1. CPU多核
在一个 CPU 核上运行时,应用程序需要记录自身使用的软硬件资源信息(例如栈指针、CPU 核的寄存器值等),我们把这些信息称为运行时信息。同时,应用程序访问最频繁的指令和数据还会被缓存到 L1、L2 缓存上,以便提升执行速度。
但是,在多核 CPU 的场景下,一旦应用程序需要在一个新的 CPU 核上运行,那么,运行时信息就需要重新加载到新的 CPU 核上。而且,新的 CPU 核的 L1、L2 缓存也需要重新加载数据和指令,这会导致程序的运行时间增加。
在 CPU 多核的环境中,一个线程先在一个 CPU 核上运行,之后又切换到另一个 CPU 核上运行,这时就会发生 context switch。当 context switch 发生后,Redis 主线程的运行时信息需要被重新加载到另一个 CPU 核上,而且,此时,另一个 CPU 核上的 L1、L2 缓存中,并没有 Redis 实例之前运行时频繁访问的指令和数据,所以,这些指令和数据都需要重新从 L3 缓存,甚至是内存中加载。这个重新加载的过程是需要花费一定时间的。而且,Redis 实例需要等待这个重新加载的过程完成后,才能开始处理请求,所以,这也会导致一些请求的处理时间增加。
如果在 CPU 多核场景下,Redis 实例被频繁调度到不同 CPU 核上运行的话,那么,对 Redis 实例的请求处理时间影响就更大了。每调度一次,一些请求就会受到运行时信息、指令和数据重新加载过程的影响,这就会导致某些请求的延迟明显高于其他请求。
