1. 为什么需要做数据切分
海量数据的存储和访问成为了MySQL数据库的瓶颈问题,日益增长的业务数据,无疑对MySQL数据库造成了相当大的负载,同时对于系统的稳定性和扩展性提出很高的要求。而单台服务器的资源(CPU、磁盘、内存等)总是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
不管是IO瓶颈还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载的活跃连接数的阈值。在业务service来看, 就是可用数据库连接少甚至无连接可用。
- IO瓶颈
- 磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询会产生大量的IO,降低查询速度
- 网络IO瓶颈,请求的数据太多,网络带宽不够
- CPU瓶颈
- SQl问题:如SQL中包含join,group by, order by,非索引字段条件查询等,增加CPU运算的操作
- 单表数据量太大,查询时扫描的行太多,SQl效率低,增加CPU运算的操作
同时数据文件变大后,数据库备份和恢复需要耗费很长时间。数据文件越大,极端情况下丢失数据的风险越高(例如,机房火灾导致数据库主备机都发生故障)。
基于上述原因,单个数据库服务器存储的数据量不能太大,需要控制在一定的范围内。为了满足业务数据存储的需求,就需要将存储分散到多台数据库服务器上。
关于 MySQL 单库和单表的数据量限制,和不同的服务器配置,以及不同结构的数据存储有关,并没有一个确切的数字。这里参考阿里巴巴的《Java 开发手册》中数据库部分的建表规约:
单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
基于阿里巴巴的海量业务数据和多年实践,这一条数据库规约,可以认为是数据库应用中的一个最佳实践。也就是在新业务建表规划时,或者当前数据库单表已经超过对应的限制,可以进行分库分表,同时也要避免过度设计。因为分库分表虽然可以提高性能,但是盲目地进行分库分表只会增加系统的复杂度。
数据的切分就是通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)中,以达到分散单台设备负载的效果,即分库分表。
数据的切分根据其切分规则的类型,可以分为如下两种切分模式。
- 垂直(纵向)切分:把单一的表拆分成多个表,并分散到不同的数据库(主机)上。
- 水平(横向)切分:根据表中数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上。
2. 垂直切分
2.1. 垂直分库
垂直分库就是根据业务耦合性,将关联度低的不同表存储在不同的数据库。做法与大系统拆分为多个小系统类似,按业务分类进行独立划分。所以我们也可以称为业务分库
一个数据库由多个表构成,每个表对应不同的业务,垂直切分是指按照业务将表进行分类,将其分布到不同的数据库上,这样就将数据分担到了不同的库上(专库专用)。
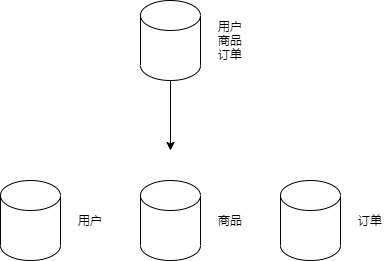
例如,一个简单的电商网站,包括用户、商品、订单三个业务模块,我们可以将用户数据、商品数据、订单数据分开放到三台不同的数据库服务器上,而不是将所有数据都放在一台数据库服务器上。
2.2. 垂直分表
垂直分表是基于数据库中的”列”进行,某个表字段较多,可以新建一张扩展表,将不经常用或字段长度较大的字段拆分出去到扩展表中。
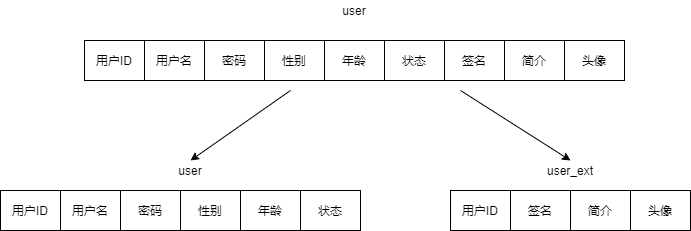
例如我们可以把用户表切分为两个表,一个表包含 ID、用户名、密码、性别、年龄、状态列,另外一个表包含 ID、签名、简介、头像列。
垂直切分的依据是什么
当一个表属性很多时,如何来进行垂直拆分呢?如果没有特殊情况,拆分依据主要有几点:
- 将长度较短,访问频率较高的属性尽量放在一个表里,这个表暂且称为主表
