基本复制自《Netty 核心原理剖析与 RPC 实践》
比较难懂,先占位吧
Netty 高性能的内存管理采用了 jemalloc 的思想,这是 FreeBSD 实现的一种并发 malloc 的算法。
jemalloc 依赖多个 Arena(分配器)来分配内存,运行中的应用都有固定数量的多个 Arena,默认的数量与处理器的个数有关。
系统中有多个 Arena 的原因是由于各个线程进行内存分配时竞争不可避免,这可能会极大的影响内存分配的效率,为了缓解高并发时的线程竞争,Netty 允许使用者创建多个分配器(Arena)来分离锁,提高内存分配效率。
线程首次分配/回收内存时,首先会为其分配一个固定的 Arena。线程选择 Arena 时使用 round-robin 的方式,也就是顺序轮流选取。
每个线程各种保存 Arena 和缓存池信息,这样可以减少竞争并提高访问效率。Arena 将内存分为很多 Chunk 进行管理,Chunk 内部保存 Page,以页为单位申请。
1. 内存规格
Netty 保留了内存规格分类的设计理念,不同大小的内存块采用的分配策略是不同的,具体内存规格的分类情况如下图所示。
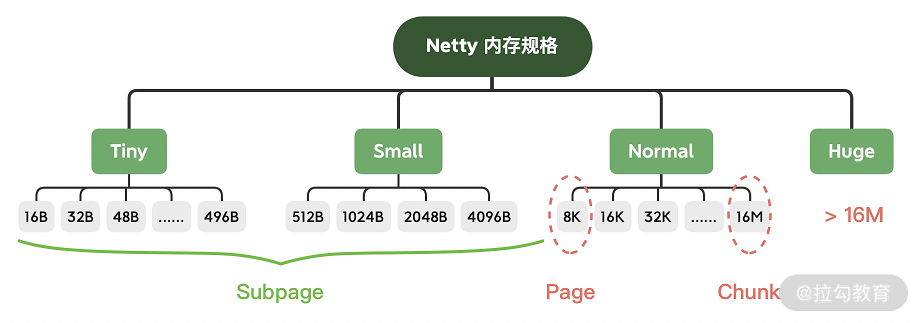
申请内存分配时,会将分配的规格分为如下四类,分别对应不同的范围,处理过程也不相同:
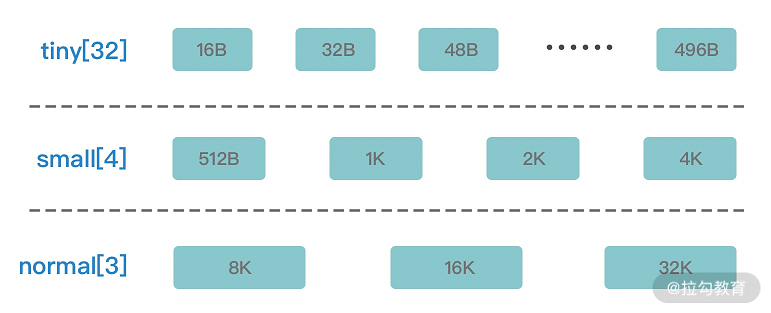
- tiny:代表了大小在 0-512B 的内存块。
- small:代表了大小在 512B-8K 的内存块。
- normal:代表了大小在 8K-16M 的内存块。
- huge:代表了大于 16M 的内存块。
Netty 在每个区域内又定义了更细粒度的内存分配单位,分别为 Chunk、Page、Subpage。
每个块里面又定义了更细粒度的单位来分配数据:
- Chunk 是 Netty 向操作系统申请内存的单位,后续所有的内存分配操作也是基于 Chunk 完成的,Chunk 可以理解为 Page 的集合,每个 Chunk 默认大小为 16M。
- Page 是 Chunk 用于管理内存的单位,Chunk 内部以 Page 为单位分配内存,Netty 中的 Page 的大小为 8K,不要与 Linux 中的内存页 Page 相混淆了。假如我们需要分配 64K 的内存,需要在 Chunk 中选取 8 个 Page 进行分配。
- Subpage 负责 Page 内的内存分配,假如我们分配的内存大小远小于 Page,直接分配一个 Page 会造成严重的内存浪费,所以需要将 Page 划分为多个相同的子块进行分配,这里的子块就相当于 Subpage。按照 Tiny 和 Small 两种内存规格,SubPage 的大小也会分为两种情况。在 Tiny 场景下,最小的划分单位为 16B,按 16B 依次递增,16B、32B、48B …… 496B;在 Small 场景下,总共可以划分为 512B、1024B、2048B、4096B 四种情况。Subpage 没有固定的大小,需要根据用户分配的缓冲区大小决定,例如分配 1K 的内存时,Netty 会把一个 Page 等分为 8 个 1K 的 Subpage。
