本文内容基本来自于沈大在架构师之路的文章和直播课程
1. 单KEY业务
1.1. 业务背景
用户中心是一个非常常见的业务,主要提供用户注册、登录、信息查询与修改的服务,其核心元数据为:
User(uid, login_name, passwd, sex, age, nickname, …)
当数据量越来越大时,我们可以基于uid需要对数据库进行水平切分。单这样用户中心的业务访问会带来新的问题。
对于uid属性上的查询可以直接路由到库,假设访问uid=123的数据,取模后能够直接定位user0库。
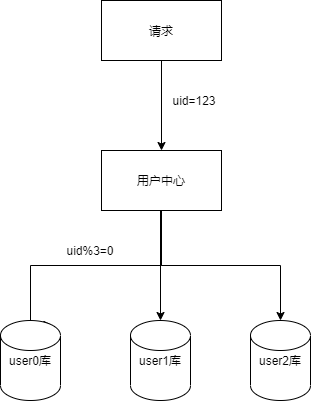
对于非uid属性上的查询,例如login_name属性上的查询,由于我们定位不到具体的数据库,只能遍历查询,当分库数量多起来,性能会显著降低。
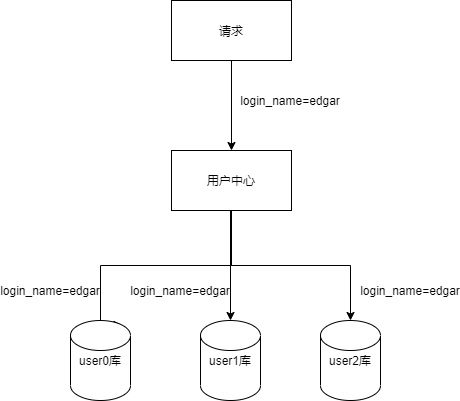
在分库后,针对非uid属性的查询会有问题。下面我们根据业务来分析一下如何解决这个问题。
架构设计需要结合实际业务考虑
用户中心非uid属性上经常有两类业务需求:
- 用户侧,前台访问,最典型的有两类需求
用户登录:通过login_name/phone/email查询用户的实体,1%请求属于这种类型
用户信息查询:登录之后,通过uid来查询用户的实例,99%请求属这种类型
用户侧的查询基本上是单条记录的查询,访问量较大,服务需要高可用,并且对一致性的要求较高。
- 运营侧,后台访问,根据产品、运营需求,访问模式各异,按照年龄、性别、头像、登陆时间、注册时间来进行查询。
运营侧的查询基本上是批量分页的查询,由于是内部系统,访问量很低,对可用性的要求不高,对一致性的要求也没这么严格。
对于非uid属性上的查询需求,架构设计的核心思路为:
- 针对用户侧,应该采用“建立非uid属性到uid的映射关系”的架构方案
- 针对运营侧,应该采用“前台与后台分离”的架构方案
1.2. 用户侧
用户侧因为需要保证高可用和查询性能,我们需要保持水平切分设计。为了解决login_name查询问题,一般有3种方法
- 索引表法
- 缓存映射法
- 基因法
1.2.1 索引表法
索引表法就是通过一个索引表存储login_name和uid之间的映射关系,用login_name来访问时,先通过索引表查询到uid,再定位相应的库。
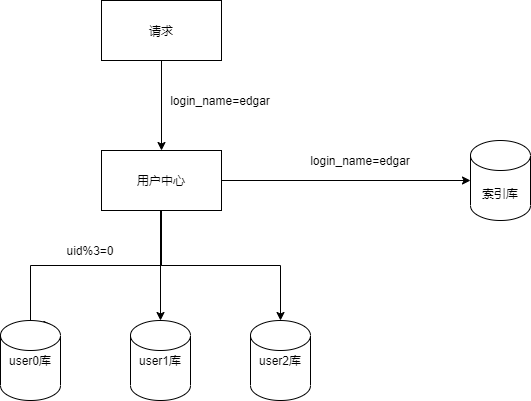
如果索引表的数据量过大,可以考虑通过login_name来分库。
索引表法的缺点就是必须多查询一次,会影响整体性能;而且路由表本身如果太大(例如,几亿条数据),性能同样可能成为瓶颈,又需要对login_name来分库,增加了系统复杂度。
1.2.2. 缓存映射法
因为索引表性能较低,我们可以将映射关系放到缓存中。login_name到uid的映射关系因为不会变更,所以一旦放任缓存不会更改,无需淘汰,缓存命中率超高。
1.2.3. 基因法
不能用login_name生成uid,可以从login_name抽取“基因”,融入uid中。
一般我们的uid都是采用ID生成算法生成的64bit的整数,如果我们分8个库,那么uid的最后3个bit就决定了uid基于hash路由到哪个库上。此时我们只需要在uid的最后3个bit由login_name生成。那么用login_name来访问时,先通过函数由login_name再次复原3bit基因,通过基因%8就可以直接定位到库。

考虑到以后扩容,可以多预留几个bit作为基因
1.3. 运营侧
后台运营侧,业务需求各异,基本是批量分页的访问,这类访问计算量较大,返回数据量较大,比较消耗数据库性能。
