Redis 默认的内存分配器采用 jemalloc,可选的分配器还有:glibc、tcmalloc。jemalloc这种分配策略,是按照固定的空间分配,比如8字节、32字节….2KB、4KB等。当应用程序申请的内存接近某个固定值的时候,jemalloc则会分配固定的大小。比如申请了6字节,则会分配8字节的空间。
这种分配的方式的好处很明显,则会减少内存分配的次数,比如申请了20字节的内存,实际分配的是32字节的内存空间,当应用再写入10字节的数据时,则不会再次分配,剩余的12字节足够用了。这样就避免了一次的内存分配。如下图:
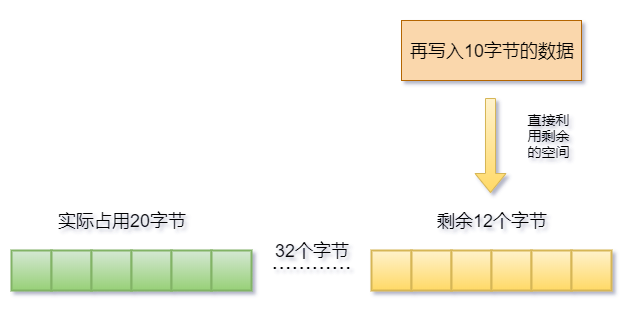
但是坏处也很明显,申请的和分配的空间不一样,则剩余的空间很可能形成内存碎片,一旦内存碎片多了,内存利用率也会随之降低,这是很可怕的。
1. 内存碎片的原因
1.1. 键值对大小不同
Redis作为键值对存储的数据库,本身键值对的大小就是不确定的,正如上面的例子中,Redis申请了20字节的空间,但实际分配却是32字节,那么剩余的12字节则会被闲置成为内存碎片。如下图:
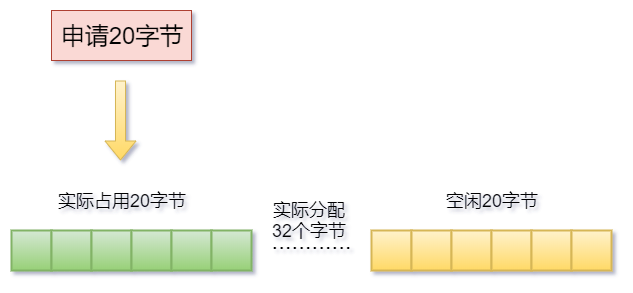
上图中剩余12个字节空间则是闲置的,很有可能成为内存碎片,因此键值对大小不同则会造成一定的内存碎片,这是第一个原因。
1.2. 键值对的修改或者删除
键值对的修改或者删除肯定会造成空间的扩容或者释放;一方面,如果修改后的键值对变大或者变小了,势必会将占用的空间扩大或者释放不用的空间,如下图:

上图中键值对修改后变小了,从原来的10个字节变成了7个字节,从而释放了3个字节,此时剩余了5个字节的空闲空间。
另一方面,如果键值对删除了,则会释放掉占用的空间,形成空闲空间。
2. 如何判断存在内存碎片
Redis自身提供了INFO命令,可以用来查询内存的使用情况,
127.0.0.1:> info memory
# Memory
used_memory:
used_memory_human:130.69M
used_memory_rss:
used_memory_rss_human:.90G
used_memory_peak:
used_memory_peak_human:.26G
used_memory_peak_perc:1.13%
used_memory_overhead:
used_memory_startup:
used_memory_dataset:
used_memory_dataset_perc:98.03%
total_system_memory:
total_system_memory_human:.70G
used_memory_lua:
used_memory_lua_human:.00K
maxmemory:
maxmemory_human:.18G
maxmemory_policy:noeviction
mem_fragmentation_ratio:85.42
mem_allocator:jemalloc-4.0.