2. Chunk 中的内存分配
2.1. Page级别
Netty 中负责线程分配的组件有两个:PoolArena和PoolThreadCache。PoolArena 是多个线程共享的,每个线程会固定绑定一个 PoolArena,PoolThreadCache 是每个线程私有的缓存空间,如下图所示。

初次申请内存的时候,Netty 会从一整块内存(Chunk)中分出一部分来给用户使用,这部分工作是由 Arena 来完成。而当用户使用完毕释放内存的时候,不会立即会还给Chunk, 这些被分出来的内存会按不同规格大小放在 PoolThreadCache 中缓存起来。当下次要申请内存的时候,就会先从 PoolThreadCache 中找。
Chunk、Page、Subpage 都是 Arena 中的概念,Arena 的工作就是从一整块内存中分出合适大小的内存块。Arena 中最大的内存单位是 Chunk,这是 Netty 向操作系统申请内存的单位。而一块 Chunk(16M) 申请下来之后,内部会被分成 2048 个 Page(8K)。
Netty 中不同的内存规格采用的分配策略是不同的。
-
分配内存大于 8K 时,Chunk 中采用的 Page 级别的内存分配策略。
-
分配内存小于 8K 时,由 Subpage 负责管理的内存分配策略。
-
分配内存小于 8K 时,为了提高内存分配效率,由 PoolThreadCache 本地线程缓存提供的内存分配。
Chunk 内部通过伙伴算法管理 Page,具体实现为一棵完全平衡二叉树:
每个 Chunk 默认大小为 16M,每个 Chunk 被划分为 2048 个 Page,Chunk 是通过伙伴算法管理多个 Page,最终通过一颗满二叉树实现。

二叉树中所有子节点管理的内存也属于其父节点。当我们要申请大小为 16K 的内存时,我们会从根节点开始不断寻找可用的节点,一直到第 10 层。
那么如何判断一个节点是否可用呢?Netty 会在每个节点内部保存一个值,这个值代表这个节点之下的第几层还存在未分配的节点。比如第 9 层的节点的值如果为 9,就代表这个节点本身到下面所有的子节点都未分配。
- 如果第 9 层的节点的值为 10,代表它本身不可被分配,但第 10 层有子节点可以被分配。
- 如果第 9 层的节点的值为 12,此时可分配节点的深度大于了总深度,代表这个节点及其下面的所有子节点都不可被分配。
下图描述了分配的过程:

2.1. Subpage级别
为了提高内存分配的利用率,在分配小于 8K 的内存时,Chunk 不在分配单独的 Page,而是将 Page 划分为更小的内存块,由 Subpage 进行管理。
Subpage 按大小分有两大类:
- Tiny:小于 512 的情况,最小空间为 16,对齐大小为 16,区间为[16,512),所以共有 32 种情况。