- 将字段较长,访问频率较低的属性尽量放在一个表里,这个表暂且称为扩展表
如果1和2都满足,还可以考虑第三点:
- 经常一起访问的属性,也可以放在一个表里
优先考虑1和2,第3点不是必须。另,如果实在属性过多,主表和扩展表都可以有多个。
需要注意的是,当应用方需要同时访问主表和扩展表中的属性时,服务层不要使用join来连表访问,而应该分两次进行查询。原因是,大数据高并发互联网场景下,一般来说,吞吐量和扩展性是主要矛盾:
- join更消损耗数据库性能
- join会让base表和ext表耦合在一起(必须在一个数据库实例上),不利于数据量大时拆分到不同的数据库实例上(机器上)。毕竟减少数据量,提升性能才是垂直拆分的初衷。
为什么要这么这么拆分
为何要将字段短,访问频率高的属性放到一个表内?为何这么垂直拆分可以提升性能?因为:
- 数据库有自己的内存buffer,会将磁盘上的数据load到内存buffer里
- 内存buffer缓存数据是以row为单位的
- 在内存有限的情况下,在数据库内存buffer里缓存短row,就能缓存更多的数据
- 在数据库内存buffer里缓存访问频率高的row,就能提升缓存命中率,减少磁盘的访问
假设数据库内存buffer为1G,未拆分的user表1行数据大小为1k,那么只能缓存100w行数据。
如果垂直拆分成user和user_ext,其中:
(1)user访问频率高,一行大小为0.1k
(2)user_ext访问频率低,一行大小为0.9k
那边内存buffer就就能缓存近乎1000w行user的记录,访问磁盘的概率会大大降低,数据库访问的时延会大大降低,吞吐量会大大增加。
2.3. 冷热分离
垂直切分除了用于分解单库单表的压力,也用于实现冷热分离,也就是根据数据的活跃度进行拆分,因为对拥有不同活跃度的数据的处理方式不同。
冷热分离就是在处理数据时将数据库分成冷库和热库 2 个库,冷库指存放那些走到了终态的数据的数据库,热库指存放还需要修改的数据的数据库。
例如,对配置表的某些字段很少进行修改时,将其放到一个查询性能较高的数据库硬件上;对配置表的其他字段更新频繁时,则将其放到另一个更新性能较高的数据库硬件上。
这里我们再举一个例子:在微博系统的设计中,一个微博对象包括文章标题、作者、分类、创建时间等属性字段,这些字段的变化频率低,查询次数多,叫作冷数据。而博客的浏览量、回复数、点赞数等类似的统计信息,或者别的变化频率比较高的数据,叫作活跃数据或者热数据。
2.4. 垂直切分的优缺点
垂直切分的优点如下:
- 拆分后业务清晰,拆分规则明确。
- 系统之间进行整合或扩展很容易。
- 按照成本、应用的等级、应用的类型等将表放到不同的机器上,便于管理。
- 便于实现动静分离、冷热分离的数据库表的设计模式。
- 数据维护简单。
垂直切分的缺点如下:
- 部分业务表无法关联(Join),只能通过接口方式解决,提高了系统的复杂度。
- 受每种业务的不同限制,存在单库性能瓶颈,不易进行数据扩展和提升性能。
- 事务处理复杂。
3. 水平切分
与垂直切分对比,水平切分不是将表进行分类,而是将其按照某个字段的某种规则分散到多个库中,在每个表中包含一部分数据,所有表加起来就是全量的数据。
简单来说,我们可以将对数据的水平切分理解为按照数据行进行切分,就是将表中的某些行切分到一个数据库表中,而将其他行切分到其他数据库表中。
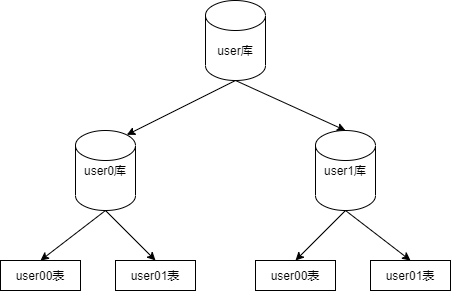
这种切分方式根据单表的数据量的规模来切分,保证单表的容量不会太大,从而保证了单表的查询等处理能力,例如将用户的信息表拆分成User1、User2等,表结构是完全一样的。我们通常根据某些特定的规则来划分表,比如根据用户的ID来取模划分。
例如,在博客系统中,当读取博客的量很大时,就应该采取水平切分来减少每个单表的压力,并提升性能。
