描,按照过滤条件获得需要查询的数据
- 将要排序的列值和row ID组成键值对,按序存入中priority queue中
- 如果priority queue满了,直接淘汰最尾端记录。
- 重复上述步骤,直到所有的行数据都正常读取了完成
- 最后一轮循环,仅将row ID写入到结果文件中
- 根据结果文件中的row ID按序读取用户需要返回的数据。为了进一步优化性能,MySQL会读一批row ID,并将读到的数据按排序字段要求插入缓存区中(内存大小 read_rnd_buffer_size )。
sort_buffer_size 不够大
否则,N条数据比 sort_buffer_size 大的情况下,MySQL无法直接利用sort buffer作为priority queue,正常的文件外部排序还是一样的,只是在最后返回结果时,只根据N个row ID将数据返回出来。具体的算法我们就不列举了。
另外,我们也没有讨论Limit m,n的情况,如果是Limit m,n, 上面对应的“N个row ID”就是“M+N个row ID”了,MySQL的Limit m,n 其实是取m+n行数据,最后把M条数据丢掉。
从上面我们也可以看到 sort_buffer_size 足够大对Limit数据比较小的情况,优化效果是很明显的。
优先级队列是用的堆排序,是不稳定的排序算法
其他参数
MySQL其他相关排序参数
max_sort_length
这里需要区别 max_sort_length 和 max_length_for_sort_data 。max_length_for_sort_data 是为了让MySQL选择 < sort_key, rowid > 还是 < sort_key, additional_fields > 的模式。而 max_sort_length 是键值对的大小无法确定时(比如用户要查询的数据包含了 SUBSTRING_INDEX(col1, ‘.’,2) )MySQL会对每个键值对分配 max_sort_length 个字节的内存,这样导致内存空间浪费,磁盘外部排序次数过多。
innodb_disable_sort_file_cache
innodb_disable_sort_file_cache 设置为ON的话,表示在排序中生成的临时文件不会用到文件系统的缓存,类似于 O_DIRECT 打开文件。
innodb_sort_buffer_size
这个参数其实跟我们这里讨论的SQL排序没有什么关系。innodb_sort_buffer_size 设置的是在创建InnoDB索引时,使用到的sort buffer的大小。
以前写死为1M,现在开放出来,允许用户自定义设置这个参数了。
本地测试
准备数据
DELIMITER ;;
CREATE PROCEDURE idata()
BEGIN
DECLARE i INT;
SET i=0;
WHILE i<4000 DO
INSERT INTO t VALUES (i,'杭州',concat('edgar615',i),'20','XXX');
SET i=i+1;
END WHILE;
END;;
DELIMITER ;
CALL idata();
执行分析语句
"filesort_summary": {
"memory_available": 32768,
"key_size": 512,
"row_size": 652,
"max_rows_per_buffer": 50,
"num_rows_estimate": 16912,
"num_rows_found": 4000,
"num_initial_chunks_spilled_to_disk": 68,
"peak_memory_used": 32888,
"sort_algorithm": "std::sort",
"sort_mode": "<fixed_sort_key, packed_additional_fields>"
}
num_initial_chunks_spilled_to_disk=60,说明采用了外部排序,使用了磁盘临时文件peak_memory_used > memory_available:sort buffer空间不足- 如果
sort_buffer_size越小,num_initial_chunks_spilled_to_disk的值就越大 - 如果
sort_buffer_size足够大,那么num_initial_chunks_spilled_to_disk=0,采用内部排序 num_examined_rows=4000:参与排序的行数sort_mode含有的packed_additional_fields说明排序过程中对字符串做了紧凑处理: 字段name为VARCHAR(16),在排序过程中还是按照实际长度来分配空间
select @b-@a;返回4001
packed_additional_fields
MySQL有3种排序模式
< sort_key, rowid >对应的是MySQL 4.1之前的“原始排序模式”,即rowid排序< sort_key, additional_fields >对应的是MySQL 4.1以后引入的“修改后排序模式”即全字段排序< sort_key, packed_additional_fields >是MySQL 5.7.3以后引入的进一步优化的”打包数据排序模式”,是对全字段排序的优化。对于额外字段数据类型为:CHAR、VARCHAR、以及可为 NULL 的固定长度数据类型,其字段值长度是可以被压缩的。例如,在无压缩的情况下,字段数据类型为 VARCHAR(255),当字段值只有 3 个字符时,却需要占用 sort buffer 255 个字符长度的内存空间大小;而在有压缩的情况下,字段值为 3 个字符,却只占用 3 个字符长度 + 2 个字节长度标记的内存空间大小;当字段值为 NULL 时,只需通过一个位掩码来标识。
对于可压缩字段来讲,其真实数据长度会比最大长度更小,这就意味着 sort buffer 可以存放更多元组,临时文件数量更少,
修改max_length_for_sort_data
SET max_length_for_sort_data=16;
"filesort_summary": {
"memory_available": 32768,
"key_size": 516,
"row_size": 516,
"max_rows_per_buffer": 63,
"num_rows_estimate": 16912,
"num_rows_found": 4000,
"num_initial_chunks_spilled_to_disk": 65,
"peak_memory_used": 32784,
"sort_algorithm": "std::sort",
"unpacked_addon_fields": "max_length_for_sort_data",
"sort_mode": "<fixed_sort_key, rowid>"
}
"num_initial_chunks_spilled_to_disk": 65临时文件变少了- “sort_mode”: “<fixed_sort_key, rowid>” 采用rowid排序
select @b-@a;返回5001
关于 filesort 部分的跟踪日志的说明:
{
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "desc", // 排序方向
"table": "`film`", // 排序表名
"field": "release_year" // 排序字段
}
],
"filesort_priority_queue_optimization": { // 文件排序优先级队列优化
"usable": false, // 不可用
"cause": "not applicable (no LIMIT)" // 原因是没有使用 LIMIT 关键字
},
"filesort_execution": [
],
"filesort_summary": {
"rows": 10, // 排序记录数
"examined_rows": 10, // 检查记录数
"number_of_tmp_files": 0, // 临时文件数量
"sort_buffer_size": 32760, // 排序缓冲大小
"sort_mode": "<sort_key, rowid>" // 排序模式
}
}
]
}
}
参考资料
https://my.oschina.net/lvhuizhenblog/blog/552730
https://zhuanlan.zhihu.com/p/24410681
http://database.51cto.com/art/201710/555357.htm
https://www.36nu.com/post/197.html
https://cloud.tencent.com/developer/article/1072184
https://sq.163yun.com/blog/article/187292293774721024
https://www.zhb127.com/archives/mysql-order-by-filesort-internal.html
https://time.geekbang.org/column/article/73479
http://zhongmingmao.me/2019/02/09/mysql-order-by/
http://www.zuimoban.com/jiaocheng/mysql/8946.html
