Protocol Buffers是Google开发一种数据描述语言,能够将结构化数据序列化,可用于数据存储、通信协议等方面。
可以把它理解为更快、更简单、更小的JSON或者XML,区别在于Protocol Buffers是二进制格式,而JSON和XML是文本格式
可以定义数据的结构化,然后可以使用特殊生成的源代码轻松地在各种数据流中使用各种语言编写和读取结构化数据。
相对于XML、JSON,Protocol Buffers的具有如下几个优点:
- 简洁
- 体积小:消息大小只需要XML的1/10 ~ 1/3
- 速度快:解析速度比XML快20 ~ 100倍
- 使用Protocol Buffers的编译器,可以生成更容易在编程中使用的数据访问代码
- 更好的兼容性,Protocol Buffers设计的一个原则就是要能够很好的支持向下或向上兼容。
对于下面的数据,用JSON需要103bytes,而Protocol Buffers只需要50bytes。
{"id":9223372036854775807,"username":"edgar","mobile":"13412345678","mail":"edgar@github.com","age":30}
1. 定义消息
在消息定义中,我们需要确定三个问题:
- 确定消息命名,给消息取一个有意义的名字。
- 指定字段的类型
- 定义字段的编号,在Protocol Buffers中,字段的编号非常重要,字段名仅仅是作为参考和生成代码用。需要注意的是字段的编号区间范围,其中19000 ~ 19999被Protocol Buffers作为保留字段。
假设你想定义一个“搜索请求”的消息格式,每一个请求含有一个查询字符串、你感兴趣的查询结果所在的页数,以及每一页多少条查询结果。可以采用如下的方式来定义消息类型的.proto文件了
syntax = "proto3";
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
syntax = "proto3";指定了正在使用proto3语法:如果您不这样做,protobuf 编译器将假定您正在使用proto2。这必须是文件的第一个非空的非注释行。- 所述
SearchRequest消息定义指定了三个字段(名称/值对),一个用于要在此类型的消息中包含的每个数据片段。每个字段都有一个名称和类型。
在上面的示例中,所有字段都是标量类型:两个整数(page_number和result_per_page)和一个字符串(query)。但是,您还可以为字段指定合成类型,包括枚举和其他消息类型。
在消息定义中,每个字段都有唯一的一个数字标识符。这些标识符是用来在消息的二进制格式中识别各个字段的,一旦开始使用就不能够再改变。
[1,15]之内的标识号在编码的时候会占用一个字节。[16,2047]之内的标识号则占用2个字节。所以应该为那些频繁出现的消息元素保留 [1,15]之内的标识号。切记:要为将来有可能添加的、频繁出现的标识号预留一些标识号。
最小的标识号可以从1开始,最大到2^29 - 1, or 536,870,911。不可以使用其中的[19000-19999]的标识号, Protobuf协议实现中对这些进行了预留。如果非要在.proto文件中使用这些预留标识号,编译时就会报警。
1.1. 字段规则
消息字段可以是以下之一:
- 单数:格式良好的消息可以包含该字段中的零个或一个(但不超过一个)。
repeated:此字段可以在格式良好的消息中重复任意次数(包括零)。将保留重复值的顺序。
在proto3中,repeated数字类型的字段默认使用packed编码。
1.2. 字段约束
消息字段的约束有两种
required:指定该字段必须赋值,禁止为空(在v3中该约束被移除);optional:指定字段为可选字段,可以为空,对于optional字段还可以使用[default]指定默认值,如果没有指定,则会使用字段类型的默认值;
解析消息时,如果编码消息不包含特定的单数元素,则解析对象中的相应字段将设置为该字段的默认值。这些默认值是特定于类型的:
- 对于字符串,默认值为空字符串
- 对于字节,默认值为空字节
- 对于bools,默认值为false
- 对于数字类型,默认值为零
- 对于枚举,默认值是第一个定义的枚举值,该值必须为0
- 对于消息字段,未设置该字段。它的确切值取决于语言
重复字段的默认值为空(通常是相应语言的空列表)。
请注意,对于标量消息字段,一旦解析了消息,就无法确定字段是否显式设置为默认值(例如,是否设置了布尔值false)或者根本没有设置:您应该记住这一点在定义消息类型时。例如,false如果您不希望默认情况下也发生这种行为,那么在设置为时,没有一个布尔值可以启用某些行为。还要注意的是,如果一个标消息字段被设置为默认值,在转换成字节数组时会忽略该字段。
1.3. 多message
在一个proto文件中可以同时定义多个message类型,生成代码时根据生成代码的目标语言不同,处理的方式不太一样,如Java会针对每个message类型生成一个.java文件。还可以使用C++风格的注释。
/*
这是一段注释
这是一段注释
*/
// The request message containing the user's name.