active_defrag_running:
lazyfree_pending_objects:
- used_memory:已经使用了的内存大小,包括redis进程内部开销和数据所占用的内存,单位byte。
- used_memory_rss:表示redis物理内存的大小,即向OS申请了多少内存使用
- used_memory_peak:redis内存使用的峰值
- used_memory_lua:执行lua脚本所占用的内存。
- mem_fragmentation_ratio:内存碎片率,计算公式:
mem_fragmentation_ratio = used_memory_rss / used_memory
一些经验阀值
- mem_fragmentation_ratio 大于 1 但小于 1.5:这种情况是合理的。这是因为,刚才我介绍的那些因素是难以避免的。毕竟,内因的内存分配器是一定要使用的,分配策略都是通用的,不会轻易修改;而外因由 Redis 负载决定,也无法限制。所以,存在内存碎片也是正常的。
- mem_fragmentation_ratio 大于 1.5 :这表明内存碎片率已经超过了 50%。一般情况下,这个时候,我们就需要采取一些措施来降低内存碎片率了。
- 小于1: 发生了swap,延迟会变大,性能会降低。
3. 如何清理内存碎片
当 Redis 发生内存碎片后,一个“简单粗暴”的方法就是重启 Redis 实例。当然,这并不是一个“优雅”的方法,毕竟,重启 Redis 会带来两个风险:
- 如果 Redis 中的数据没有持久化,那么,数据就会丢失;
- 即使 Redis 数据持久化了,我们还需要通过 AOF 或 RDB 进行恢复,恢复时长取决于 AOF 或 RDB 的大小,如果只有一个 Redis 实例,恢复阶段无法提供服务。
在Redis 4.0-RC3版本之后,Redis自身提供了一种清除内存碎片的方法
清除的原理很简单,通过复制拷贝将不连续的存放的数据搬到一起形成一块连续的内存空间,如下图:

不过,需要注意的是:碎片清理是有代价的,操作系统需要把多份数据拷贝到新位置,把原有空间释放出来,这会带来时间开销。因为 Redis 是单线程,在数据拷贝时,Redis 只能等着,这就导致 Redis 无法及时处理请求,性能就会降低。而且,有的时候,数据拷贝还需要注意顺序,就像刚刚说的清理内存碎片的例子,操作系统需要先拷贝 D,并释放 D 的空间后,才能拷贝 B。这种对顺序性的要求,会进一步增加 Redis 的等待时间,导致性能降低。
为了缓解这个问题吗?这就要提到,Redis 专门为自动内存碎片清理功机制设置的参数了。我们可以通过设置参数,来控制碎片清理的开始和结束时机,以及占用的 CPU 比例,从而减少碎片清理对 Redis 本身请求处理的性能影响。
activedefrag yes启动自动清理
这个命令只是启用了自动清理功能,但是,具体什么时候清理,会受到下面这两个参数的控制。这两个参数分别设置了触发内存清理的一个条件,如果同时满足这两个条件,就开始清理。在清理的过程中,只要有一个条件不满足了,就停止自动清理。
active-defrag-ignore-bytes 400mb:如果内存碎片达到了400mbactive-defrag-threshold-lower 20:内存碎片空间占操作系统分配给 Redis 的总空间比例达到20%时,开始清理
为了尽可能减少碎片清理对 Redis 正常请求处理的影响,自动内存碎片清理功能在执行时,还会监控清理操作占用的 CPU 时间,而且还设置了两个参数,分别用于控制清理操作占用的 CPU 时间比例的上、下限,既保证清理工作能正常进行,又避免了降低 Redis 性能。这两个参数具体如下:
active-defrag-cycle-min 25:表示自动清理过程所用CPU时间的比例不低于25%,保证清理能正常开展active-defrag-cycle-max 75:表示自动清理过程所用CPU时间的比例不高于75%,一旦超过,就停止清理,从而避免在清理时,大量的内存拷贝阻塞 Redis,导致响应延迟升高。
4. 参考资料
https://juejin.cn/post/6903318022887637005
