基本复制自https://mp.weixin.qq.com/s/psA6KgHQfCIZ-q9J6IVrLg
1. 配置
Prometheus把产生的警报发给Alertmanager进行处理时,需要在Prometheus使用的配置文件中添加关联Alertmanager的组件的对应配置信息。
alerting:
alert_relabel_configs:
[ - <relabel_config> ... ]
alertmanagers:
[ - <alertmanager_config> ... ]
# alertmanagers 为 alertmanager_config 数组,
示例
# Alertmanager configuration
alerting:
alert_relabel_configs: # 动态修改 alert 属性的规则配置。
- source_labels: [dc]
regex: (.+)\d+
target_label: dc1
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
#- targets: ['192.168.159.131:9093','192.168.159.131:9093','192.168.159.131:9093'] # 集群配置
scrape_configs:
- job_name: 'Alertmanager'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9093']
上面的配置中的 alert_relabel_configs是指警报重新标记在发送到Alertmanager之前应用于警报。它具有与目标重新标记相同的配置格式和操作,外部标签标记后应用警报重新标记,主要是针对集群配置。这个设置的用途是确保具有不同外部label的HA对Prometheus服务端发送相同的警报信息。
Alertmanager 可以通过 static_configs 参数静态配置,也可以使用其中一种支持的服务发现机制动态发现,
完成以上配置后,重启Prometheus服务,用以加载生效,也可以使用前文说过的热加载功能,使其配置生效。然后通过浏览器,访问 http://localhost:9090/alerts 就可以看 inactive pending firing 三个状态,没有警报信息是因为我们还没有配置警报规则 rules。
2. 警报规则
警报规则 rules 使用的是 yaml 格式进行定义,在Prometheus中通过我们前面讲过的 PromQL 配置实际警报触发条件,Prometheus 会根据设置的警告规则 Rules 以及配置间隔时间进行周期性计算,当满足触发条件规则会发送警报通知。
警报规则加载的是在 prometheus.yml 文件中进行配置,默认的警报规则进行周期运行计算的时间是1分钟,可以使用 global 中的 evaluation_interval 来决定时间间隔。
global:
evaluation_interval: 15s
警报规则可以指定多个文件,也可以自定到自定义的目录下面,为了管理更为便捷,方便阅读,可以把警报规则拆成多份,用以区分环境,系统,服务等,如:prod,test,dev 等等,并且支持以正则表达式定义。
rule_files:
#- "/data/prometheus/rules/*.yml" # 正则表达式,会加在此目录下所有警报规则配置文件
- "/data/prometheus/rules/ops.yml" # 仅加载ops.yml警报规则文件
#- "/data/prometheus/rules/prod-*.yml"
#- "/data/prometheus/rules/test-*.yml"
#- "/data/prometheus/rules/dev-*.yml"
警报规则 Rules 的定义格式为YAML。
groups:
- name: <string>
rules:
- alert: <string>
expr: <string>
for: [ <duration> | default 0 ]
labels:
[ <lable_name>: <label_value> ]
annotations:
[ <lable_name>: <tmpl_string> ]
| 参数 | 描述 |
|---|---|
- name: <string> |
警报规则组的名称 |
- alert: <string> |
警报规则的名称 |
expr: <string |
使用PromQL表达式完成的警报触发条件,用于计算是否有满足触发条件 |
<lable_name>: <label_value> |
自定义标签,允许自行定义标签附加在警报上,比如high warning |
annotations: <lable_name>: <tmpl_string> |
用来设置有关警报的一组描述信息,其中包括自定义的标签,以及expr计算后的值。 |
示例
groups:
- name: operations
rules:
- alert: node-down
expr: up{env="test"} != 1
for: 5m
labels:
status: High
team: operations
annotations:
description: "Environment: Instance: is Down ! ! !"
