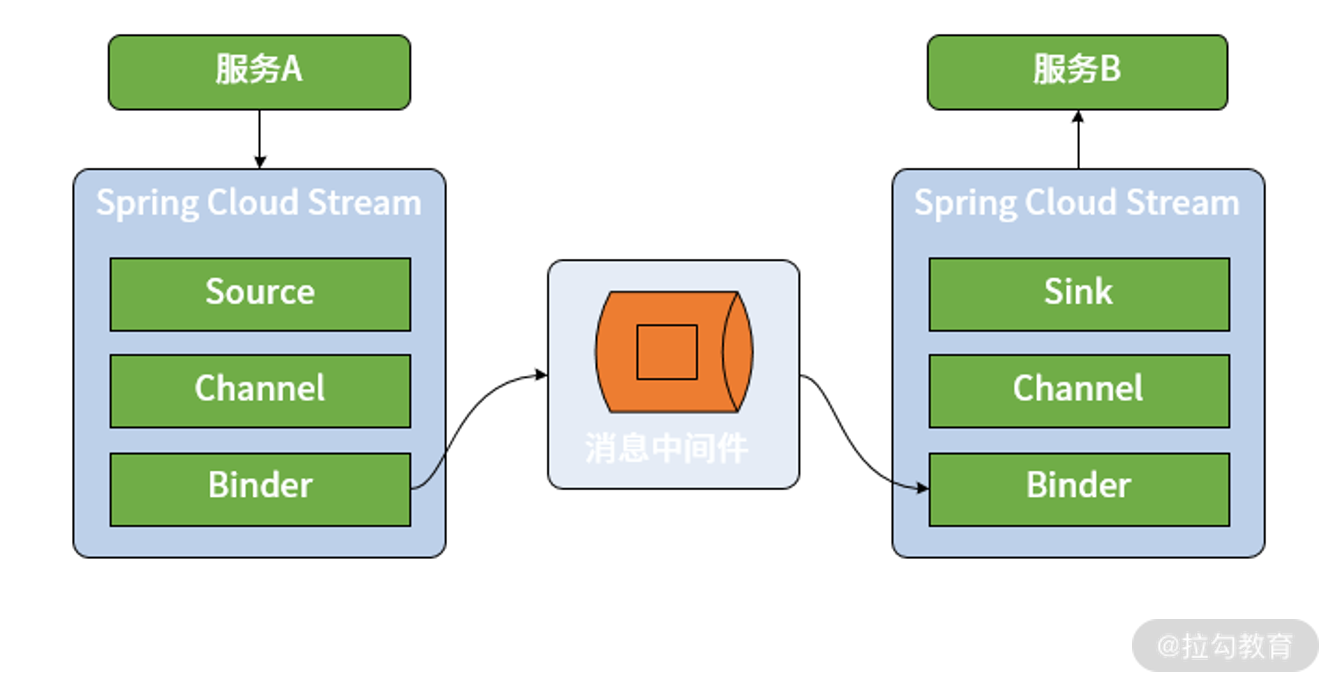
pring Cloud Stream 对整个消息发布和消费过程做了高度抽象,并提供了一系列核心组件。区别于直接使用 RabbitMQ、Kafka 等消息中间件,Spring Cloud Stream 在消息生产者和消费者之间添加了一种桥梁机制,所有的消息都将通过 Spring Cloud Stream 进行发送和接收,如下图所示:
1. 核心组件
Cloud Stream 具备四个核心组件,分别是 Binder、Channel、Source 和 Sink,其中 Binder 和 Channel 成对出现,而 Source 和 Sink 分别面向消息的发布者和消费者。
- Source 和 Sink
在 Spring Cloud Stream 中,Source 组件是真正生成消息的组件,相当于是一个输出(Output)组件。而 Sink 则是真正消费消息的组件,相当于是一个输入(Input)组件。对于同一个 Source 组件而言,不同的微服务可能会实现不同的 Sink 组件,分别根据自身需求进行业务上的处理。
在 Spring Cloud Stream 中,Source 组件使用一个普通的 POJO 对象来充当需要发布的消息,通过将该对象进行序列化(默认的序列化方式是 JSON)然后发布到 Channel 中。另一方面,Sink 组件监听 Channel 并等待消息的到来,一旦有可用消息,Sink 将该消息反序列化为一个 POJO 对象并用于处理业务逻辑。
public interface Source {
/**
* Name of the output channel.
*/
String OUTPUT = "output";
/**
* @return output channel
*/
@Output(Source.OUTPUT)
MessageChannel output();
}
Source通过 MessageChannel 来发送消息,在 MessageChannel 上发现了一个 @Output 注解,该注解定义了一个输出通道。
public interface Sink {
/**
* Input channel name.
