1. 序列化
网络传输的数据必须是二进制数据,但调用方请求的出入参数都是对象。对象是不能直接在网络中传输的,所以我们需要提前把它转成可传输的二进制,并且要求转换算法是可逆的,这个过程我们一般叫做“序列化”。 这时,服务提供方就可以正确地从二进制数据中分割出不同的请求,同时根据请求类型和序列化类型,把二进制的消息体逆向还原成请求对象,这个过程我们称之为“反序列化”。
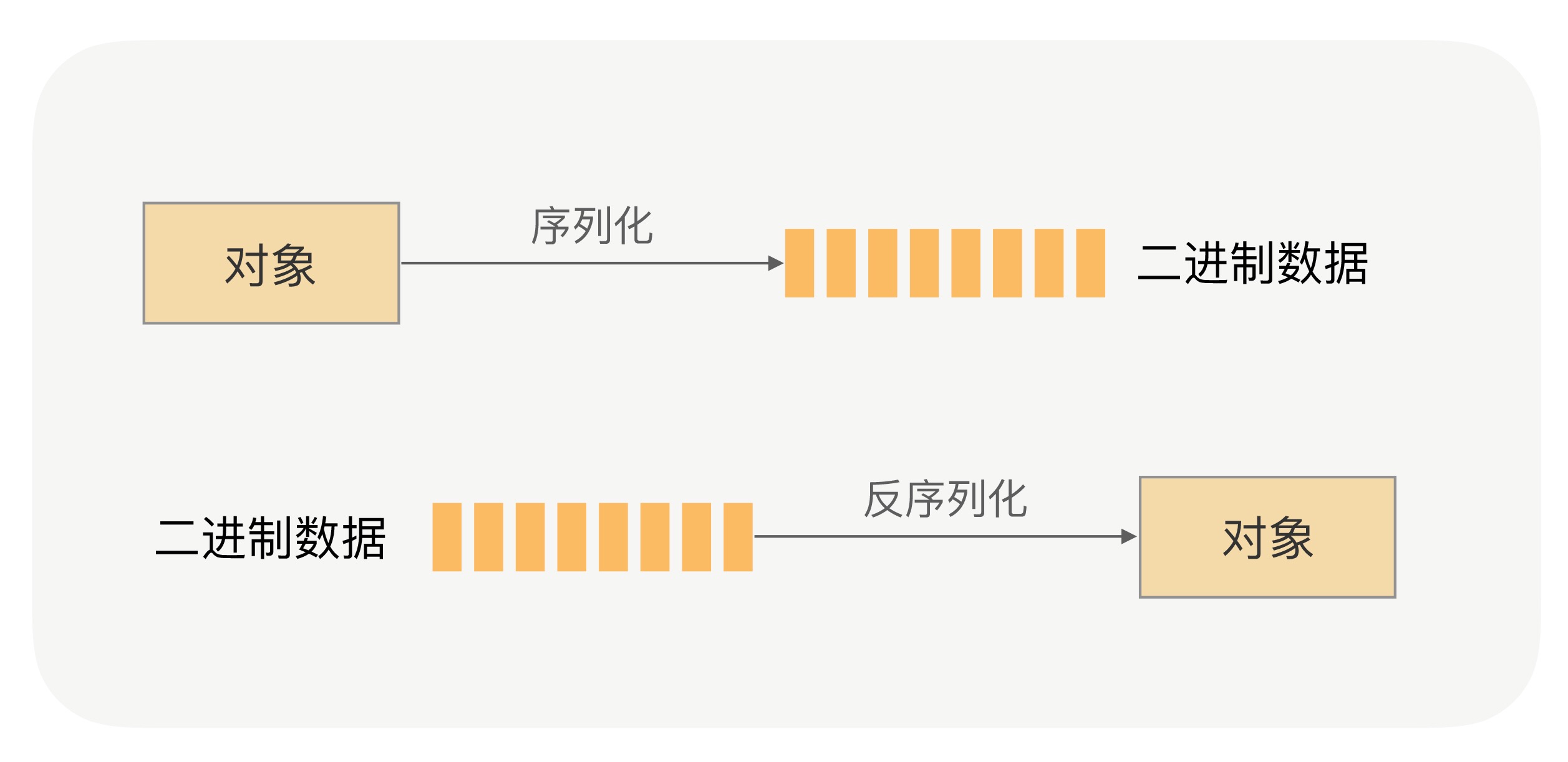
实际上任何一种序列化框架,核心思想就是设计一种序列化协议,将对象的类型、属性类型、属性值一一按照固定的格式写到二进制字节流中来完成序列化,再按照固定的格式一一读出对象的类型、属性类型、属性值,通过这些信息重新创建出一个新的对象,来完成反序列化。
2. 序列化方法
2.1. JDK 原生序列化
2.2. JSON
JSON 可能是我们最熟悉的一种序列化格式了,JSON 是典型的 Key-Value 方式,没有数据类型,是一种文本型序列化框架,JSON 的具体格式和特性,
但用 JSON 进行序列化有这样两个问题需要格外注意:
-
JSON 进行序列化的额外空间开销比较大,对于大数据量服务这意味着需要巨大的内存和磁盘开销;
-
JSON 没有类型,但像 Java 这种强类型语言,需要通过反射统一解决,所以性能不会太好。
所以如果 RPC 框架选用 JSON 序列化,服务提供者与服务调用者之间传输的数据量要相对较小,否则将严重影响性能。
2.3. Protobuf
Protobuf 是 Google 公司内部的混合语言数据标准,是一种轻便、高效的结构化数据存储格式,可以用于结构化数据序列化,支持 Java、Python、C++、Go 等语言。Protobuf 使用的时候需要定义 IDL(Interface description language),然后使用不同语言的 IDL 编译器,生成序列化工具类,它的优点是:
-
序列化后体积相比 JSON,XML小很多;
-
IDL 能清晰地描述语义,所以足以帮助并保证应用程序之间的类型不会丢失,无需类似 XML 解析器;
-
序列化反序列化速度很快,不需要通过反射获取类型;
-
消息格式升级和兼容性不错,可以做到向后兼容。
2.4. 自定义序列化协议
来自《架构师之路》
可以这样设置通用协议

- 头4个字节表示序号
- 序号后面的4个字节表示key的长度m
- 接下来的m个字节表示key的值
- 接下来的4个字节表示value的长度n
- 接下来的n个字节表示value的值
- 像xml一样递归下去,直到描述完整个对象
一个User对象,用这个协议描述出来可能是这样的:

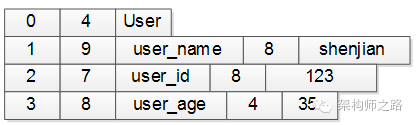
- 第一行:序号4个字节(设0表示类名),类名长度4个字节(长度为4),接下来4个字节是类名(”User”),共12字节
- 第二行:序号4个字节(1表示第一个属性),属性长度4个字节(长度为9),接下来9个字节是属性名(”user_name”),属性值长度4个字节(长度为8),属性值8个字节(值为”shenjian”),共29字节