以微博表为例,当同时有100万个用户在浏览时,如果是单表,则单表会进行100万次请求,假如是单库,数据库就会承受100万次的请求压力;假如将其分为100个表,并且分布在10个数据库中,每个表进行1万次请求,则每个数据库会承受10万次的请求压力,虽然这不可能绝对平均,但是可以说明问题,这样压力就减少了很多,并且是成倍减少的。
水平切分也分为库内分表和分库分表。库内分表只解决了单一表数据量过大的问题,但没有将表分布到不同机器的库上,因此对于减轻MySQL数据库的压力来说,帮助不是很大,大家还是竞争同一个物理机的CPU、内存、网络IO,最好通过分库分表来解决。
水平切分的优点如下:
- 单库单表的数据保持在一定的量级,有助于性能的提高。
- 切分的表的结构相同,应用层改造较少,只需要增加路由规则即可。
- 提高了系统的稳定性和负载能力。
水平切分的缺点如下:
- 切分后,数据是分散的,很难利用数据库的Join操作,跨库Join性能较差。
- 拆分规则难以抽象。
- 分片事务的一致性难以解决。
- 数据扩容的难度和维护量极大。
4. 分库分表带来的问题
分库分表能有效缓解单机和单表带来的性能瓶颈和压力,突破网络IO、硬件资源、连接数的瓶颈,同时也带来一些问题,
4.1. 事务一致性问题
当更新内容同时分布在不同库中,不可避免会带来跨库事务问题。我们推荐在一个数据库实例中的操作尽可能使用本地事务来保证一致性,跨数据库实例的一系列更新操作需要根据事务路由在不同的数据源中完成,各个数据源之间的更新操作需要通过分布式事务处理。
分布式事务
分布式事务能最大限度保证了数据库操作的原子性。但在提交事务时需要协调多个节点,推后了提交事务的时间点,延长了事务的执行时间。导致事务在访问共享资源时发生冲突或死锁的概率增高。
随着数据库节点的增多,这种趋势会越来越严重,从而成为系统在数据库层面上水平扩展的枷锁。
最终一致性
对于那些性能要求很高,但对一致性要求不高的系统,往往不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,可采用事务补偿的方式。
与事务在执行中发生错误后立即回滚的方式不同,事务补偿是一种事后检查补救的措施。
一些常见的实现方法有:对数据进行对账检查,基于日志进行对比,定期同标准数据来源进行同步等等。事务补偿还要结合业务系统来考虑。
4.2. 跨节点关联查询 join 问题
切分之前,系统中很多列表和详情页所需的数据可以通过 sql join 来完成。
而切分之后,数据可能分布在不同的节点上,此时 join 带来的问题就比较麻烦了,考虑到性能,尽量避免使用 join 查询。
解决这个问题的一些方法:
-
全局表
全局表,也可看做是”数据字典表”,就是系统中所有模块都可能依赖的一些表,为了避免跨库 join 查询,可以将这类表在每个数据库中都保存一份。这些数据通常很少会进行修改,所以也不担心一致性的问题。
-
字段冗余
一种典型的反范式设计,利用空间换时间,为了性能而避免 join 查询。
例如:订单表保存 userId 时候,也将 userName 冗余保存一份,这样查询订单详情时就不需要再去查询”买家 user 表”了。
但这种方法适用场景也有限,比较适用于依赖字段比较少的情况。而冗余字段的数据一致性也较难保证,就像上面订单表的例子,买家修改了 userName 后,是否需要在历史订单中同步更新呢?这也要结合实际业务场景进行考虑。
-
数据组装
在系统层面,分两次查询,第一次查询的结果集中找出关联数据 id,然后根据 id 发起第二次请求得到关联数据。最后将获得到的数据进行字段拼装。
-
ER 分片
关系型数据库中,如果可以先确定表之间的关联关系,并将那些存在关联关系的表记录存放在同一个分片上,那么就能较好的避免跨分片 join 问题。在 1:1 或 1:n 的情况下,通常按照主表的 ID 主键切分。
4.3. 跨节点分页、排序、函数问题
在分库分表以后,如果查询的标准是分片的主键,则可以通过分片规则再次路由并查询;但是对于其他主键的查询、范围查询、关联查询、查询结果排序等,并不是按照分库分表维度来查询的。