- Small:大于等于 512 的情况,总共有四种:512,1024,2048,4096。
PoolSubpage 中直接采用位图管理空闲空间(因为不存在申请 k 个连续的空间),所以申请释放非常简单。
假设需要分配 20B 大小的内存,按照内存规格的分类 20B 需要向上取整到 32B。8K/32B = 256,因为每个 long 有 64 位,所以需要 256/64 = 4 个 long 类型的即可描述全部的内存块分配状态,因此 bitmap 数组的长度为 4,从 bitmap[0] 开始记录,每分配一个内存块,就会移动到 bitmap[0] 中的下一个二进制位,直至 bitmap[0] 的所有二进制位都赋值为 1,然后继续分配 bitmap[1]。
第一次申请小内存空间的时候,需要先申请一个空闲页,然后将该页转成 PoolSubpage,再将该页设为已被占用,最后再把这个 PoolSubpage 存到 PoolSubpage 池中。这样下次就不需要再去申请空闲页了,直接去池中找就好了。Netty 中有 36 种 PoolSubpage,所以用 36 个 PoolSubpage 链表表示 PoolSubpage 池。
因为单个 PoolChunk 只有 16M,这远远不够用,所以会很很多很多 PoolChunk,这些 PoolChunk 组成一个链表,然后用 PoolChunkList 持有这个链表。
3. 内存池架构设计

基于上图的内存池模型,Netty 抽象出一些核心组件,如 PoolArena、PoolChunk、PoolChunkList、PoolSubpage、PoolThreadCache、MemoryRegionCache 等。
3.1. PoolArena
Netty 借鉴了 jemalloc 中 Arena 的设计思想,采用固定数量的多个 Arena 进行内存分配,Arena 的默认数量与 CPU 核数有关,通过创建多个 Arena 来缓解资源竞争问题,从而提高内存分配效率。线程在首次申请分配内存时,会通过 round-robin 的方式轮询 Arena 数组,选择一个固定的 Arena,在线程的生命周期内只与该 Arena 打交道,所以每个线程都保存了 Arena 信息,从而提高访问效率。
根据分配内存的类型,ByteBuf 可以分为 Heap 和 Direct,同样 PoolArena 抽象类提供了 HeapArena 和 DirectArena 两个内部子类。HeapArena 对应堆内存(heap buffer),DirectArena 对应堆外直接内存(direct buffer),两者除了操作的内存(byte[] 和 ByteBuffer)不同外其余完全一致。
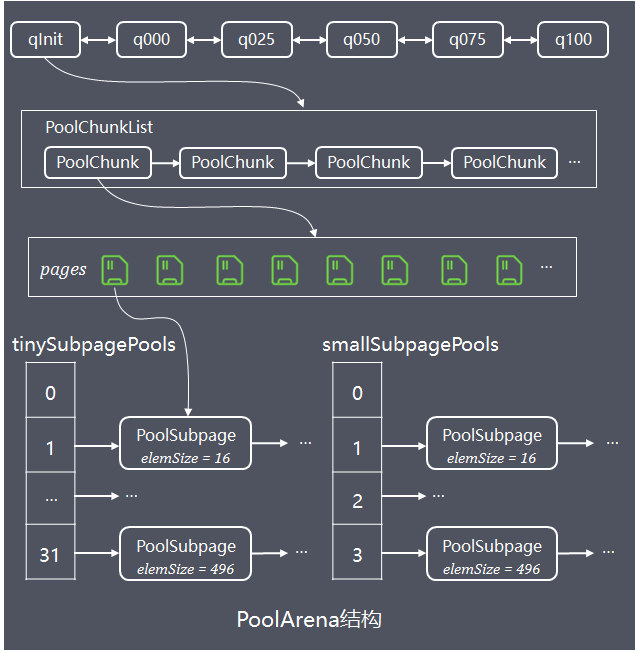
首先看下 PoolArena 的数据结构,如下图所示。
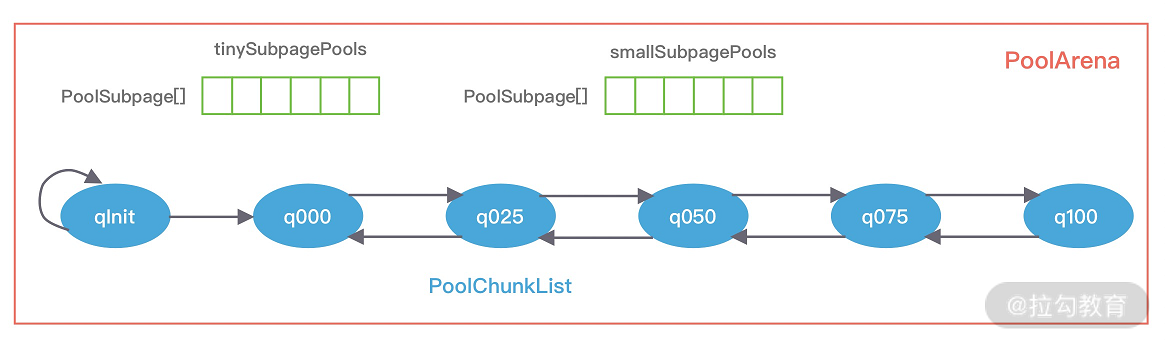
从结构上来看,PoolArena 中主要包含三部分子内存池:
- tinySubpagePools
- smallSubpagePools
