所谓的脑裂,就是指在主从集群中,同时有两个主节点,它们都能接收写请求。而脑裂最直接的影响,就是客户端不知道应该往哪个主节点写入数据,结果就是不同的客户端会往不同的主节点上写入数据。而且,严重的话,脑裂会进一步导致数据丢失。
脑裂发生的原因主要是原主库发生了假故障
- 和主库部署在同一台服务器上的其他程序临时占用了大量资源(例如 CPU 资源),导致主库资源使用受限,短时间内无法响应心跳。其它程序不再使用资源时,主库又恢复正常。
- 主库自身遇到了阻塞的情况,例如,处理 bigkey 或是发生内存 swap(你可以复习下第 19 讲中总结的导致实例阻塞的原因),短时间内无法响应心跳,等主库阻塞解除后,又恢复正常的请求处理了。
1. 为什么脑裂会导致数据丢失?
主从切换后,从库一旦升级为新主库,哨兵就会让原主库执行 slave of 命令,和新主库重新进行全量同步。而在全量同步执行的最后阶段,原主库需要清空本地的数据,加载新主库发送的 RDB 文件,这样一来,原主库在主从切换期间保存的新写数据就丢失了。
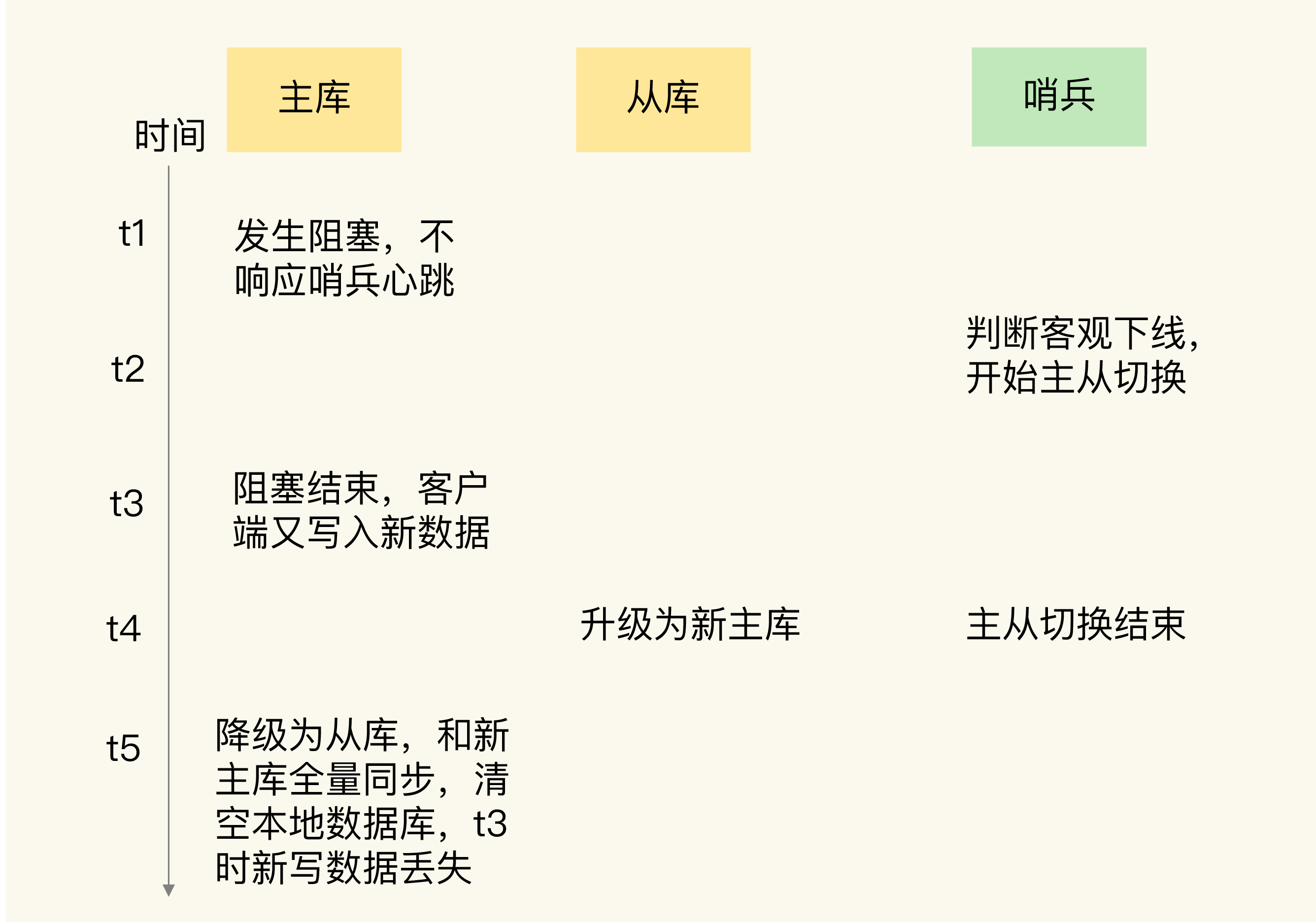
在主从切换的过程中,如果原主库只是“假故障”,它会触发哨兵启动主从切换,一旦等它从假故障中恢复后,又开始处理请求,这样一来,就会和新主库同时存在,形成脑裂。等到哨兵让原主库和新主库做全量同步后,原主库在切换期间保存的数据就丢失了。
2. 如何应对脑裂问题?
Redis 已经提供了两个配置项来限制主库的请求处理,分别是 min-slaves-to-write 和 min-slaves-max-lag。
- min-slaves-to-write:这个配置项设置了主库能进行数据同步的最少从库数量;
- min-slaves-max-lag:这个配置项设置了主从库间进行数据复制时,从库给主库发送 ACK 消息的最大延迟(以秒为单位)。
