基本复制自《Netty 核心原理剖析与 RPC 实践》
在 TCP 网络编程中,发送方和接收方的数据包格式都是二进制,发送方将对象转化成二进制流发送给接收方,接收方获得二进制数据后需要知道如何解析成对象,所以协议是双方能够正常通信的基础。
一次完整调用会经过这样几个步骤:
- 客户端持续把请求参数编码成二进制数据,经过 TCP 传输到服务端;
- 服务端从 TCP 通道里面接收到二进制数据;
- 根据协议,服务端将二进制数据分割出不同的请求数据,经过解码将二进制数据逆向还原出请求对象
- 然后服务端再把执行结果编码后,回写到对应的 TCP 通道里面;
- 调用方获取到应答的数据包后,再解码成应答对象。
Netty 常用编码器类型:
- MessageToByteEncoder 对象编码成字节流;
- MessageToMessageEncoder 一种消息类型编码成另外一种消息类型。
Netty 常用解码器类型:
- ByteToMessageDecoder/ReplayingDecoder 将字节流解码为消息对象;
- MessageToMessageDecoder 将一种消息类型解码为另外一种消息类型。
编解码器可以分为一次解码器和二次解码器,一次解码器用于解决 TCP 拆包/粘包问题,按协议解析后得到的字节数据。如果你需要对解析后的字节数据做对象模型的转换,这时候便需要用到二次解码器,同理编码器的过程是反过来的。
- 一次编解码器:MessageToByteEncoder/ByteToMessageDecoder。数据始终是ByteBuf类型的,原始数据流(ByteBuf)<—>用户数据(ByteBuf)
- 二次编解码器:MessageToMessageEncoder/MessageToMessageDecoder。用户数据(ByteBuf)<—> Object
1. 解码器
解码类是 ChanneInboundHandler 的抽象类实现,操作的是 Inbound 入站数据。解码器实现的难度要远大于编码器,因为解码器需要考虑拆包/粘包问题。由于接收方有可能没有接收到完整的消息,所以解码框架需要对入站的数据做缓冲操作,直至获取到完整的消息。
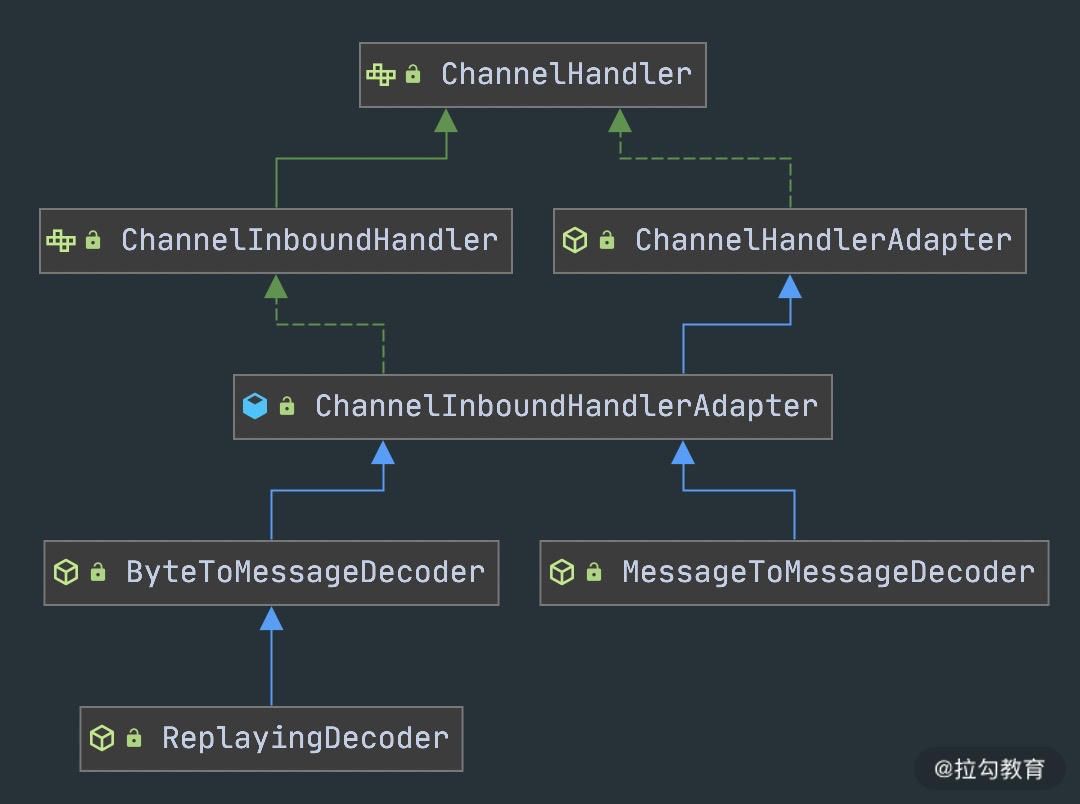
1.1. ByteToMessageDecoder
从上图我们知道ByteToMessageDecoder实现了ChannelInboundHandler接口,那么它必然会有一个读取数据的地方作为解码的入口。
/**
* Invoked when the current {@link Channel} has read a message from the peer.