- 一系列的 PoolChunkList
tinySubpagePools 和 smallSubpagePools 都是 PoolSubpage 的数组,数组长度分别为 32 和 4。对应了前面说的Subpage的两种情况: Tiny 场景下,内存单位最小为 16B,按 16B 依次递增,共 32 种情况;Small 场景下共分为 512B、1024B、2048B、4096B 四种情况。每种粒度的内存单位都由一个 PoolSubpage 进行管理。假如我们分配 20B 大小的内存空间,也会向上取整找到 32B 的 PoolSubpage 节点进行分配。
PoolChunkList 是一个容器,其内部可以保存一系列的 PoolChunk 对象,并且,Netty 会根据内存使用率的不同,将 PoolChunkList 分为不同等级的容器,它们构成一个双向循环链表。
PoolArena 对应实现了 Subpage 和 Chunk 中的内存分配,其 中 PoolSubpage 用于分配小于 8K 的内存,PoolChunkList 用于分配大于 8K 的内存。
PoolSubpage 也是按照 Tiny 和 Small 两种内存规格,设计了tinySubpagePools 和 smallSubpagePools 两个数组,根据关于 Subpage 的介绍,我们知道 Tiny 场景下,内存单位最小为 16B,按 16B 依次递增,共 32 种情况,Small 场景下共分为 512B、1024B、2048B、4096B 四种情况,分别对应两个数组的长度大小,
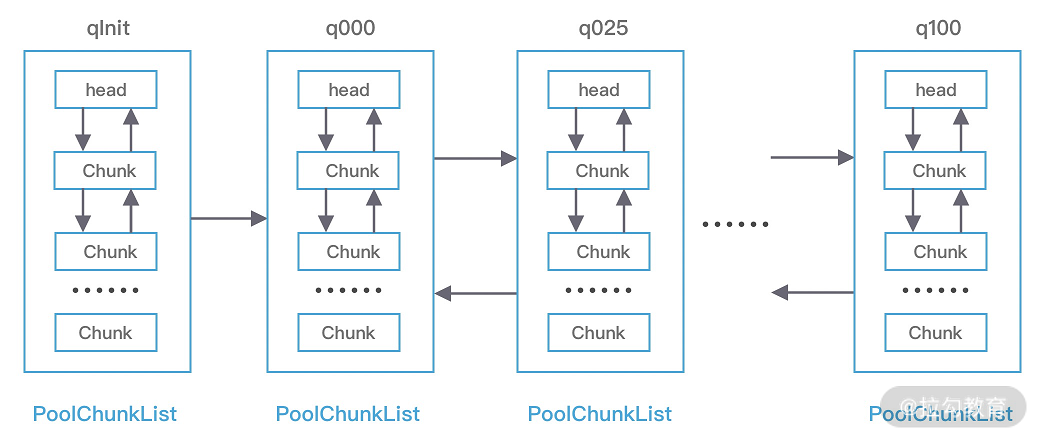
PoolChunkList 用于 Chunk 场景下的内存分配,PoolArena 中初始化了六个 PoolChunkList,分别为 qInit、q000、q025、q050、q075、q100,这与 jemalloc 中 run 队列思路是一致的,它们分别代表不同的内存使用率,如下所示:
-
qInit,内存使用率为 0 ~ 25% 的 Chunk。
-
q000,内存使用率为 1 ~ 50% 的 Chunk。
-
q025,内存使用率为 25% ~ 75% 的 Chunk。
-
q050,内存使用率为 50% ~ 100% 的 Chunk。
-
q075,内存使用率为 75% ~ 100% 的 Chunk。
-
q100,内存使用率为 100% 的 Chunk。
六种类型的 PoolChunkList 除了 qInit,它们之间都形成了双向链表,如下图所示。

分配内存时,PoolArena 通过在 PoolChunkList 找到一个合适的 PoolChunk,然后从 PoolChunk 中分配一块内存。随着 Chunk 内存使用率的变化,Netty 会重新检查内存的使用率并放入对应的 PoolChunkList,所以 PoolChunk 会在不同的 PoolChunkList 移动。
qInit 和 q000 为什么需要设计成两个,是否可以合并成一个?