message HelloRequest {
string name = 1;
}
// The response message containing the greetings
message HelloReply {
string message = 1;
}
1.4. 保留字段
如果通过完全删除字段或将其注释来更新消息类型,则未来用户可以在对类型进行自己的更新时重用字段编号。如果以后加载相同的旧版本,这可能会导致严重问题.proto,包括数据损坏,隐私错误等。确保不会发生这种情况的一种方法是指定已删除字段的字段编号(和/或名称,这也可能导致JSON序列化问题)reserved。如果将来的任何用户尝试使用这些字段标识符,编译器将会警告。
message Foo {
uint64 id = 1;
string username = 2;
string mobile = 3;
string mail = 4;
uint32 age = 5;
reserved 2, 15, 9 to 11;
reserved "age", "bar";
}
上述的代码在编译时会提示错误
Field "username" uses reserved number 2.
Field name "age" is reserved.
我们需要删除保留字段
message Foo {
uint64 id = 1;
string mobile = 3;
string mail = 4;
reserved 2, 15, 9 to 11;
reserved "age", "bar";
}
1.5. 标量类型
在Protocol Buffers中提供了很多的标量类型,供我们在定义字段类型时使用。
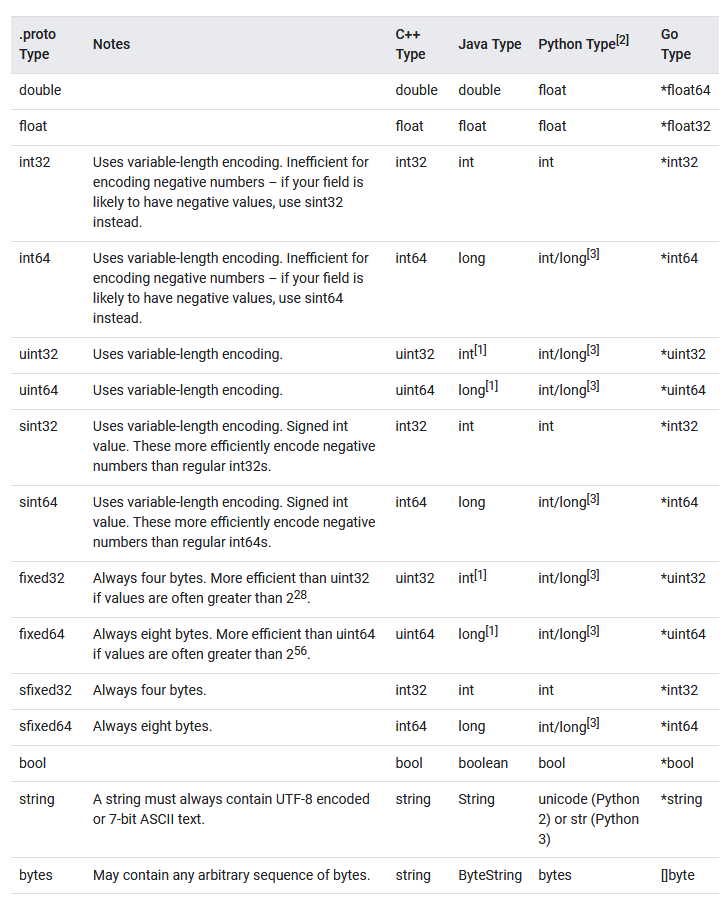
可以指定字段的类型为其他message类型
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
message SearchRespose {
repeated Result result = 1;
}
message Result {
string name = 1;
}
还可以使用import关键字导入其他proto文件,这有利于你进行自己的proto文件的规划和整理。
import "hello.proto";
message SearchRespose {
repeated User user = 1;
}
默认情况下,您只能使用直接导入.proto文件中的定义。但是,有时您可能需要将.proto文件移动到新位置。.proto现在,您可以.proto在旧位置放置一个虚拟文件,以使用该import public概念将所有导入转发到新位置,而不是直接移动文件并在一次更改中更新所有调用站点。import public任何导入包含该import public语句的proto的人都可以传递依赖关系。
// new.proto
// All definitions are moved here
// old.proto
//This is the proto that all clients are importing.