*/
void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception;
找到ByteToMessageDecoder的channelRead方法,可以看到它只处理ByteBuf类型的数据。
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
// msg就是我们的数据,
if (msg instanceof ByteBuf) {
...
} else {
// 只处理ByteBuf类型的数据
ctx.fireChannelRead(msg);
}
}
进入channelRead内部看一下,它将读取到的数据存入了cumulation,而cumulation也是一个ByteBuf,它是一个数据积累器。
first = cumulation == null;
// 如果是第一次读取,使用一个空的ByteBuf,否则就是之前的cumulation
cumulation = cumulator.cumulate(ctx.alloc(),
first ? Unpooled.EMPTY_BUFFER : cumulation, (ByteBuf) msg);
callDecode(ctx, cumulation, out);
数据积累的功能是由cumulator实现,主要是一些ByteBuf处理的过程。
每次读取到消息后,就会通过callDecode方法进行解码。
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
try {
while (in.isReadable()) {
// 此时没有数据,outSize是0
int outSize = out.size();
if (outSize > 0) {
...
}
// 读取长度
int oldInputLength = in.readableBytes();
// 调用具体的decode,方法名上已经说明了decode的过程不能处理清理数据的工作
decodeRemovalReentryProtection(ctx, in, out);
...
}
} catch (e) {
...
}
}
进入decodeRemovalReentryProtection方法,这里执行了decode方法
final void decodeRemovalReentryProtection(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)
throws Exception {
...
try {
decode(ctx, in, out);
} finally {
...
}
}
decode方法是一个抽象方法,由ByteToMessageDecoder的子类实现。
我们看一下FixedLengthFrameDecoder
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
Object decoded = decode(ctx, in);
// 解码出数据,存入list,传递给下一个ChannelInboundHandler,在channelRead方法的finally块里调用了fireChannelRead(ctx, out, size);方法
if (decoded != null) {
out.add(decoded);
}
}
protected Object decode(
@SuppressWarnings("UnusedParameters") ChannelHandlerContext ctx, ByteBuf in) throws Exception {
// 判断收集到的数据的长度
if (in.readableBytes() < frameLength) {
return null;
} else {
return in.readRetainedSlice(frameLength);
}
}
DelimiterBasedFrameDecoder和LengthFieldBasedFrameDecoder的实现原理差不多。
此外 ByteToMessageDecoder 还定义了 decodeLast() 方法。为什么抽象解码器要比编码器多一个 decodeLast() 方法呢?因为 decodeLast 在 Channel 关闭后会被调用一次,主要用于处理 ByteBuf 最后剩余的字节数据。Netty 中 decodeLast 的默认实现只是简单调用了 decode() 方法。如果有特殊的业务需求,则可以通过重写 decodeLast() 方法扩展自定义逻辑。
1.2. MessageToMessageDecoder
了解了ByteToMessageDecoder后,MessageToMessageDecoder就很好理解了。与 ByteToMessageDecoder 不同的是 MessageToMessageDecoder 并不会对数据报文进行缓存,它主要用作转换消息模型。比较推荐的做法是使用 ByteToMessageDecoder 解析 TCP 协议,解决拆包/粘包问题。解析得到有效的 ByteBuf 数据,然后传递给后续的 MessageToMessageDecoder 做数据对象的转换。
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
...
try {
// 检查msg的类型是否是解码器定义的类型(泛型)
if (acceptInboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
try {
// 调用子类的decode方法
decode(ctx, cast, out);
} finally {
ReferenceCountUtil.release(cast);
}
} else {
out.add(msg);
}
}
...