value: ''
summary: "The host node was down 20 minutes ago"
以上就是一个完整 Rules 的配置,如果Prometheus 在周期检测中使用PromQ以env=operations为维度查询,如果当前查询结果中具有标签operations,且返回值都不等于1的时候,发送警报。对于写好的 Rules 可以是常用 promtool 来check ruls.yml 的书写格式是否正确。
promtool check rules /server/data/prometheus/rules/ops.yml
Checking /server/data/prometheus/rules/ops.yml
SUCCESS: 1 rules found
对于修改好的rules文件,保存以后,经过检测没有问题,直接重新热加载 Prometheus就可以在页面看到了。
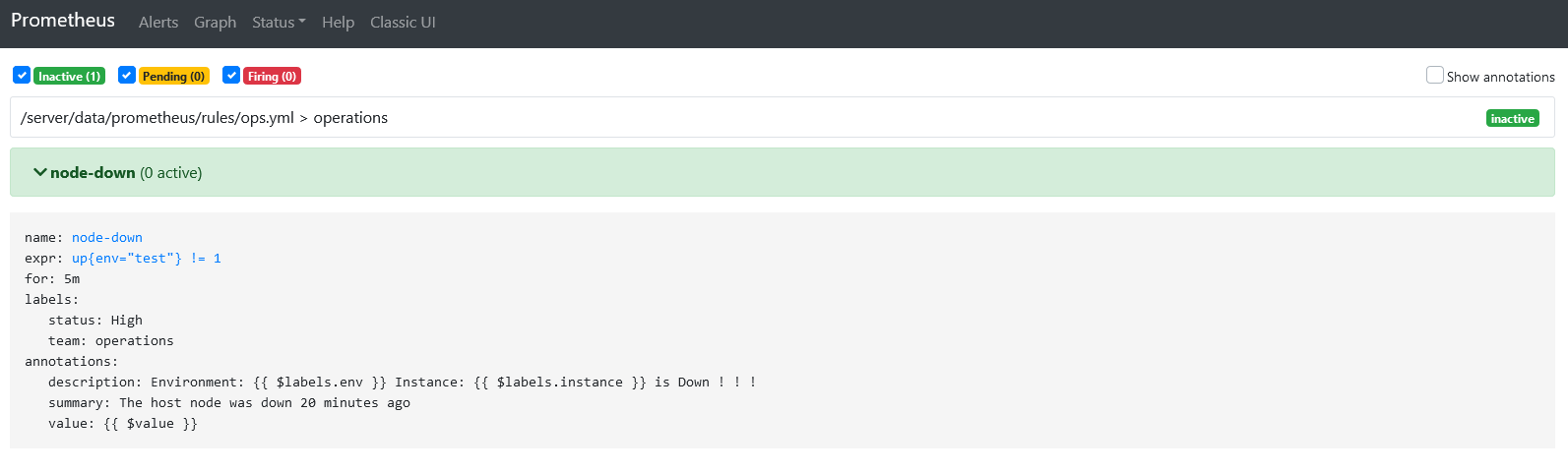
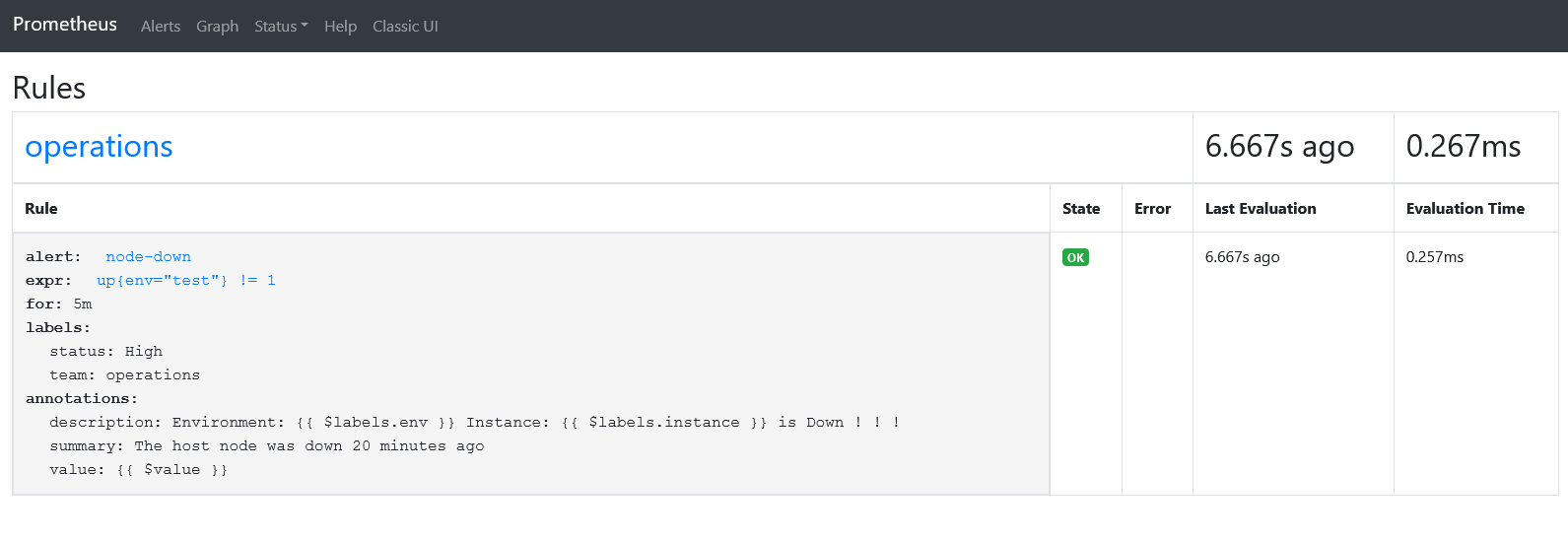
对于触发警报规则,比较简单了,直接修改运算值或者去停掉 node-exporter 服务,便可在界面看到警报信息。
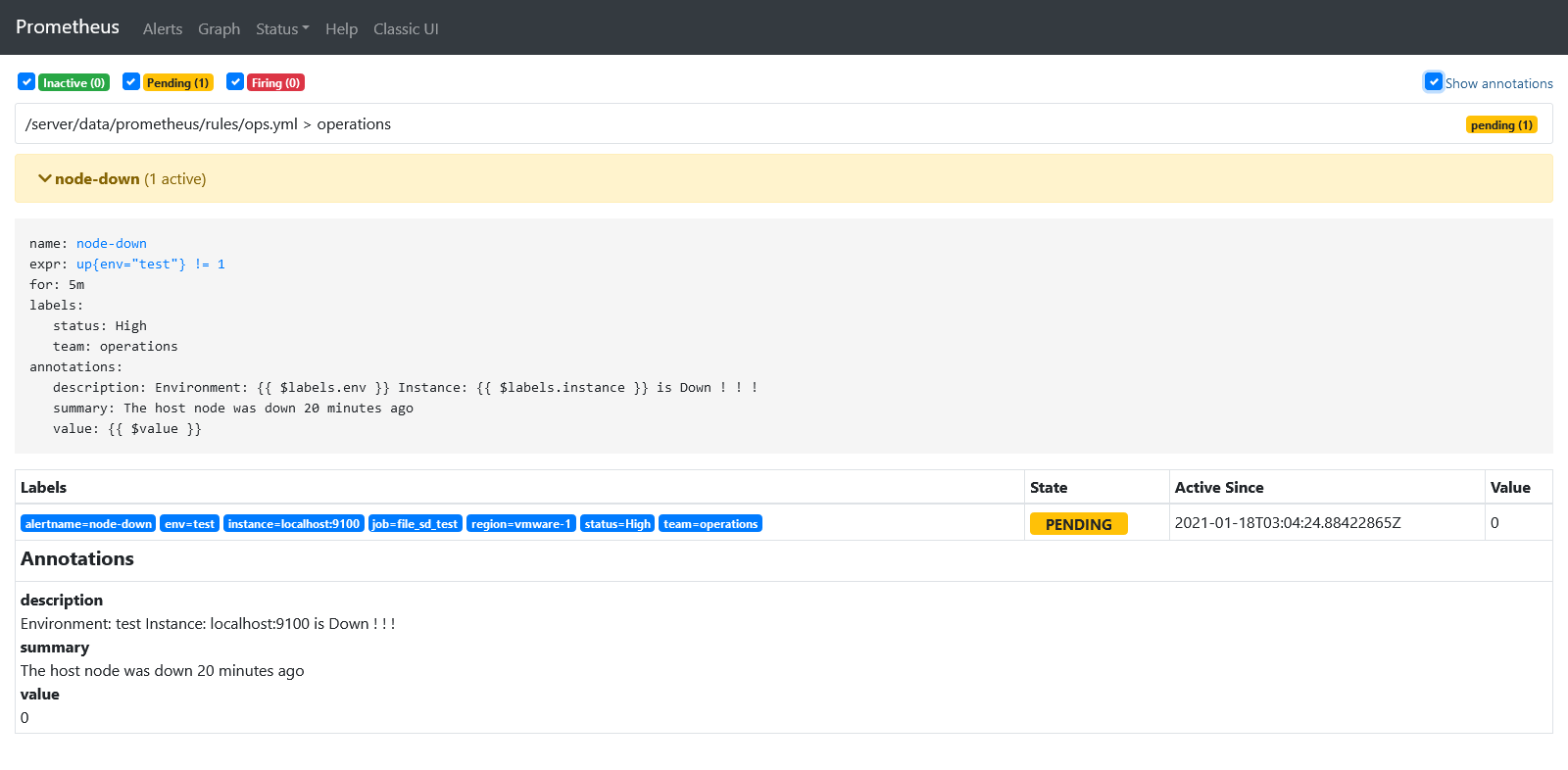
一个警报在生命周期会有三种状态