我们可以把 min-slaves-to-write 和 min-slaves-max-lag 这两个配置项搭配起来使用,分别给它们设置一定的阈值,假设为 N 和 T。这两个配置项组合后的要求是,主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的请求了。
即使原主库是假故障,它在假故障期间也无法响应哨兵心跳,也不能和从库进行同步,自然也就无法和从库进行 ACK 确认了。这样一来,min-slaves-to-write 和 min-slaves-max-lag 的组合要求就无法得到满足,原主库就会被限制接收客户端请求,客户端也就不能在原主库中写入新数据了。
等到新主库上线时,就只有新主库能接收和处理客户端请求,此时,新写的数据会被直接写到新主库中。而原主库会被哨兵降为从库,即使它的数据被清空了,也不会有新数据丢失。
假设我们将 min-slaves-to-write 设置为 1,把 min-slaves-max-lag 设置为 12s,把哨兵的 down-after-milliseconds 设置为 10s,主库因为某些原因卡住了 15s,导致哨兵判断主库客观下线,开始进行主从切换。同时,因为原主库卡住了 15s,没有一个从库能和原主库在 12s 内进行数据复制,原主库也无法接收客户端请求了。这样一来,主从切换完成后,也只有新主库能接收请求,不会发生脑裂,也就不会发生数据丢失的问题了。
为了应对脑裂,你可以在主从集群部署时,通过合理地配置参数 min-slaves-to-write 和 min-slaves-max-lag,来预防脑裂的发生。在实际应用中,可能会因为网络暂时拥塞导致从库暂时和主库的 ACK 消息超时。在这种情况下,并不是主库假故障,我们也不用禁止主库接收请求。所以,我给你的建议是,假设从库有 K 个,可以将 min-slaves-to-write 设置为 K/2+1(如果 K 等于 1,就设为 1),将 min-slaves-max-lag 设置为十几秒(例如 10~20s),在这个配置下,如果有一半以上的从库和主库进行的 ACK 消息延迟超过十几秒,我们就禁止主库接收客户端写请求。
3. 参考资料
《Redis核心技术与实战》