所以,我们要避免 Redis 总是在不同 CPU 核上来回调度执行。于是,我们尝试着把 Redis 实例和 CPU 核绑定了,让一个 Redis 实例固定运行在一个 CPU 核上。我们可以使用 taskset 命令把一个程序绑定在一个核上运行。
# “-c”选项用于设置要绑定的核编号
taskset -c 0 ./redis-server
2. NUMA 架构
为了提升 Redis 的网络性能,把操作系统的网络中断处理程序和 CPU 核绑定。这个做法可以避免网络中断处理程序在不同核上来回调度执行,的确能有效提升 Redis 的网络处理性能。但是,网络中断程序是要和 Redis 实例进行网络数据交互的,一旦把网络中断程序绑核后,我们就需要注意 Redis 实例是绑在哪个核上了,这会关系到 Redis 访问网络数据的效率高低。
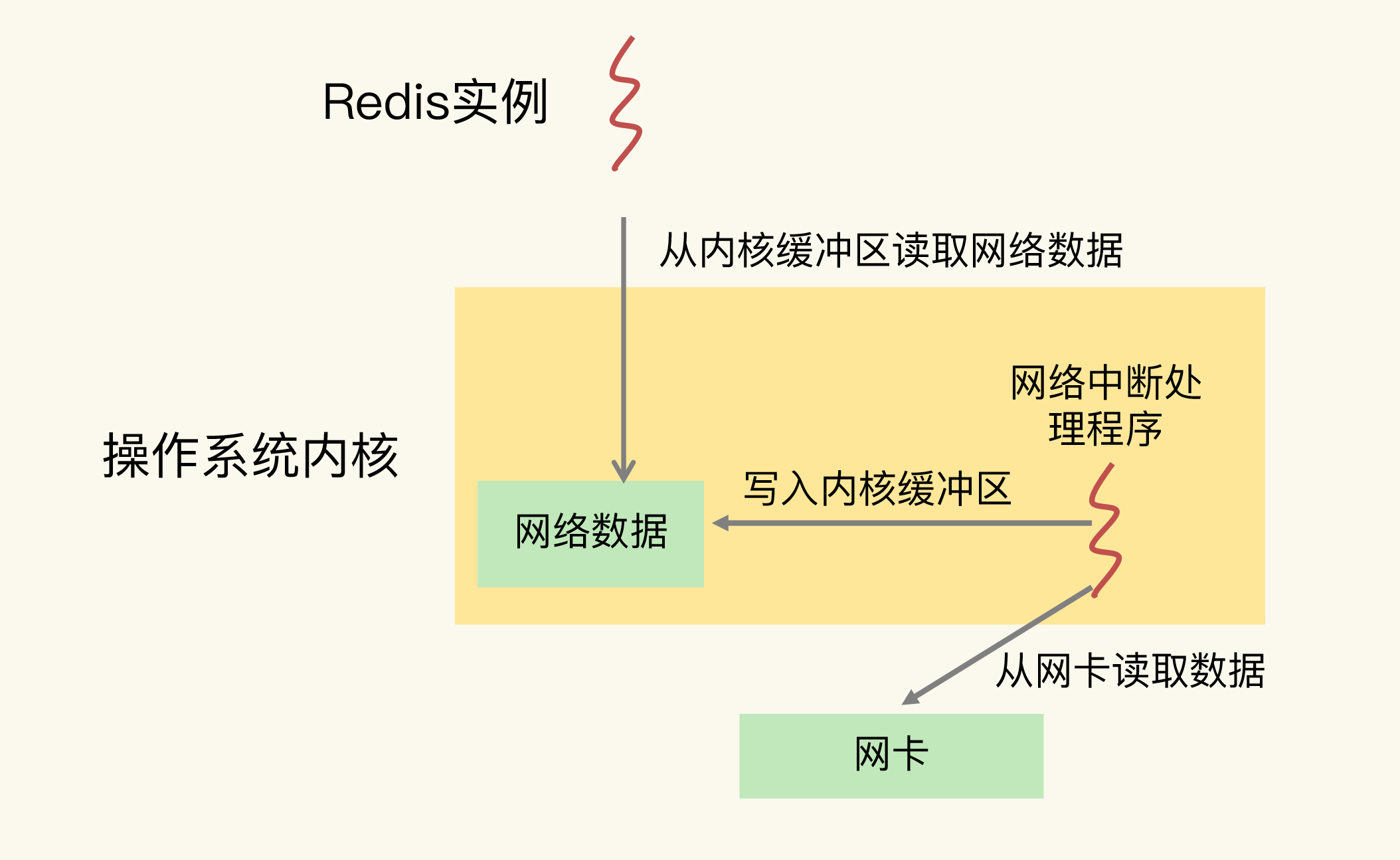
Redis 实例和网络中断程序的数据交互:网络中断处理程序从网卡硬件中读取数据,并把数据写入到操作系统内核维护的一块内存缓冲区。内核会通过 epoll 机制触发事件,通知 Redis 实例,Redis 实例再把数据从内核的内存缓冲区拷贝到自己的内存空间,如下图所示:
在 CPU 的 NUMA 架构下,当网络中断处理程序、Redis 实例分别和 CPU 核绑定后,就会有一个潜在的风险:如果网络中断处理程序和 Redis 实例各自所绑的 CPU 核不在同一个 CPU Socket 上,那么,Redis 实例读取网络数据时,就需要跨 CPU Socket 访问内存,这个过程会花费较多时间。
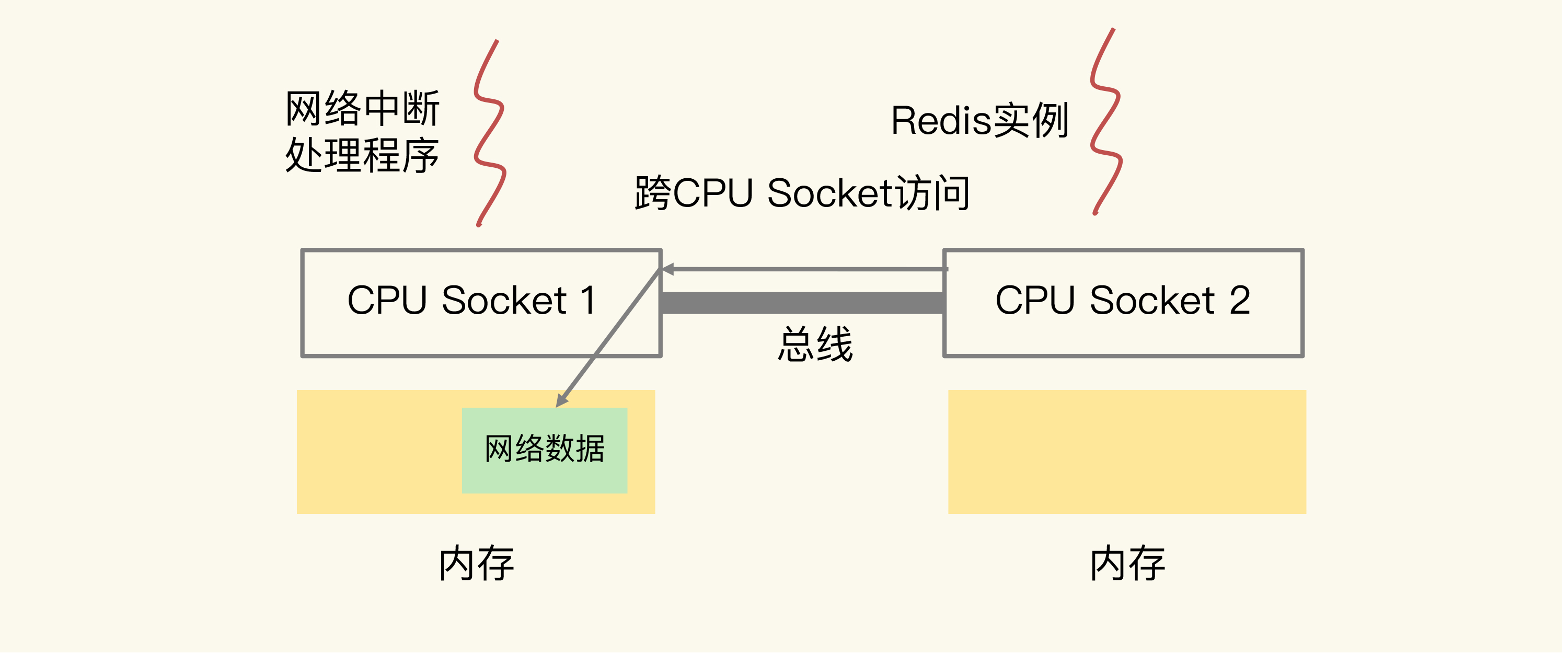