- Inactive 正常状态,未激活警报
- Pending 已满足触发条件,但没有满足发送时间条件,此条件就是上面rules范例中的 for 5m 子句中定义的持续时间
- Firing 满足条件,且超过了 for 子句中的的指定持续时间5m
带有for子句的警报触发以后首先会先转换成 Pending 状态,然后在转换为 Firing 状态。这里需要俩个周期才能触发警报条件,如果没有设置 for 子句,会直接从 Inactive 状态转换成 Firing状态,然后触发警报,发送给 Receiver 设置的通知人。
在运行过程中,Prometheus会把Pending或Firing状态的每一个警报创建一个 Alerts指标名称,这个可以通过Rules来触发警报测试,直接在UI中Graph查看指标 ALERTS,格式如下:
ALERTS{alertname="alert name",alertstate="pending|firing",<additional alert label>}
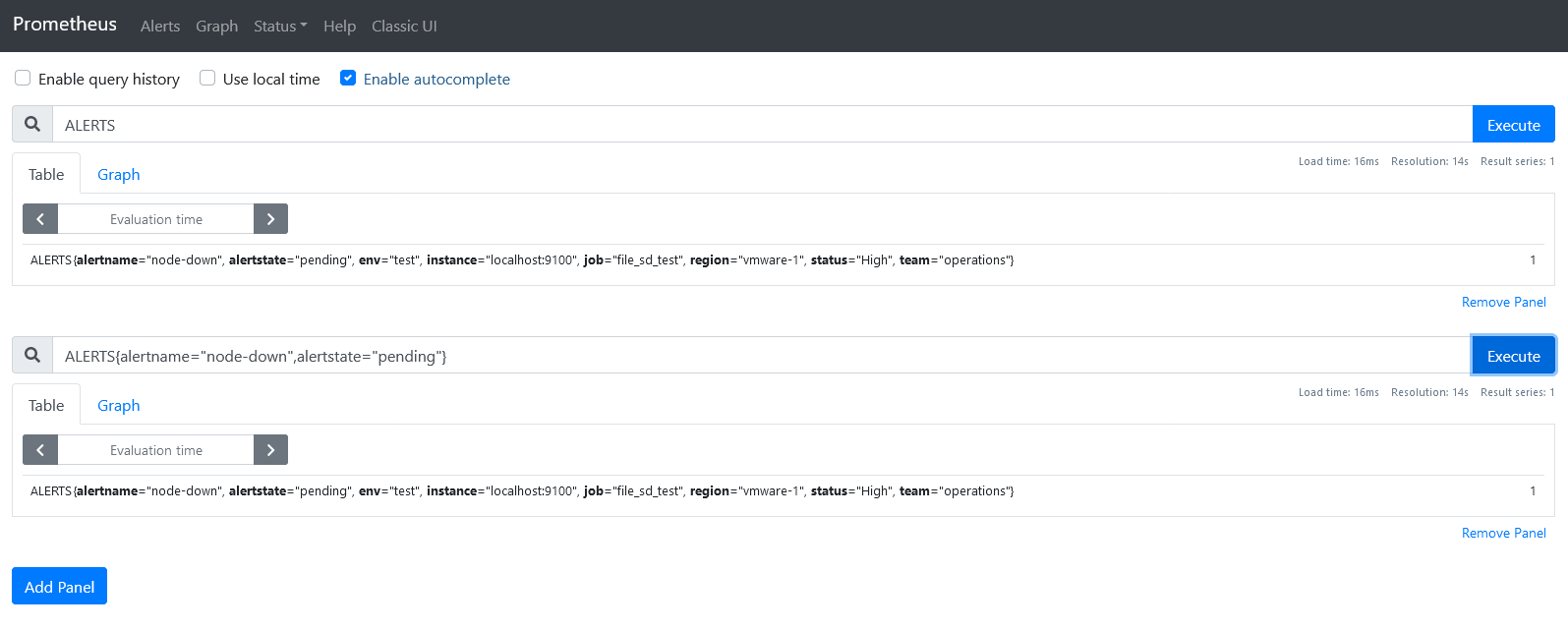
当警报处于激活状态 Firing的时候,可以在浏览器上访问Alertmanager,查看警报状态。
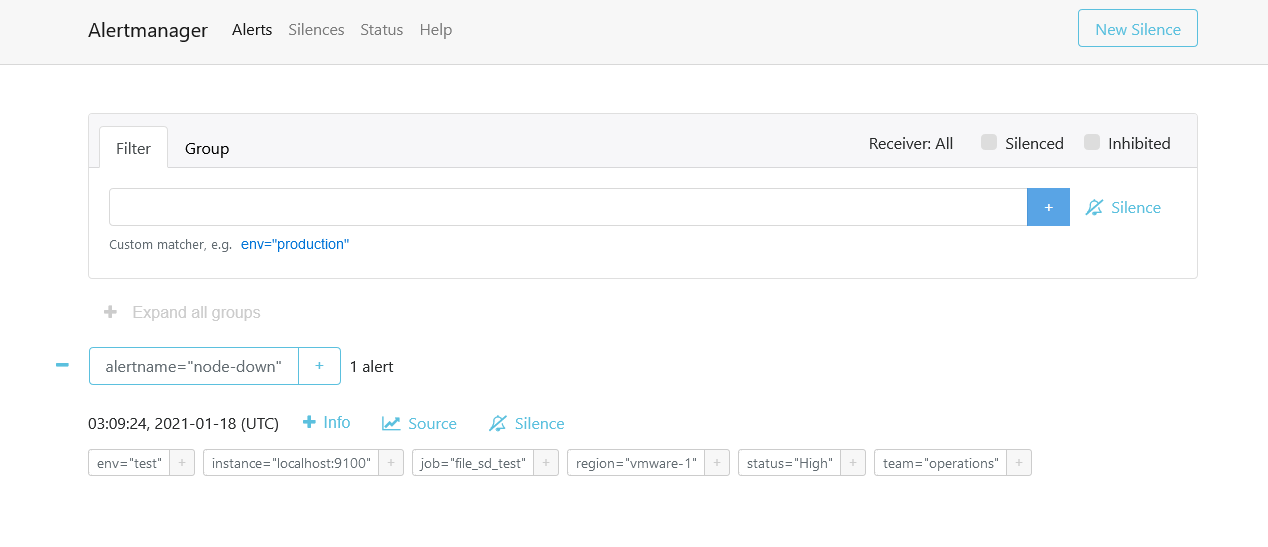