例如,用户购买了商品,需要将交易记录保存下来,那么如果按照买家的纬度分表,则每个买家的交易记录都被保存在同一表中,我们可以很快、很方便地查到某个买家的购买情况,但是某个商品被购买的交易数据很有可能分布在多张表中,查找起来比较麻烦。
反之,按照商品维度分表,则可以很方便地查找到该商品的购买情况,但若要查找到买家的交易记录,则会比较麻烦。
所以常见的解决方式如下:
- 在多个分片表查询后合并数据集,这种方式的效率很低。
- 记录两份数据,一份按照买家纬度分表,一份按照商品维度分表。
- 通过搜索引擎解决,但如果实时性要求很高,就需要实现实时搜索。
实际上,在高并发的服务平台下,交易系统是专门做交易的,因为交易是核心服务,SLA的级别比较高,所以需要和查询系统分离,查询一般通过其他系统进行,数据也可能是冗余存储的。
这里再举个例子,在某电商交易平台下,可能有买家查询自己在某一时间段的订单,也可能有卖家查询自己在某一时间段的订单,如果使用了分库分表方案,则这两个需求是难以满足的。
因此,通用的解决方案是,在交易生成时生成一份按照买家分片的数据副本和一份按照卖家分片的数据副本,查询时分别满足之前的两个需求,因此,查询的数据和交易的数据可能是分别存储的,并从不同的系统提供接口。
另外,在电商系统中,在一个交易订单生成后,一般需要引用到订单中交易的商品实体,如果简单地引用,若商品的金额等信息发生变化,则会导致原订单上的商品信息也会发生变化,这样买家会很疑惑。
因此,通用的解决方案是在交易系统中存储商品的快照,在查询交易时使用交易的快照,因为快照是个静态数据,永远都不会更新,所以解决了这个问题。
可见查询的问题最好在单独的系统中使用其他技术来解决,而不是在交易系统中实现各类查询功能;当然,也可以通过对商品的变更实施版本化,在交易订单中引用商品的版本信息,在版本更新时保留商品的旧版本,这也是一种不错的解决方案。
最后,关联的表有可能不在同一数据库中,所以基本不可能进行联合查询,需要借助大数据技术来实现,也就是上面所说的第3种方法,即通过大数据技术统一聚合和处理关系型数据库的数据,然后对外提供查询操作。
4.4. 扩容与迁移
在分库分表后,如果涉及的分片已经达到了承载数据的最大值,就需要对集群进行扩容。扩容是很麻烦的,一般会成倍地扩容。
通用的扩容方法包括如下5个步骤:
- 按照新旧分片规则,对新旧数据库进行双写。
- 将双写前按照旧分片规则写入的历史数据,根据新分片规则迁移写入新的数据库。
- 将按照旧的分片规则查询改为按照新的分片规则查询。
- 将双写数据库逻辑从代码中下线,只按照新的分片规则写入数据。
- 删除按照旧分片规则写入的历史数据。
这里,在第2步迁移历史数据时,由于数据量很大,通常会导致不一致,因此,先清洗旧的数据,洗完后再迁移到新规则的新数据库下,再做全量对比,对比后评估在迁移的过程中是否有数据的更新,如果有的话就再清洗、迁移,最后以对比没有差距为准。
如果是金融交易数据,则最好将动静数据分离,随着时间的流逝,某个时间点之前的数据是不会被更新的,我们就可以拉长双写的时间窗口,这样在足够长的时间流逝后,只需迁移那些不再被更新的历史数据即可,就不会在迁移的过程中由于历史数据被更新而导致代理不一致。
在数据量巨大时,如果数据迁移后没法进行全量对比,就需要进行抽样对比,在进行抽样对比时要根据业务的特点选取一些具有某类特征性的数据进行对比。
在迁移的过程中,数据的更新会导致不一致,可以在线上记录迁移过程中的更新操作的日志,迁移后根据更新日志与历史数据共同决定数据的最新状态,来达到迁移数据的最终一致性。
参考资料
https://juejin.cn/post/6844903992909103117
https://mp.weixin.qq.com/s/GPIVLT3xDc5RBb8ubWqO2g
https://mp.weixin.qq.com/s/RKY-fUxSHZfzDu7bWqHq1A
https://mp.weixin.qq.com/s/ezD0CWHAr0RteC9yrwqyZA