可以看到,图中的网络中断处理程序被绑在了 CPU Socket 1 的某个核上,而 Redis 实例则被绑在了 CPU Socket 2 上。此时,网络中断处理程序读取到的网络数据,被保存在 CPU Socket 1 的本地内存中,当 Redis 实例要访问网络数据时,就需要 Socket 2 通过总线把内存访问命令发送到 Socket 1 上,进行远程访问,时间开销比较大。
为了避免 Redis 跨 CPU Socket 访问网络数据,我们最好把网络中断程序和 Redis 实例绑在同一个 CPU Socket 上(建议不同核),这样一来,Redis 实例就可以直接从本地内存读取网络数据了,如下图所示:
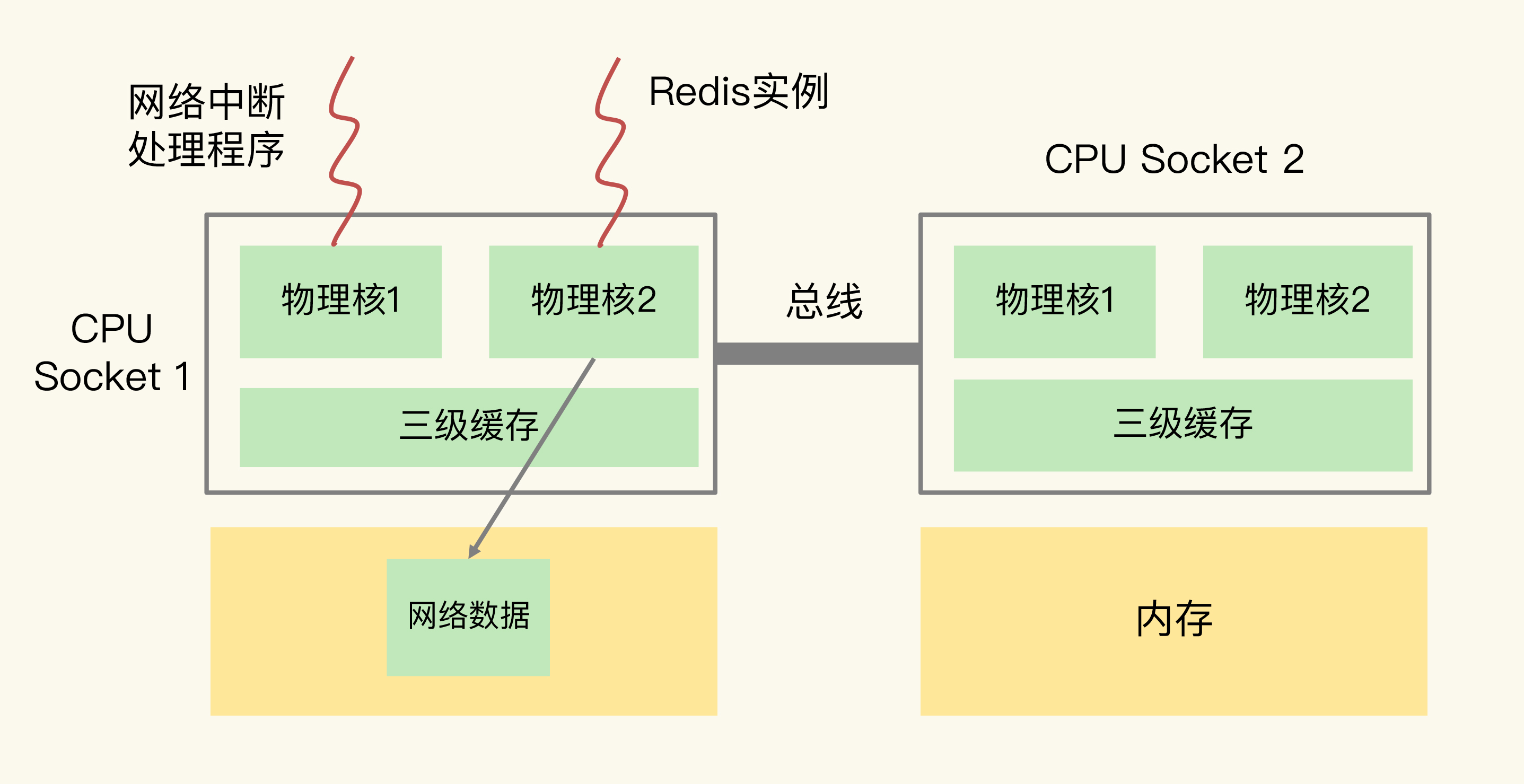
需要注意的是,在 CPU 的 NUMA 架构下,对 CPU 核的编号规则,并不是先把一个 CPU Socket 中的所有逻辑核编完,再对下一个 CPU Socket 中的逻辑核编码,而是先给每个 CPU Socket 中每个物理核的第一个逻辑核依次编号,再给每个 CPU Socket 中的物理核的第二个逻辑核依次编号。
可以通过lscpu查看编号信息
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 45 bits physical, 48 bits virtual
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
...
NUMA node0 CPU(s): 0-3