如果此时前台业务和后台业务公用一批服务和一个数据库,有可能导致,由于后台的“少数几个请求”的“批量查询”的“低效”访问,导致数据库的cpu偶尔瞬时100%,影响前台正常用户的访问(例如,登录超时)。
此时我们应该采用前台与后台分离的原则,用户侧通过MQ或者binlog方式将数据同步到运营侧

2. 一对多业务
例如帖子业务中,一个用户可以发布多个帖子,而一个帖子只对应一个发布者。90%的请求是根据帖子id查找帖子,10%的请求是根据用户ID查找帖子。如果我们通过帖子id来分库,那么通过用户id就定位不到库,必须扫描全部的库。
针对这种业务,我们可以根据用户ID来分库,采取基因法,在生成帖子id的时候讲用户ID融入到帖子ID里去。方法和前面介绍的基本一致。
3. 多对多业务
例如好友业务中,一个好友表需要保存2个用户id。这时我们可以采用数据冗余的方案
数据冗余是一种满足多维度查询的架构方案
4. 多KEY业务
所谓的“多key”,是指一条元数据中,有多个属性上存在前台在线查询需求。订单中心是一个非常常见的“多key”业务,主要提供订单的查询与修改的服务,其核心元数据为:
Order(oid, buyer_uid, seller_uid, time,money, detail…);
4.1. 业务背景
在进行架构讨论之前,先来对业务进行简要分析,看哪些属性上有查询需求。
前台访问,最典型的有三类需求:
- 订单实体查询:通过oid查询订单实体,90%流量属于这类需求
- 用户订单列表查询:通过buyer_uid分页查询用户历史订单列表,9%流量属于这类需求
- 商家订单列表查询:通过seller_uid分页查询商家历史订单列表,1%流量属于这类需求
前台访问的特点:吞吐量大,服务要求高可用,用户对订单的访问一致性要求高,商家对订单的访问一致性要求相对较低,可以接受一定时间的延时。
后台访问,根据产品、运营需求,访问模式各异:
- 按照时间,架构,商品,详情来进行查询
后台访问的特点:运营侧的查询基本上是批量分页的查询,由于是内部系统,访问量很低,对可用性的要求不高,对一致性的要求也没这么严格,允许秒级甚至十秒级别的查询延时。
因此对于前台和后台我们应该采用前台和后台分离的架构设计。
解决了后台业务的访问需求,问题转化为,前台的oid,buyer_uid,seller_uid如何来进行数据库水平切分?
假设没有seller_uid上的查询需求,而只有oid和buyer_uid上的查询需求,就蜕化为一个“1对多”的业务场景,对于“1对多”的业务,水平切分应该使用“基因法”。
假设没有oid上的查询需求,而只有buyer_uid和seller_uid上的查询需求,就蜕化为一个“多对多”的业务场景,对于“多对多”的业务,水平切分应该使用“数据冗余法”。
通过上述分析:
- 如果没有seller_uid,“多key”业务会蜕化为“1对多”业务,此时应该使用“基因法”分库:使用buyer_uid分库,在oid中加入分库基因
- 如果没有oid,“多key”业务会蜕化为“多对多”业务,此时应该使用“数据冗余法”分库:使用buyer_uid和seller_uid来分别分库,冗余数据,满足不同属性上的查询需求
- 如果oid/buyer_uid/seller_uid同时存在,可以使用上述两种方案的综合方案,来解决“多key”业务的数据库水平切分难题
参考资料
《数据库水平切分架构设计》
https://mp.weixin.qq.com/s/8aI9jS0SXJl5NdcM3TPYuQ
https://mp.weixin.qq.com/s/PCzRAZa9n4aJwHOX-kAhtA