}
2. 编码器
通过抽象编码类的继承图可以看出,编码类是 ChanneOutboundHandler 的抽象类实现,具体操作的是 Outbound 出站数据。
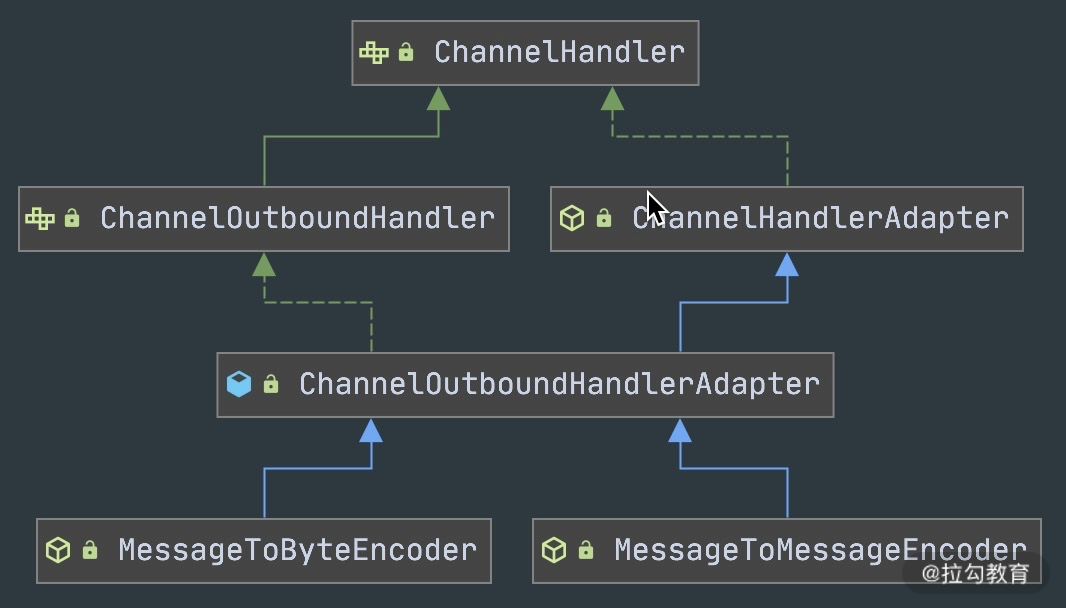
从上图我们知道MessageToByteEncoder实现了ChannelOutboundHandler接口,那么它必然会有一个写入数据的地方作为编码的入口。
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ByteBuf buf = null;
try {
// 检查msg的类型是否是编码器定义的类型(泛型)
if (acceptOutboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
// 分配 ByteBuf 资源
buf = allocateBuffer(ctx, cast, preferDirect);
try {
// 调用子类的encode方法
encode(ctx, cast, buf);
} finally {
// 一旦消息被成功编码,会通过调用 ReferenceCountUtil.release(cast) 自动释放;
ReferenceCountUtil.release(cast);
}
if (buf.isReadable()) {
// 向后传递写事件
ctx.write(buf, promise);
} else {
buf.release();
ctx.write(Unpooled.EMPTY_BUFFER, promise);
}
buf = null;
} else {
ctx.write(msg, promise);
}
}
...