- 第三行:序号4个字节(2表示第二个属性),属性长度4个字节(长度为7),接下来7个字节是属性名(”user_id”),属性值长度4个字节(长度为8),属性值8个字节(值为123),共27字节
- 第四行:序号4个字节(3表示第三个属性),属性长度4个字节(长度为8),接下来8个字节是属性名(”user_name”),属性值长度4个字节(长度为4),属性值4个字节(值为35),共24字节 整个二进制字节流共12+29+27+24=92字节
3. 序列化协议要考虑什么因素
管使用成熟协议xml/json,还是自定义二进制协议来序列化对象,序列化协议设计时要考虑哪些因素呢?
-
解析效率:这个应该是序列化协议应该首要考虑的因素,像xml/json解析起来比较耗时,需要解析doom树,二进制自定义协议解析起来效率就很高
-
压缩率,传输有效性:同样一个对象,xml/json传输起来有大量的xml标签,信息有效性低,二进制自定义协议占用的空间相对来说就小多了
-
扩展性与兼容性:是否能够方便的增加字段,增加字段后旧版客户端是否需要强制升级,都是需要考虑的问题,xml/json和上面的二进制协议都能够方便的扩展
-
可读性与可调试性:这个很好理解,xml/json的可读性就比二进制协议好很多
-
跨语言:上面的两个协议都是跨语言的,有些序列化协议是与开发语言紧密相关的,例如dubbo的序列化协议就只能支持Java的RPC调用
-
通用性:xml/json非常通用,都有很好的第三方解析库,各个语言解析起来都十分方便,上面自定义的二进制协议虽然能够跨语言,但每个语言都要写一个简易的协议客户端
4. 使用过程中需要注意哪些序列化上的问题
-
对象构造得过于复杂:属性很多,并且存在多层的嵌套,比如 A 对象关联 B 对象,B 对象又聚合 C 对象,C 对象又关联聚合很多其他对象,对象依赖关系过于复杂。序列化框架在序列化与反序列化对象时,对象越复杂就越浪费性能,消耗 CPU,这会严重影响 RPC 框架整体的性能;另外,对象越复杂,在序列化与反序列化的过程中,出现问题的概率就越高。
-
对象过于庞大:比如为一个大 List 或者大 Map,序列化之后字节长度达到了上兆字节。这种情况同样会严重地浪费了性能、CPU,并且序列化一个如此大的对象是很耗费时间的,这肯定会直接影响到请求的耗时。
-
对象有复杂的继承关系:大多数序列化框架在序列化对象时都会将对象的属性一一进行序列化,当有继承关系时,会不停地寻找父类,遍历属性。就像问题 1 一样,对象关系越复杂,就越浪费性能,同时又很容易出现序列化上的问题。
在 RPC 框架的使用过程中,我们要尽量构建简单的对象作为入参和返回值对象,避免上述问题。
在大量并发请求下,如果序列化的速度慢,势必会增加请求和响应的时间(时间开销)。另外,如果序列化后的传输数据体积较大,也会使网络吞吐量下降(空间开销)。所以,你要先考虑上述两点才能保证 RPC 框架的整体性能。除此之外,在 RPC 迭代中,常常会因为序列化协议的兼容性问题使 RPC 框架不稳定,比如某个类型为集合类的入参服务调用者不能解析,某个类的一个属性不能正常调用。推荐Protobuf,因为它在时间开销、空间开销、兼容性等关键指标上表现良好。
5. 参考资料
《RPC实战与核心原理》
《架构师之路》