qInit 用于存储初始分配的 PoolChunk,因为在第一次内存分配时,PoolChunkList 中并没有可用的 PoolChunk,所以需要新创建一个 PoolChunk 并添加到 qInit 列表中。qInit 中的 PoolChunk 即使内存被完全释放也不会被回收,避免 PoolChunk 的重复初始化工作。
q000 则用于存放内存使用率为 1 ~ 50% 的 PoolChunk,q000 中的 PoolChunk 内存被完全释放后,PoolChunk 从链表中移除,对应分配的内存也会被回收。
我们看一下PoolArena 是如何分配内存的,我的这个版本移除了tiny
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
// 计算在数组中的位移
final int sizeIdx = size2SizeIdx(reqCapacity);
// 判断目标容量是否小于8KB,小于8KB则使用small的方式申请内存
if (sizeIdx <= smallMaxSizeIdx) {
// 先尝试从当前线程缓存中申请到内存
tcacheAllocateSmall(cache, buf, reqCapacity, sizeIdx);
} else if (sizeIdx < nSizes) {
// normal
tcacheAllocateNormal(cache, buf, reqCapacity, sizeIdx);
} else {
int normCapacity = directMemoryCacheAlignment > 0
? normalizeSize(reqCapacity) : reqCapacity;
// Huge allocations are never served via the cache so just call allocateHuge
// 大页
allocateHuge(buf, normCapacity);
}
}
private void tcacheAllocateSmall(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity,
final int sizeIdx) {
// 先尝试从当前线程缓存中申请到内存
if (cache.allocateSmall(this, buf, reqCapacity, sizeIdx)) {
// was able to allocate out of the cache so move on
return;
}
// 获取目标元素的头结点
final PoolSubpage<T> head = smallSubpagePools[sizeIdx];
final boolean needsNormalAllocation;
// 加锁
synchronized (head) {
final PoolSubpage<T> s = head.next;
// s != head就证明当前PoolSubpage链表中存在可用的PoolSubpage,并且一定能够申请到内存,
// 因为已经耗尽的PoolSubpage是会从链表中移除的
needsNormalAllocation = s == head;
if (!needsNormalAllocation) {
// 从PoolSubpage中申请内存
assert s.doNotDestroy && s.elemSize == sizeIdx2size(sizeIdx);
// 通过申请的内存对ByteBuf进行初始化
long handle = s.allocate();
assert handle >= 0;
// 初始化 PoolByteBuf 说明其位置被分配到该区域,但此时尚未分配内存
s.chunk.initBufWithSubpage(buf, null, handle, reqCapacity, cache);
}
}
if (needsNormalAllocation) {
synchronized (this) {
// 走到这里,说明目标PoolSubpage链表中无法申请到目标内存块,因而就尝试从PoolChunk中申请
allocateNormal(buf, reqCapacity, sizeIdx, cache);
}
}
incSmallAllocation();
}
还有一点需要注意的是,在分配大于 8K 的内存时,其链表的访问顺序是 q050->q025->q000->qInit->q075,遍历检查 PoolChunkList 中是否有 PoolChunk 可以用于内存分配,源码如下:
// Method must be called inside synchronized(this) { ... } block
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache threadCache) {
// 按照 q050→q025→q000→qInit→q075 申请,如果在对应的PoolChunkList能申请到内存,则返回
if (q050.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q025.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q000.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