}
MessageToMessageEncoder的实现类似。
3. 常用的解码器
3.1. FixedLengthFrameDecoder
固定长度解码器 FixedLengthFrameDecoder直接通过构造函数设置固定长度的大小 frameLength,无论接收方一次获取多大的数据,都会严格按照 frameLength 进行解码。如果累积读取到长度大小为 frameLength 的消息,那么解码器认为已经获取到了一个完整的消息。如果消息长度小于 frameLength,FixedLengthFrameDecoder 解码器会一直等后续数据包的到达,直至获得完整的消息。
channel.pipeline()
.addLast(new FixedLengthFrameDecoder(5))
.addLast("handler", new EchoServerHandler());
3.2. DelimiterBasedFrameDecoder
DelimiterBasedFrameDecoder 有四个构造参数
public DelimiterBasedFrameDecoder(
int maxFrameLength, boolean stripDelimiter, boolean failFast,
ByteBuf delimiter) {
this(maxFrameLength, stripDelimiter, failFast, new ByteBuf[] {
delimiter.slice(delimiter.readerIndex(), delimiter.readableBytes())});
}
- delimiters
delimiters 指定特殊分隔符,通过写入 ByteBuf 作为参数传入。delimiters 的类型是 ByteBuf 数组,所以我们可以同时指定多个分隔符,但是最终会选择长度最短的分隔符进行消息拆分。
例如接收方收到的数据为: 复制代码
+--------------+
| ABC\nDEF\r\n |
+--------------+
如果指定的多个分隔符为 \n 和 \r\n,DelimiterBasedFrameDecoder 会退化成使用 LineBasedFrameDecoder 进行解析,那么会解码出两个消息。 复制代码
+-----+-----+
| ABC | DEF |
+-----+-----+
如果指定的特定分隔符只有 \r\n,那么只会解码出一个消息: 复制代码
+----------+
| ABC\nDEF |
+----------+ - **maxLength**
maxLength 是报文最大长度的限制。如果超过 maxLength 还没有检测到指定分隔符,将会抛出 TooLongFrameException。可以说 maxLength 是对程序在极端情况下的一种保护措施。
- failFast
failFast 与 maxLength 需要搭配使用,通过设置 failFast 可以控制抛出 TooLongFrameException 的时机。如果 failFast=true,那么在超出 maxLength 会立即抛出 TooLongFrameException,不再继续进行解码。如果 failFast=false,那么会等到解码出一个完整的消息后才会抛出 TooLongFrameException。
- stripDelimiter
stripDelimiter 的作用是判断解码后得到的消息是否去除分隔符。如果 stripDelimiter=false,特定分隔符为 \n,那么上述数据包解码出的结果为: 复制代码
+-------+---------+
| ABC\n | DEF\r\n |
+-------+---------+ ``` ByteBuf delimiter = Unpooled.copiedBuffer("&".getBytes()); channel.pipeline()
.addLast(new DelimiterBasedFrameDecoder(10, true, false, delimiter)); ```
3.3. LengthFieldBasedFrameDecoder
长度域解码器 LengthFieldBasedFrameDecoder 是解决 TCP 拆包/粘包问题最常用的解码器。它基本上可以覆盖大部分基于长度拆包场景。
先看LengthFieldBasedFrameDecoder的构造参数
- lengthFieldOffset 长度字段的偏移量,也就是存放长度数据的起始位置
- lengthFieldLength 长度字段所占用的字节数
- lengthAdjustment 消息长度的修正值,在很多较为复杂一些的协议设计中,长度域不仅仅包含消息的长度,而且包含其他的数据,如版本号、数据类型、数据状态等,那么这时候我们需要使用 lengthAdjustment 进行修正,lengthAdjustment = 包体的长度值 - 长度域的值
- initialBytesToStrip 解码后需要跳过的初始字节数,也就是消息内容字段的起始位置
- maxFrameLength 报文最大限制长度
- failFast 是否立即抛出 TooLongFrameException
示例 1:典型的基于消息长度 + 消息内容的解码。
BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
+--------+----------------+ +--------+----------------+
| Length | Actual Content |----->| Length | Actual Content |
| 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+
上述协议是最基本的格式,报文只包含消息长度 Length 和消息内容 Content 字段,其中 Length 为 16 进制表示,共占用 2 字节,Length 的值 0x000C 代表 Content 占用 12 字节。该协议对应的解码器参数组合如下:
- lengthFieldOffset = 0,因为 Length 字段就在报文的开始位置。
- lengthFieldLength = 2,协议设计的固定长度。
- lengthAdjustment = 0,Length 字段只包含消息长度,不需要做任何修正。
- initialBytesToStrip = 0,解码后内容依然是 Length + Content,不需要跳过任何初始字节。
示例 2:解码结果需要截断。
BEFORE DECODE (14 bytes) AFTER DECODE (12 bytes)
+--------+----------------+ +----------------+
| Length | Actual Content |----->| Actual Content |
| 0x000C | "HELLO, WORLD" | | "HELLO, WORLD" |
+--------+----------------+ +----------------+
示例 2 和示例 1 的区别在于解码后的结果只包含消息内容,其他的部分是不变的。该协议对应的解码器参数组合如下:
- lengthFieldOffset = 0,因为 Length 字段就在报文的开始位置。