*/
String INPUT = "input";
/**
* @return input channel.
*/
@Input(Sink.INPUT)
SubscribableChannel input();
}
Sink通过 Spring Messaging 中的 SubscribableChannel 来实现消息接收,而 @Input 注解定义了一个输入通道。
@Input 和 @Output 注解使用通道名称作为参数,如果没有名称,会使用带注解的方法名字作为参数,也就是默认情况下分别使用“input”和“output”作为通道名称。
- Channel
Channel是对队列的一种抽象。在消息传递系统中,队列的作用就是实现存储转发的媒介,消息生产者所生成的消息都将保存在队列中并由消息消费者进行消费。通道的名称对应的往往就是队列的名称。
- Binder
Spring Cloud Stream 中最重要的概念就是 Binder。所谓 Binder,顾名思义就是一种黏合剂,将业务服务与消息传递系统黏合在一起。通过 Binder,我们可以很方便地连接消息中间件,可以动态的改变消息的目标地址、发送方式而不需要了解其背后的各种消息中间件在实现上的差异。
2. 消息传递模型
Spring Cloud Stream 将消息发布和消费抽象成如下三个核心概念,并结合目前主流的一些消息中间件对这些概念提供了统一的实现方式。
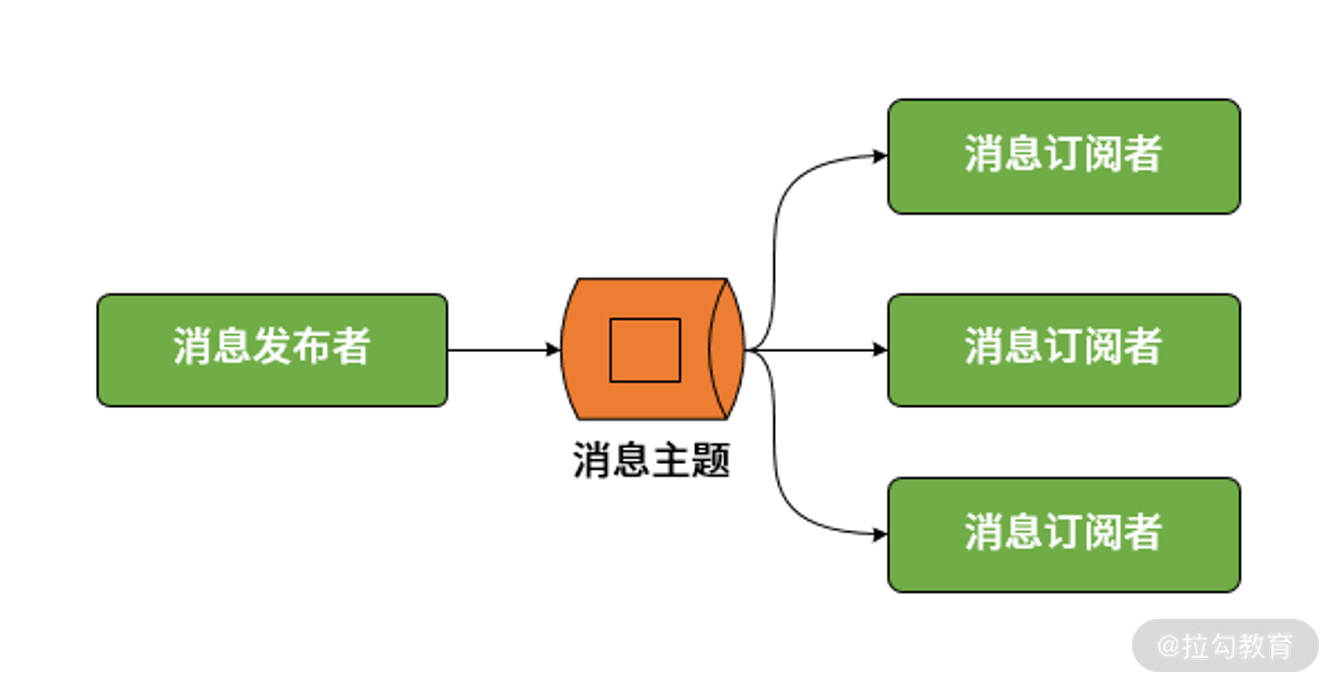
- 发布-订阅模型
我们知道点对点模型和发布-订阅模型是传统消息传递系统的两大基本模型,其中点对点模型实际上可以被视为发布-订阅模型在订阅者数量为 1 时的一种特例。因此,在 Spring Cloud Stream 中,统一通过发布-订阅模型完成消息的发布和消费,如下所示:
- 消费者组
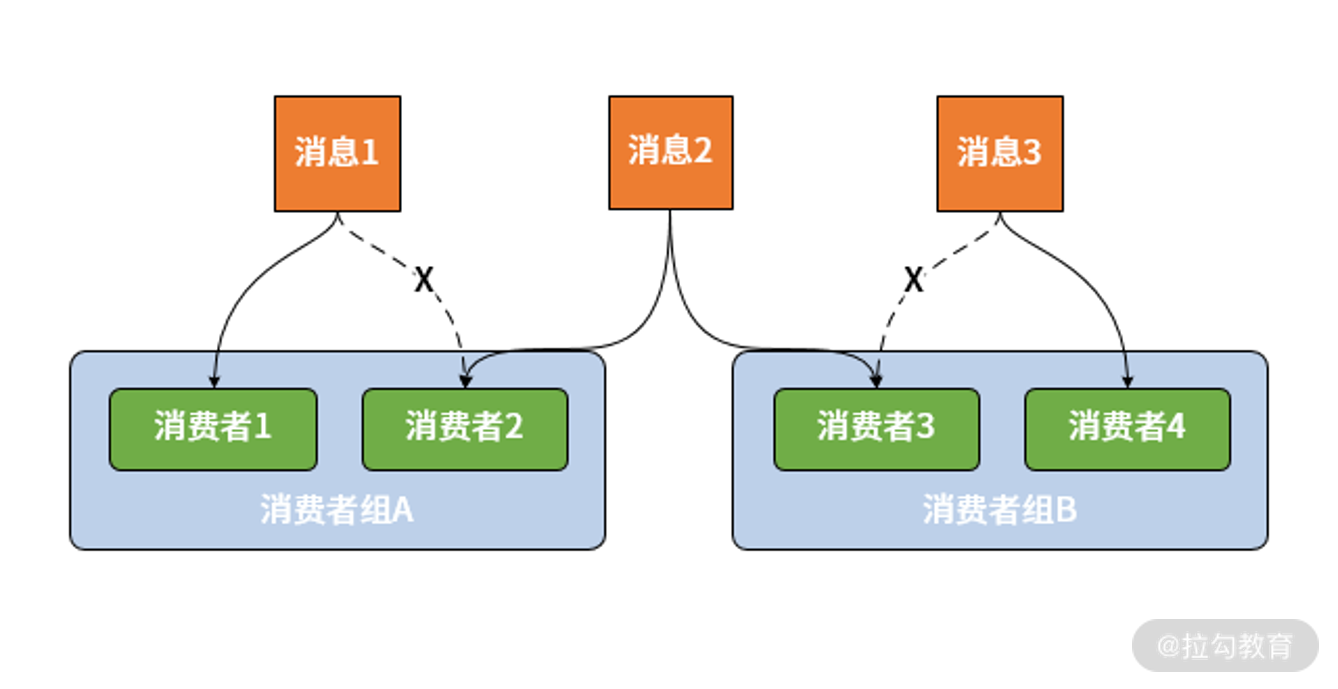
设计消费者组(Consumer Group)的目的是应对集群环境下的多服务实例问题。显然,如果采用发布-订阅模式就会导致一个服务的不同实例都消费到了同一条消息。为了解决这个问题,Spring Cloud Stream 中提供了消费者组的概念。一旦使用了消费组,一条消息就只能被同一个组中的某一个服务实例所消费。消费者的基本结构如下图所示
- 消息分区
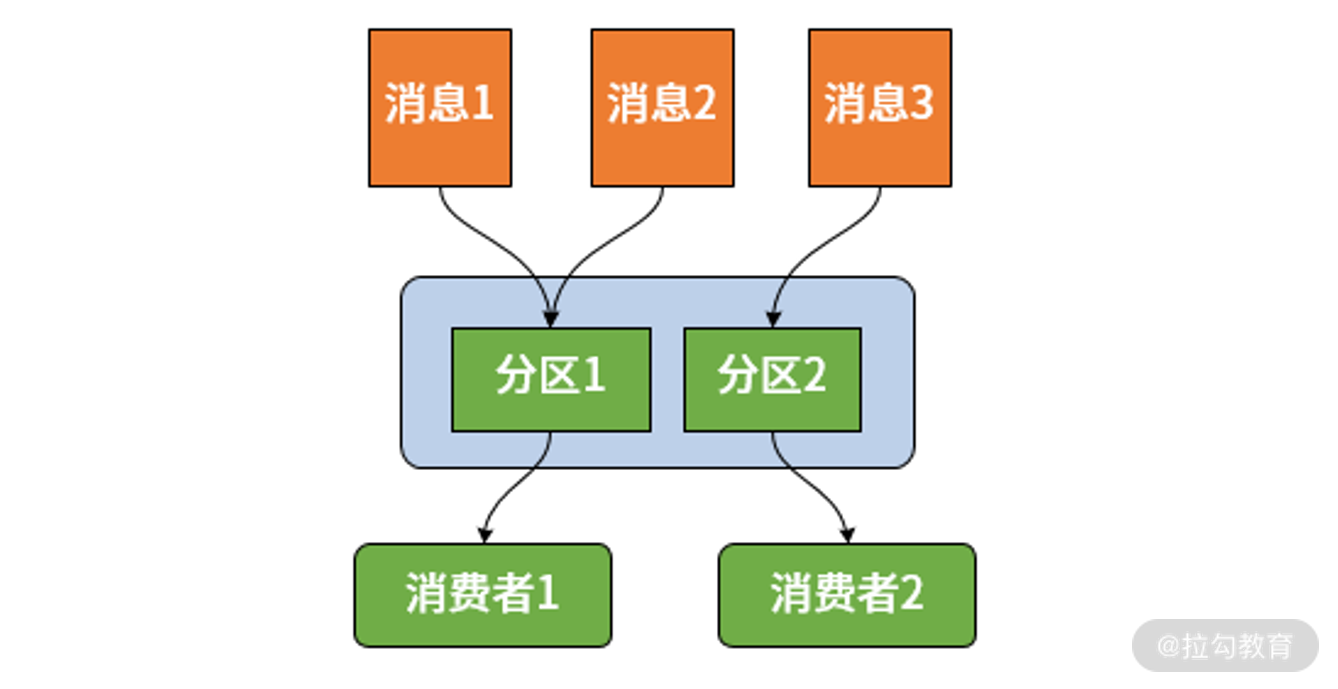