import public“new.proto”;
import“other.proto”;
// client.proto
import "old.proto";
//可以使用old.proto和new.proto中的定义,但不使用other.proto
在proto文件中消息的类型还可以嵌套,如你定义的message类型仅作为另外一个Message的字段类型。
message SearchRespose {
message Result {
string name = 1;
}
repeated Result result = 1;
}
1.6. oneof
oneof关键字指定一组字段中,至少要有一个字段必须赋值。如在用户登录系统中,使用邮箱和用户名都可以登录该系统,所以通常会要求至少提供用户名或者邮箱。
message SampleMessage {
oneof test_oneof {
string name = 4;
SubMessage sub_message = 9;
}
}
oneof需要注意的地方
- 设置oneof字段将自动清除oneof的所有其他成员。因此,如果您设置了多个字段,则只有您设置的最后一个字段仍然具有值
- 如果解析器在解析时遇到同一个oneof的多个成员,则在解析的消息中仅使用看到的最后一个成员。
- 不能使用
repeated字段。
1.7 枚举
在定义消息类型时,您可能希望其中一个字段只有一个预定义的值列表。例如,假设你想添加一个 corpus字段每个SearchRequest,其中语料库可以 UNIVERSAL,WEB,IMAGES,LOCAL,NEWS,PRODUCTS或VIDEO。您可以非常简单地通过enum为每个可能的值添加一个常量来定义消息定义。
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
enum Corpus {
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
NEWS = 4;
PRODUCTS = 5;
VIDEO = 6;
}
Corpus corpus = 4;
}
如您所见,Corpus枚举的第一个常量映射为零:每个枚举定义必须包含一个映射到零的常量作为其第一个元素。这是因为:
- 必须有一个零值,以便我们可以使用0作为数字默认值。
- 零值必须是第一个元素,以便与proto2语义兼容,其中第一个枚举值始终是默认值。
可以通过为不同的枚举常量指定相同的值来定义别名。为此,您需要将allow_alias选项设置为true,否则协议编译器将在找到别名时生成错误消息。
enum EnumAllowingAlias {
option allow_alias = true;
UNKNOWN = 0;
STARTED = 1;
RUNNING = 1;
}
enum EnumNotAllowingAlias {
UNKNOWN = 0;
STARTED = 1;
// RUNNING = 1; // Uncommenting this line will cause a compile error inside Google and a warning message outside.
}
1.8. 选项
.proto文件中的各个声明可以使用许多选项进行注释。选项不会更改声明的整体含义,但可能会影响在特定上下文中处理它的方式。可用选项的完整列表在中定义google/protobuf/descriptor.proto。
一些选项是文件级选项,这意味着它们应该在顶级范围内编写,而不是在任何消息,枚举或服务定义中。一些选项是消息级选项,这意味着它们应该写在消息定义中。一些选项是字段级选项,这意味着它们应该写在字段定义中。选项也可以写在枚举类型,枚举值,服务类型和服务方法上; 但是,目前没有任何有用的选择。
-
java_package(文件选项):用于生成的Java类的包。如果.proto文件中没有给出显式选项java_package,则默认情况下将使用proto包(使用文件中的“package”关键字指定 .proto )。但是,proto包通常不能生成好的Java包,因为proto包不会以反向域名开头。如果不生成Java代码,则此选项无效。option java_package =“com.example.foo”; -
java_multiple_files(文件选项):导致在包级别定义顶级消息,枚举和服务,而不是在.proto文件之后命名的外部类中。option java_multiple_files = true; -
java_outer_classname(file option):要生成的最外层Java类(以及文件名)的类名。如果.proto文件中没有指定java_outer_classname,则通过将.proto文件名转换为驼峰格式(因此foo_bar.proto成为FooBar.java)来构造类名。如果不生成Java代码,则此选项无效。option java_outer_classname =“Ponycopter”; -
optimize_for(文件选项):可以设置为SPEED,CODE_SIZE或LITE_RUNTIME。这会以下列方式影响C ++和Java代码生成器(可能还有第三方生成器):SPEED(默认值):protobuf 编译器将生成用于对消息类型进行序列化,解析和执行其他常见操作的代码。此代码经过高度优化。CODE_SIZE:protobuf 编译器将生成最少的类,并依赖于基于反射的共享代码来实现序列化,解析和各种其他操作。因此生成的代码比使用SPEED小得多,但操作会更慢。类仍将实现与SPEED模式完全相同的公共API 。此模式在包含非常大数量的.proto文件的应用程序中最有用,并且不需要所有文件都非常快速。-
LITE_RUNTIME:protobuf 编译器将生成仅依赖于“lite”运行时库(libprotobuf-lite而不是libprotobuf)的类。精简版运行时比整个库小得多(大约小一个数量级),但省略了描述符和反射等特定功能。这对于在移动电话等受限平台上运行的应用程序尤其有用。编译器仍然会像在SPEED模式中一样生成所有方法的快速实现。生成的类将仅实现MessageLite每种语言的接口,该接口仅提供完整Message接口的方法的子集。option optimize_for = CODE_SIZE;
-
cc_enable_arenas(文件选项):为C ++生成的代码启用竞技场分配。 -
objc_class_prefix(文件选项):设置Objective-C类前缀,该前缀预先添加到此.proto的所有Objective-C生成的类和枚举中。没有默认值。您应该使用Apple建议的 3-5个大写字符之间的前缀。请注意,Apple保留所有2个字母的前缀。 -