- lengthFieldLength = 2,协议设计的固定长度。
- lengthAdjustment = 0,Length 字段只包含消息长度,不需要做任何修正。
- initialBytesToStrip = 2,跳过 Length 字段的字节长度,解码后 ByteBuf 中只包含 Content字段。
示例 3:长度字段包含消息长度和消息内容所占的字节。
BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
+--------+----------------+ +--------+----------------+
| Length | Actual Content |----->| Length | Actual Content |
| 0x000E | "HELLO, WORLD" | | 0x000E | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+
与前两个示例不同的是,示例 3 的 Length 字段包含 Length 字段自身的固定长度以及 Content 字段所占用的字节数,Length 的值为 0x000E(2 + 12 = 14 字节),在 Length 字段值(14 字节)的基础上做 lengthAdjustment(-2)的修正,才能得到真实的 Content 字段长度,所以对应的解码器参数组合如下:
- lengthFieldOffset = 0,因为 Length 字段就在报文的开始位置。
- lengthFieldLength = 2,协议设计的固定长度。
- lengthAdjustment = -2,长度字段为 14 字节,需要减 2 才是拆包所需要的长度。
- initialBytesToStrip = 0,解码后内容依然是 Length + Content,不需要跳过任何初始字节。
示例 4:基于长度字段偏移的解码。
BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes)
+----------+----------+----------------+ +----------+----------+----------------+
| Header 1 | Length | Actual Content |----->| Header 1 | Length | Actual Content |
| 0xCAFE | 0x00000C | "HELLO, WORLD" | | 0xCAFE | 0x00000C | "HELLO, WORLD" |
+----------+----------+----------------+ +----------+----------+----------------+
示例 4 中 Length 字段不再是报文的起始位置,Length 字段的值为 0x00000C,表示 Content 字段占用 12 字节,该协议对应的解码器参数组合如下:
- lengthFieldOffset = 2,需要跳过 Header 1 所占用的 2 字节,才是 Length 的起始位置。
- lengthFieldLength = 3,协议设计的固定长度。
- lengthAdjustment = 0,Length 字段只包含消息长度,不需要做任何修正。
- initialBytesToStrip = 0,解码后内容依然是完整的报文,不需要跳过任何初始字节。
示例 5:长度字段与内容字段不再相邻。
BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes)
+----------+----------+----------------+ +----------+----------+----------------+
| Length | Header 1 | Actual Content |----->| Length | Header 1 | Actual Content |
| 0x00000C | 0xCAFE | "HELLO, WORLD" | | 0x00000C | 0xCAFE | "HELLO, WORLD" |
+----------+----------+----------------+ +----------+----------+----------------+
示例 5 中的 Length 字段之后是 Header 1,Length 与 Content 字段不再相邻。Length 字段所表示的内容略过了 Header 1 字段,所以也需要通过 lengthAdjustment 修正才能得到 Header + Content 的内容。示例 5 所对应的解码器参数组合如下:
- lengthFieldOffset = 0,因为 Length 字段就在报文的开始位置。
- lengthFieldLength = 3,协议设计的固定长度。
- lengthAdjustment = 2,由于 Header + Content 一共占用 2 + 12 = 14 字节,所以 Length 字段值(12 字节)加上 lengthAdjustment(2 字节)才能得到 Header + Content 的内容(14 字节)。
- initialBytesToStrip = 0,解码后内容依然是完整的报文,不需要跳过任何初始字节。
示例 6:基于长度偏移和长度修正的解码。
BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
+------+--------+------+----------------+ +------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xCA | 0x000C | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+------+--------+------+----------------+ +------+----------------+
示例 6 中 Length 字段前后分为别 HDR1 和 HDR2 字段,各占用 1 字节,所以既需要做长度字段的偏移,也需要做 lengthAdjustment 修正,具体修正的过程与 示例 5 类似。对应的解码器参数组合如下:
- lengthFieldOffset = 1,需要跳过 HDR1 所占用的 1 字节,才是 Length 的起始位置。
- lengthFieldLength = 2,协议设计的固定长度。
- lengthAdjustment = 1,由于 HDR2 + Content 一共占用 1 + 12 = 13 字节,所以 Length 字段值(12 字节)加上 lengthAdjustment(1)才能得到 HDR2 + Content 的内容(13 字节)。
- initialBytesToStrip = 3,解码后跳过 HDR1 和 Length 字段,共占用 3 字节。
示例 7:长度字段包含除 Content 外的多个其他字段。
BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
