基本复制自https://mp.weixin.qq.com/s/cPi9bJ8qQRWt6Nuw8zWXVQ
1. Prometheus
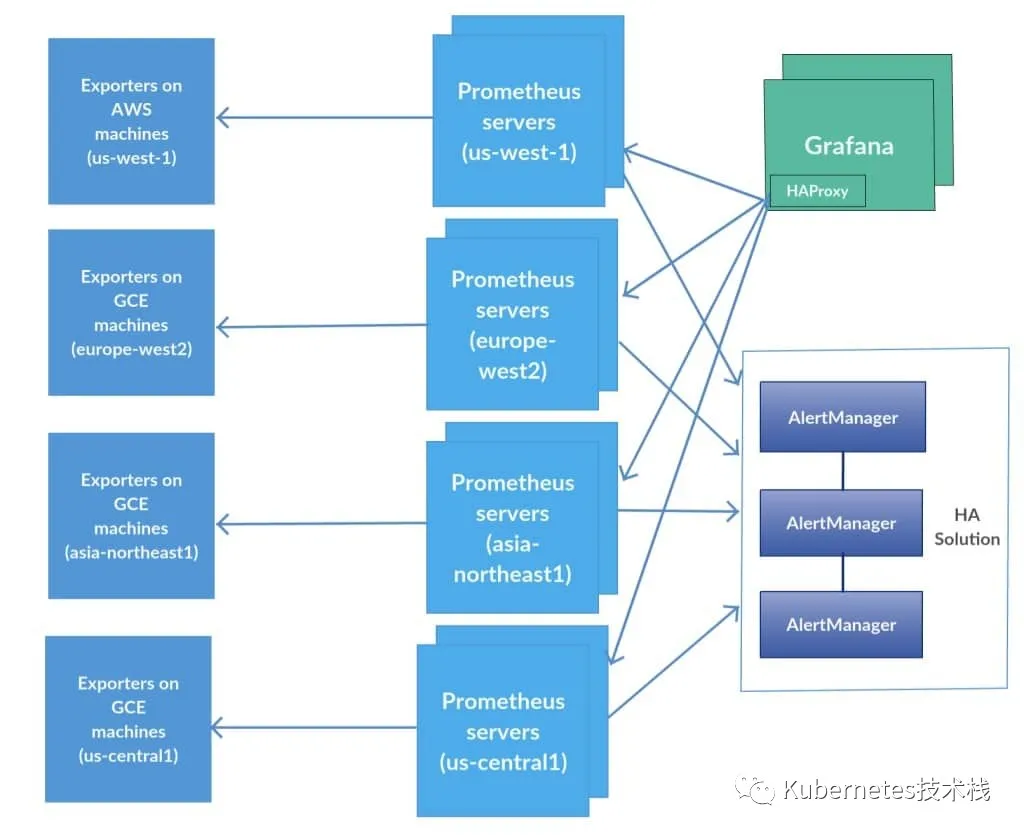
为了提升Prometheus的服务可靠性,我们会部署两个或多个的Prometheus服务,两个Prometheus具有相同的配置(Job配、告警规则、等),当其中一个Down掉了以后,可以保证Prometheus持续可用。
这种方式(基本的HA模式)只能确保Promethues服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题和持久化问题(数据丢失后无法恢复),也无法进行动态扩展。因此这种部署方式适合监控规模不大,Prometheus Server也不会发现频繁迁移的情况,并且只需要保存短周期监控数据的场景。
在基本HA模式的基层上,我们可以通过增加Remote Storate存储支持,将监控数据保存在第三方存储服务上。在解决了Prometheus服务可用性的基础上,同时确保了数据的持久化,当Prometheus Server发生宕机或数据丢失的情况下,可以快速的恢复。同时Prometheus Server可以很好的进行迁移。因此此方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能确保Prometheus Server的可迁移场景。
当单台Prometheus无法处理大量的采集任务时,可以考虑基于Prometheus集群的方式将监控采集任务划分到不同的Prometheus实例中。
2. AlertManager
AlertManager自带警报分组机制,即使不同的Prometheus分别发送相同的警报给Alertmanager,Alertmanager也会自动把这些警报合并处理。
虽然Alertmanager 能够同时处理多个相同的Prometheus的产生的警报,如果部署的Alertmanager是单节点,那就存在明显的的单点故障风险,当Alertmanager节点down机以后,警报功能则不可用。
解决这个问题的方法就是使用传统的HA架构模式,部署Alertmanager多节点。但是由于Alertmanager之间关联存在不能满足HA的需求,因此会导致警报通知被Alertmanager重复发送多次的问题。
Alertmanager为了解决这个问题,引入了Gossip机制,为多个Alertmanager之间提供信息传递机制。确保及时的在多个Alertmanager分别接受到相同的警报信息的情况下,不会发送重复的警报信息给Receiver.