查看网卡对应的中断号cat /proc/interrupts | grep eth然后我们来看该中断号的CPU绑定情况或者说叫亲和性 affinity
$ sudo cat /proc/irq/74/smp_affinity
ffffff
这个输出是一个16进制的数值,0xffffff = ‘0b111111111111111111111111’,这就意味着这里有24个CPU,所有位都为1表示所有CPU都可以被该中断干扰。
修改配置的方法(设置为2表示将该中断绑定到CPU1上,0x2 = 0b10,而第一个CPU为CPU0)
echo 2 > /proc/irq/74/smp_affinity
3. 绑核的风险
当我们把 Redis 实例绑到一个 CPU 逻辑核上时,就会导致子进程、后台线程和 Redis 主线程竞争 CPU 资源,一旦子进程或后台线程占用 CPU 时,主线程就会被阻塞,导致 Redis 请求延迟增加。
一个 Redis 实例对应绑一个物理核
在给 Redis 实例绑核时,我们不要把一个实例和一个逻辑核绑定,而要和一个物理核绑定,也就是说,把一个物理核的 2 个逻辑核都用上。
# Redis 实例绑定到了逻辑核 0 和 12 上
taskset -c 0,12 ./redis-server
和只绑一个逻辑核相比,把 Redis 实例和物理核绑定,可以让主线程、子进程、后台线程共享使用 2 个逻辑核,可以在一定程度上缓解 CPU 资源竞争。但是,因为只用了 2 个逻辑核,它们相互之间的 CPU 竞争仍然还会存在。如果你还想进一步减少 CPU 竞争,可以通过修改 Redis 源码,把子进程和后台线程绑到不同的 CPU 核上