+------+--------+------+----------------+ +------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xCA | 0x0010 | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+------+--------+------+----------------+ +------+----------------+
示例 7 与 示例 6 的区别在于 Length 字段记录了整个报文的长度,包含 Length 自身所占字节、HDR1 、HDR2 以及 Content 字段的长度,解码器需要知道如何进行 lengthAdjustment 调整,才能得到 HDR2 和 Content 的内容。所以我们可以采用如下的解码器参数组合:
- lengthFieldOffset = 1,需要跳过 HDR1 所占用的 1 字节,才是 Length 的起始位置。
- lengthFieldLength = 2,协议设计的固定长度。
- lengthAdjustment = -3,Length 字段值(16 字节)需要减去 HDR1(1 字节) 和 Length 自身所占字节长度(2 字节)才能得到 HDR2 和 Content 的内容(1 + 12 = 13 字节)。
- initialBytesToStrip = 3,解码后跳过 HDR1 和 Length 字段,共占用 3 字节。
4. Protobuf编解码
server
channel.pipeline()
// 解码器,通过Google Protocol Buffers序列化框架动态的切割接收到的ByteBuf
.addLast(new ProtobufVarint32FrameDecoder())
// 服务器端接收的是客户端对象,所以这边将接收对象进行解码生产实列
.addLast(new ProtobufDecoder(HelloRequest.getDefaultInstance()))
//Google Protocol Buffers编码器
.addLast(new ProtobufVarint32LengthFieldPrepender())
.addLast(new ProtobufEncoder())
.addLast("handler", new ProtoServerHandler());
client
channel.pipeline()
.addLast(new ProtobufVarint32FrameDecoder())
.addLast(new ProtobufDecoder(HelloReply.getDefaultInstance()))
.addLast(new ProtobufVarint32LengthFieldPrepender())
.addLast(new ProtobufEncoder())
.addLast(new ProtoClientHandler());
5. 自定义协议
+---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 消息 ID 8byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
编码
public class RpcMessageEncoder extends MessageToByteEncoder<RpcMessage> {
@Override
protected void encode(ChannelHandlerContext ctx, RpcMessage msg, ByteBuf out) throws Exception {
MessageHeader header = msg.getHeader();
out.writeShort(header.getMagicNumber());
out.writeByte(header.getVersion());
out.writeByte(header.getSerialization());
out.writeByte(header.getMessageType());
out.writeByte(header.getStatus());
out.writeLong(header.getRequestId());
byte[] bytes = msg.getBody().getBytes();
out.writeInt(msg.getBody().getBytes().length);
out.writeBytes(bytes);
}
}
channel.pipeline().addLast(new RpcMessageEncoder());
channel.pipeline().addLast(new RpcClientHandler());
解码
public class RpcMessgeDecoder extends MessageToMessageDecoder<ByteBuf> {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws Exception {
MessageHeader messageHeader = new MessageHeader();
// 2byte魔数
messageHeader.setMagicNumber(msg.readShort());
// 1byte协议版本号
messageHeader.setVersion(msg.readByte());
// 1byte序列化算法
messageHeader.setSerialization(msg.readByte());
// 1byte 报文类型
messageHeader.setMessageType(msg.readByte());
// 1byte 状态
messageHeader.setStatus(msg.readByte());
// 8byte 请求ID
messageHeader.setRequestId(msg.readLong());
// 4byte 数据长度
messageHeader.setLength(msg.readInt());
RpcMessage rpcMessage = new RpcMessage();
rpcMessage.setHeader(messageHeader);
byte[] bytes = new byte[msg.readableBytes()];
msg.readBytes(bytes);
rpcMessage.setBody(new String(bytes));
out.add(rpcMessage);
}
}
channel.pipeline()
// length跳过的长度 14:2byte魔数 + 1byte协议版本号 + 1byte序列化算法 + 1byte报文类型 + 1byte状态 + 8byte消息ID
// maxFrameLength 1024(目前是随便定义的一个值)
// lengthFieldOffset 16
// lengthFieldLength 4
// lengthAdjustment 0,length字段仅是body的长度,且长度和body相邻
// initialBytesToStrip 0,不跳过任何字节
.addLast(new RpcMessgeDecoder())
.addLast(new LengthFieldBasedFrameDecoder(1024, 14, 4))
.addLast(new RpcServerHandler())