假如我们希望相同的消息都被同一个微服务实例来处理,但又有多个服务实例组成了负载均衡结构,那么通过上述的消费组概念仍然不能满足要求。针对这一场景,Spring Cloud Stream 又引入了消息分区(Partition)的概念。引入分区概念的意义在于,同一分区中的消息能够确保始终是由同一个消费者实例进行消费。
3. Get Started
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
3.1. Source
对于消息发布者而言,它在 Spring Cloud Stream 体系中扮演着 Source 的角色,所以我们需要SpringBoot 应用程序是一个 Source 组件
@SpringBootApplication
@EnableBinding(Source.class)
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
@EnableBinding(Source.class) 注解,该注解的作用就是告诉 Spring Cloud Stream 这个 Spring Boot 应用程序是一个消息发布者,需要绑定到消息中间件,实现两者之间的连接。
定义事件
public class UserChangedEvent {
//事件类型
private String type;
//事件所对应的操作
private String operation;
//事件对应的领域模型
private String username;
}
实现发布消息的Source
@Component
public class UserChangeSource {
@Autowired
private Source source;
public void publish(String username) {
UserChangedEvent event = new UserChangedEvent();
event.setType("UserChangedEvent");
event.setOperation("add");
event.setUsername(username);
source.output().send(MessageBuilder.withPayload(event).build());
}
}
配置Binder