现在我们来说一下整理下Prometheus从收集监控指标信息到触发警报的过程
- 定义规则:在Prometheus配置中,scrape_interval: 15s,默认是1分钟,这个定义是收集监控指标信息的采集周期,同时配置对应的警报规则,可以是全局,也可以单独为某一个metrics定义
- 周期计算:对于表达式进行计算时,Prometheus中的配置中配置了 evaluation_interval: 15s,默认也是一分钟,为警报规则的计算周期,evaluation_interval 只是全局计算周期值。
- 警报状态转换(pending):当首次触发警报规则条件成立,表达式为 true,并且没有满足警报规则中的for子句中的持续时间时,警报状态切换为 Pending
- 警报状态转换(firing):若下一个计算周期中,表达式仍为 true,并且满足警报规则中的for子句的持续时间时,警报状态转换为 Firing,即为 active,警报会被Prometheus推送到ALertmanager组件
- 警报状态转换(period): 如果在 evaluation_interval 的计算周期内,表达式还是为 true,同时满足 for子句的持续时间,持续转发到Alertmanager,这里只是转发状态到Alertmanager,并不是直接发送通知到指定通知源
- 警报状态转换(resolve): 只到某个周期,表达式 为 false,警报状态会变成 inactive ,并且会有一个 resolve被发送到Alertmanager,用于说明警报故障依解决,发送resolve信息需要自己单独在Alertmanager中定义
3. Rules类型
Prometheus 支持两种类型的 Rules ,可以对其进行配置,然后定期进行运算:recording rules 记录规则 与 alerting rules 警报规则,规则文件的计算频率与警报规则计算频率一致,都是通过全局配置中的 evaluation_interval 定义。
3.1. alerting rules
要在Prometheus中使用Rules规则,就必须创建一个包含必要规则语句的文件,并让Prometheus通过Prometheus配置中的rule_files字段加载该文件,除了 recording rules 中的收集的指标名称 record: <string> 字段配置方式略有不同,其他都是一样的。
示例
- alert: ServiceDown
expr: avg_over_time(up[5m]) * 100 < 50
annotations:
description: The service instance is
not responding for more than 50% of the time for 5 minutes.