deprecated(字段选项):如果设置为true,则表示该字段已弃用,新代码不应使用该字段。在大多数语言中,这没有实际效果。在Java中,这成为一个@Deprecated注释。将来,其他特定于语言的代码生成器可能会在字段的访问器上生成弃用注释,这将导致在编译尝试使用该字段的代码时发出警告。如果任何人都没有使用该字段,并且您希望阻止新用户使用该字段,请考虑使用保留语句替换字段声明。int32 old_field = 6 [deprecated = true];
2. 编码协议
2.1. 编码
于下面的消息,如果a=150时,序列化后会有3个字节08 96 01
message SomeMsg {
int32 a = 1;
}
在Protocol Buffers中采用Base-128变长编码,所谓变长编码是和定长编码相对的,定长编码使用固定字节数来表示,如int32类型的数字固定使用4 bytes表示,而变长编码是需要几个字节就使用几个字节,如对于int32类型的数字1来说,只需要1 bytes足够。Base-128变长编码的原则就两条:
- 每个字节使用使用低7位表示数字,除了最后一个字节,其他字节的最高位都设置为1。
- 采用Little-Endian字节序
每个字节最高位表示后面还有没有字节,低7位就为实际的值
例如1,varint的表示方法就为:
0000 0001
再例如300,4字节表示为:10 0101100,varint表示为:
10101100 00000010
负数的最高位为1,如果负数也使用这种方式表示就会出现一个问题,int32总是需要5个字节,int64总是需要10个字节。
所以定义了另外一种类型:sint32,sint64。采用ZigZag编码,所有的负数都使用正数表示,计算方式:
- sint32: (n « 1) ^ (n » 31)
-
sint64: (n « 1) ^ (n » 63)
- n « 1) ^ (n » 63)
| Signed Original | Encoded As |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| 2147483647 | 4294967294 |
| -2147483648 | 4294967295 |
使用Varint编码的类型有int32, int64, uint32, uint64, sint32, sint64, bool, enum。Java里面没有对应的无符号类型,int32与uint32一样。
2.1. Wire Type
每个消息项前面都会有对应的tag,才能解析对应的数据类型,表示tag的数据类型也是Varint。
tag的格式如下:
(field_number << 3) | wire_type
-field_number: 字段序号
-wire_type: 字段编码类型
一个Protocol Buffers的消息包含一系列字段key/value,每个字段由一个变长32位整数作为字段头,后面跟随字段体。
每种数据类型都有对应的wire_type:
| Wire Type | Meaning Used For |
|---|---|
| 0 | Varint int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit fixed64, sfixed64, double |
| 2 | Length-delimited string, bytes, embedded messages, packed repeated fields |
| 3 | Start group groups (deprecated) |
| 4 | End group groups (deprecated) |
| 5 | 32-bit fixed32, sfixed32, float |
所以wire_type最多只能支持8种,目前有6种。
下面用一个例子来了解一下
message Person {
int32 id = 1;//24
string name = 2;//edgar
string email = 3;//edgar@github.com
}
实际的二进制消息为:
08 18 12 05 65 64 67 61 72 1A 10 65 64 67 61 72 40 67 69 74 68 75 62 2E 63 6F 6D
Person的id,field_number为1,wire_type为0,所以对应的tag为
1 << 3 | 0 = 0x08
Person的name,field_number为2,wire_type为2,所以对应的tag为
2 << 3 | 2 = 0x12
对应Length-delimited的wire type,后面紧跟着的Varint类型表示数据的字节数。
所以name的tag后面紧跟的0x05表示后面的数据长度为5个字节
65 64 67 61 72
同理emal的tag为
3 << 3 | 2 = 0x1a
嵌套的消息类型embedded messages与packed repeated fields也是使用这种方式表示,对应默认值的数据,是不会写进protobuf消息里面的。
packed repeated与repeated的区别在于编码方式不一样,repeated将多个属性类型与值分开存储。而packed repeated采用Length-delimited方式。下面这个是官方文档的例子:
message Test4 {
repeated int32 d = 4 [packed=true];
}
22 // tag (field number 4, wire type 2)
06 // payload size (6 bytes)
03 // first element (varint 3)
8E 02 // second element (varint 270)
9E A7 05 // third element (varint 86942)
如果没有packed的属性是这样存储的:
20 //tag(field number 4,wire type 0)
03 //first element (varint 3)
20 //tag(field number 4,wire type 0)
8E 02//second element (varint 270)
20 //tag(field number 4,wire type 0)
9E A7 05 // third element (varint 86942)
参考资料
https://juejin.im/post/5bb597c2e51d450e6e03e42d
https://worktile.com/tech/share/prototol-buffers
https://www.jianshu.com/p/e0d81a9963e9