下面一图很详细的阐述了一次警报通知的整个流程:
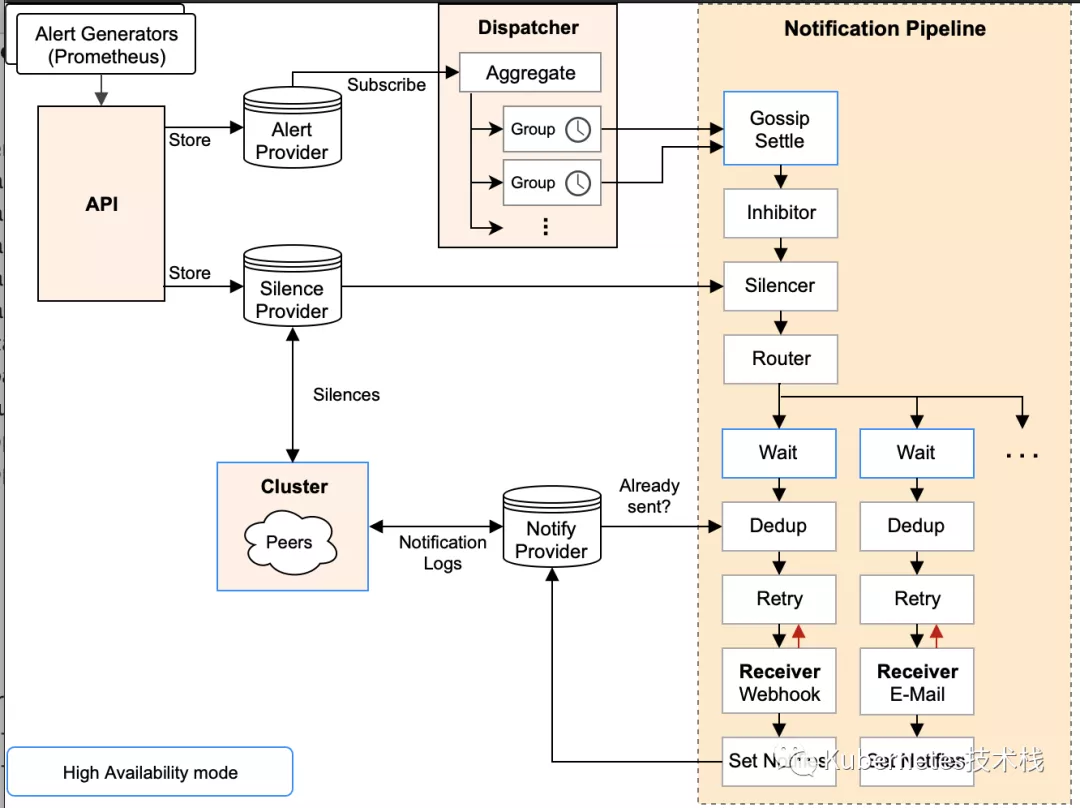
- Silence 在这个阶段中Alertmanager会判断当前通知是否匹配任何静默规则;如果没有则进入下一个阶段,否则会中断流程不发送通知。
- Wait Alertmanager 会根据当前集群中所处在的顺序[index],等待 index * 5s 的时间。
- Dedup 当等待结束完成,进入 Dedup 阶段,这时会判断当前Alertmanager TSDB中警报是否已经发送,如果发送则中断流程,不发送警报。
- Send 如果上面的未发送,则进入 Send 阶段,发送警报通知。
- Gossip 警报发送成功以后,进入最后一个阶段 Gossip ,通知其他Alertmanager节点,当前警报已经发送成功。其他Alertmanager节点会保存当前已经发送过的警报记录。
Gossip两个个关键:
- Alertmanager 节点之间的Silence设置相同,这样确保了设置为静默的警报都不会对外发送
- Alertmanager 节点之间通过Gossip机制同步警报通知状态,并且在流程中标记Wait阶段,保证警报是依次被集群中的Alertmanager节点读取并处理。
集群参数
- –cluster.listen-address=”0.0.0.0:9094” 集群服务监听端口
- –cluster.peer 初始化关联其他节点的监听地址
- –cluster.advertise-address 广播地址,其他某个节点的地址
- –cluster.gossip-interval 集群消息传播时间,默认 200s
- –cluster.probe-interval 各个节点的探测时间间隔
示例
alertmanager --config.file=/usr/local/alertmanager01/conf/alertmanager.yml --storage.path=/usr/local/alertmanager01/data --web.listen-address=":19093" --cluster.listen-address=192.168.1.220:19094
Prometheus中的配置:
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.1.220:19093','192.168.1.220:29093','192.168.1.220:39093']
3. Grafana
Grafana的高可用主要通过这两项类保证:
- 部署多个grafana实例,改访问sqlite3为共享数据库
- 处理session问题
数据库
Grafana默认使用了内嵌数据库sqlite3来进行用户以及dashboard相关配置的存储,更改配置文件的[database]部分,改为mysql。
[database]
# You can configure the database connection by specifying type, host, name, user and password
# as separate properties or as on string using the url property.
# Either "mysql", "postgres" or "sqlite3", it's your choice
type = sqlite3
host = 127.0.0.1:3306
name = grafana
user = root
然后通过nginx配置反向代理