qInit.allocate(buf, reqCapacity, sizeIdx, threadCache) ||
q075.allocate(buf, reqCapacity, sizeIdx, threadCache)) {
return;
}
// 如果申请不到,那么直接创建一个新的 PoolChunk,然后在该 PoolChunk 中申请目标内存,最后将该 PoolChunk 添加到 qInit 中
PoolChunk<T> c = newChunk(pageSize, nPSizes, pageShifts, chunkSize);
boolean success = c.allocate(buf, reqCapacity, sizeIdx, threadCache);
assert success;
qInit.add(c);
}
这是一个折中的选择,在频繁分配内存的场景下,如果从 q000 开始,会有大部分的 PoolChunk 面临频繁的创建和销毁,造成内存分配的性能降低。如果从 q050 开始,会使 PoolChunk 的使用率范围保持在中间水平,降低了 PoolChunk 被回收的概率,从而兼顾了性能。
分配后各个区间内存使用率更多处于[75,100)的区间范围内,提高PoolChunk内存使用率的同时也兼顾效率,减少在PoolChunkList中PoolChunk的遍历
3.2. PoolChunkList
PoolChunkList 负责管理多个 PoolChunk 的生命周期,同一个 PoolChunkList 中存放内存使用率相近的 PoolChunk,这些 PoolChunk 同样以双向链表的形式连接在一起,PoolChunkList 的结构如下图所示。因为 PoolChunk 经常要从 PoolChunkList 中删除,并且需要在不同的 PoolChunkList 中移动,所以双向链表是管理 PoolChunk 时间复杂度较低的数据结构。
每个 PoolChunkList 都有内存使用率的上下限:minUsage 和 maxUsage,当 PoolChunk 进行内存分配后,如果使用率超过 maxUsage,那么 PoolChunk 会从当前 PoolChunkList 移除,并移动到下一个 PoolChunkList。同理,PoolChunk 中的内存发生释放后,如果使用率小于 minUsage,那么 PoolChunk 会从当前 PoolChunkList 移除,并移动到前一个 PoolChunkList。
private final int minUsage;
private final int maxUsage;
private final int maxCapacity;
回过头再看下 Netty 初始化的六个 PoolChunkList,每个 PoolChunkList 的上下限都有交叉重叠的部分,如下图所示。因为 PoolChunk 需要在 PoolChunkList 不断移动,如果每个 PoolChunkList 的内存使用率的临界值都是恰好衔接的,例如 1 ~ 50%、50% ~ 75%,那么如果 PoolChunk 的使用率一直处于 50% 的临界值,会导致 PoolChunk 在两个 PoolChunkList 不断移动,造成性能损耗。

3.3. PoolChunk
Netty 内存的分配和回收都是基于 PoolChunk 完成的,PoolChunk 是真正存储内存数据的地方,每个 PoolChunk 的默认大小为 16M。
PoolChunk 可以理解为 Page 的集合,Page 只是一种抽象的概念,实际在 Netty 中 Page 所指的是 PoolChunk 所管理的子内存块,每个子内存块采用 PoolSubpage 表示。在同一个chunk中,Netty将page按照不同粒度进行多层分组管理:

- 第1层,分组大小size = 1*pageSize,一共有2048个组
- 第2层,分组大小size = 2*pageSize,一共有1024个组
- 第3层,分组大小size = 4*pageSize,一共有512个组 …
当请求分配内存时,将请求分配的内存数向上取值到最接近的分组大小,在该分组大小的相应层级中从左至右寻找空闲分组
例如请求分配内存对象为1.5 *pageSize,向上取值到分组大小2 * pageSize,在该层分组中找到完全空闲的一组内存进行分配,如下图:

当分组大小2 * pageSize的内存分配出去后,为了方便下次内存分配,分组被标记为全部已使用(图中红色标记),向上更粗粒度的内存分组被标记为部分已使用(图中黄色标记)
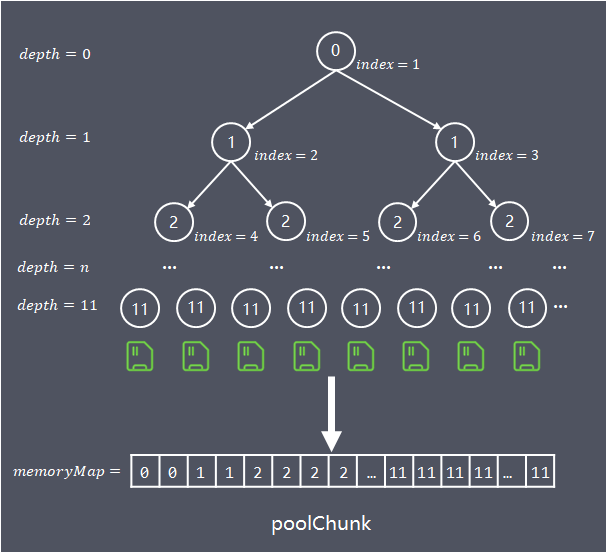
Netty 会使用伙伴算法将 PoolChunk 分配成 2048 个 Page,最终形成一颗满二叉树,二叉树中所有子节点的内存都属于其父节点管理。如下图所示。
当需要创建一个给定大小的ByteBuf,算法需要在PoolChunk中大小为chunkSize的内存中,找到第一个能够容纳申请分配内存的位置
为了方便快速查找chunk中能容纳请求内存的位置,算法构建一个基于byte数组(memoryMap)存储的完全平衡树,该平衡树的多个层级深度,就是前面介绍的按照不同粒度对chunk进行多层分组。
树的深度depth从0开始计算,各层节点数,每个节点对应的内存大小如下:
depth = 0, 1 node,nodeSize = chunkSize
depth = 1, 2 nodes,nodeSize = chunkSize/2
...
depth = d, 2^d nodes, nodeSize = chunkSize/(2^d)
...