summary: The service is not responding
- alert: RedisDown
expr: avg_over_time(redis_up[5m]) * 100 < 50
annotations:
description: The Redis service instance is not responding for more than 50% of the time for 5 minutes.
summary: The Redis service is not responding
3.2. recording rules
recording rules 是提前设置好一个比较花费大量时间运算或经常运算的表达式,其结果保存成一组新的时间序列数据。当需要查询的时候直接会返回已经计算好的结果,这样会比直接查询快,也减轻了PromQl的计算压力,同时对可视化查询的时候也很有用,可视化展示每次只需要刷新重复查询相同的表达式即可。
在配置的时候,除却 record: <string> 需要注意,其他的基本上是一样的,一个 groups 下可以包含多条规则 rules ,Recording 和 Rules 保存在 groups 内,Groups 中的规则以规则的配置时间间隔顺序运算,也就是全局中的 evaluation_interval 设置。
示例
groups:
- name: http_requests_total
rules:
- record: job:http_requests_total:rate10m
expr: sum by (job)(rate(http_requests_total[10m]))
lables:
team: operations
- record: job:http_requests_total:rate30m
expr: sum by (job)(rate(http_requests_total[30m]))
lables:
team: operations
上面的规则其实就是根据 record 规则中的定义,Prometheus 会在后台完成 expr 中定义的 PromQL 表达式周期性运算,以 job 为维度使用 sum 聚合运算符 计算 函数rate 对http_requests_total 指标区间 10m 内的增长率,并且将计算结果保存到新的时间序列 job:http_requests_total:rate10m 中, 同时还可以通过 labels 为样本数据添加额外的自定义标签,但是要注意的是这个 Lables 一定存在当前表达式 Metrics 中。
4. 模板
模板是在警报中使用时间序列标签和值展示的一种方法,可以用于警报规则中的注释(annotation)与标签(lable)。模板其实使用的go语言的标准模板语法,并公开一些包含时间序列标签和值的变量。这样查询的时候,更具有可读性,也可以执行其他PromQL查询 来向警报添加额外内容,ALertmanager Web UI中会根据标签值显示器警报信息。
- `` 可以获取当前警报实例中的指定标签值
- `` 变量可以获取当前PromQL表达式的计算样本值。
groups:
- name: operations
rules:
# monitor node memory usage
- alert: node-memory-usage
expr: (1 - (node_memory_MemAvailable_bytes{env="operations",job!='atlassian'} / (node_memory_MemTotal_bytes{env="operations"})))* 100 > 90
for: 1m
labels:
status: Warning
team: operations
annotations:
description: "Environment: Instance: memory usage above ! ! !"
summary: "node os memory usage status"
调整好rules以后,我们可以使用 curl -X POST http://localhost:9090/-/reload 或者 对Prometheus服务重启,让警报规则生效。
需要注意的是,一个稳定健壮的Prometheus监控系统中,要尽量使用模板化,这样会降低性能开销(Debug调试信息等),同时也易于维护。
下面网站收录了当前大部分的rules规则,大家可以对应自己的环境,配置相关服务的Rules。
[Prometheus警报规则收集(https://awesome-prometheus-alerts.grep.to/)