depth = maxOrder, 2^maxOrder nodes, nodeSize = chunkSize/2^{maxOrder} = pageSize
树的最大深度为maxOrder(最大阶,默认值11),通过这棵树,算法在chunk中的查找就可以转换为:
当申请分配大小为chunkSize/2^k的内存,在平衡树高度为k的层级中,从左到右搜索第一个空闲节点
数组的使用域从index = 1开始,将平衡树按照层次顺序依次存储在数组中,depth = n的第1个节点保存在memoryMap[2^n] 中,第2个节点保存在memoryMap[2^n+1]中,以此类推(下图中已分配chunkSize/2)
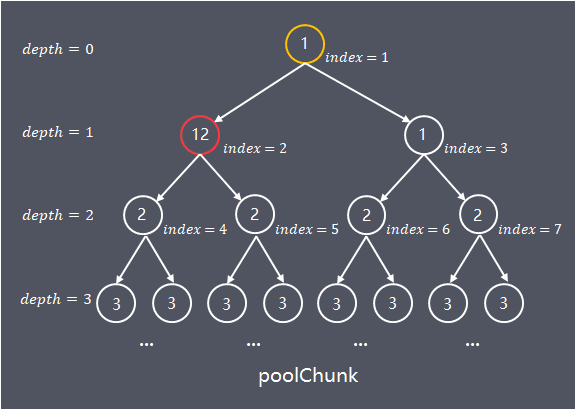
可以根据memoryMap[id]的值得出节点的使用情况,memoryMap[id]值越大,剩余的可用内存越少
- memoryMap[id] = depth_of_id:id节点空闲, 初始状态,depth_of_id的值代表id节点在树中的深度
- memoryMap[id] = maxOrder + 1:id节点全部已使用,节点内存已完全分配,没有一个子节点空闲
- depth_of_id < memoryMap[id] < maxOrder + 1:id节点部分已使用,memoryMap[id] 的值 x,代表id的子节点中,第一个空闲节点位于深度x,在深度[depth_of_id, x)的范围内没有任何空闲节点
3.4. PoolSubpage
在小内存分配的场景下,即分配的内存大小小于一个 Page 8K,会使用 PoolSubpage 进行管理。
相同规格大小(elemSize)的PoolSubpage组成链表,不同规格的PoolSubpage链表的head则分别保存在tinySubpagePools 或者 smallSubpagePools数组中,如下图:
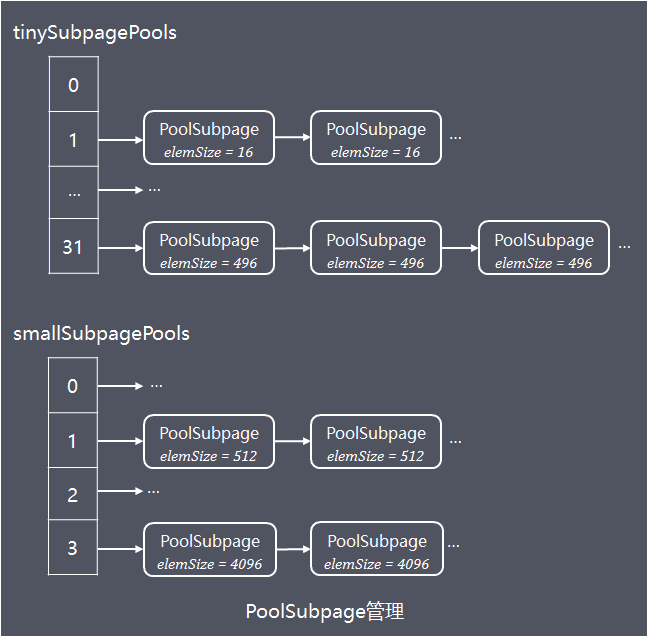
当需要分配小内存对象到PoolSubpage中时,根据归一化后的大小,计算出需要访问的PoolSubpage链表在tinySubpagePools和smallSubpagePools数组的下标,访问链表中的PoolSubpage的申请内存分配,如果访问到的PoolSubpage链表节点数为0,则创建新的PoolSubpage分配内存然后加入链表。
PoolSubpage链表存储的PoolSubpage都是已分配部分内存,当内存全部分配完或者内存全部释放完的PoolSubpage会移出链表,减少不必要的链表节点;当PoolSubpage内存全部分配完后再释放部分内存,会重新将加入链表。
PoolSubpage 通过位图 bitmap 记录子内存是否已经被使用,bit 的取值为 0 或者 1,如下图所示。

PoolSubpage 和 PoolArena 之间是如何联系起来的?
PoolArena 在创建是会初始化 tinySubpagePools 和 smallSubpagePools 两个 PoolSubpage 数组,数组的大小分别为 32 和 4。
假如我们现在需要分配 20B 大小的内存,会向上取整为 32B,从满二叉树的第 11 层找到一个 PoolSubpage 节点,并把它等分为 8KB/32B = 256B 个小内存块,然后找到这个 PoolSubpage 节点对应的 PoolArena,将 PoolSubpage 节点与 tinySubpagePools[1] 对应的 head 节点连接成双向链表,形成下图所示的结构。

下次再有 32B 规格的内存分配时,会直接查找 PoolArena 中 tinySubpagePools[1] 元素的 next 节点是否存在可用的 PoolSubpage,如果存在将直接使用该 PoolSubpage 执行内存分配,从而提高了内存分配效率,其他内存规格的分配原理类似。
3.5. PoolThreadCache
当内存释放时,与 jemalloc 一样,Netty 并没有将缓存归还给 PoolChunk,而是使用 PoolThreadCache 缓存起来,当下次有同样规格的内存分配时,直接从 PoolThreadCache 取出使用即可。PoolThreadCache 缓存 Tiny、Small、Normal 三种类型的数据,而且根据堆内和堆外内存的类型进行了区分。
final PoolArena<byte[]> heapArena;
final PoolArena<ByteBuffer> directArena;
// Hold the caches for the different size classes, which are tiny, small and normal.
// MemoryRegionCache 有三个重要的属性,分别为 queue,sizeClass 和 size
private final MemoryRegionCache<byte[]>[] smallSubPageHeapCaches;
private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches;
private final MemoryRegionCache<byte[]>[] normalHeapCaches;
private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches;
private final int freeSweepAllocationThreshold;
private final AtomicBoolean freed = new AtomicBoolean();
private int allocations;
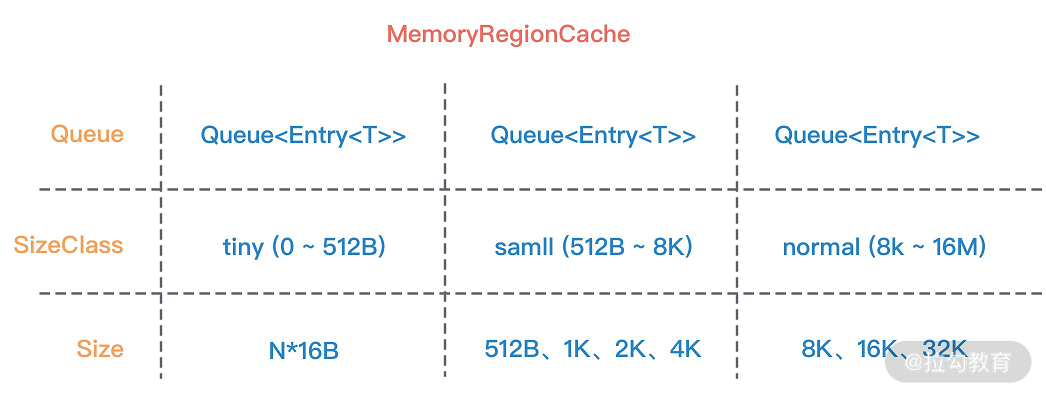
MemoryRegionCache 实际就是一个队列,当内存释放时,将内存块加入队列当中,下次再分配同样规格的内存时,直接从队列中取出空闲的内存块。
PoolThreadCache 将不同规格大小的内存都使用单独的 MemoryRegionCache 维护,如下图所示,图中的每个节点都对应一个 MemoryRegionCache,例如 Tiny 场景下对应的 32 种内存规格会使用 32 个 MemoryRegionCache 维护,所以 PoolThreadCache 源码中 Tiny、Small、Normal 类型的 MemoryRegionCache 数组长度分别为 32、4、3。
3.7. 释放
对于内存的释放,PoolArena 主要是分为两种情况,即池化和非池化,如果是非池化,则会直接销毁目标内存块,如果是池化的,则会将其添加到当前线程的缓存中。
3.6. 总结
PoolArean内存池弹性伸缩可用下图总结:
4. 参考资料
https://mp.weixin.qq.com/s/ucde30LdnK17iSaIJw4nzg
https://mp.weixin.qq.com/s/79GGHdj0ZT3dndDA9GfT0g
《Netty 核心原理剖析与 RPC 实践》