spring:
cloud:
stream:
bindings:
output:
destination: UserChangedTopic
content-type: application/json
kafka:
binder:
brokers: localhost:9092
发送消息
@Component
public class SourceRunner implements ApplicationRunner {
@Autowired
private UserChangeSource userChangeSource;
@Override
public void run(ApplicationArguments args) throws Exception {
userChangeSource.publish("user");
// 发送消息是异步方法,等待几秒用于测试
TimeUnit.SECONDS.sleep(3);
}
}
Kafka会自动创建UserChangedTopic主题,在这个主题里可以看到消息
{"type":"UserChangedEvent","operation":"add","username":"user"}
3.2. Sink
使用@EnableBinding 注解为消费者的启动类绑定 Sink 接口。
@EnableBinding(Sink.class)
创建Sink
@Component
public class UserChangeEventSink {
@StreamListener("input")
public void handle(UserChangedEvent userChangedEvent) {
System.out.println(userChangedEvent);
}
}
将@StreamListener注解添加到某个方法上就可以使之接收处理流中的事件。在上面的例子中,意味着所有流经“input”通道的消息都会交由这个 handle() 方法进行处理。
配置Binder
spring:
cloud:
stream:
bindings:
input:
destination: UserChangedTopic
content-type: application/json
kafka:
binder:
brokers: localhosts:9092
4. 自定义消息通道
在前面的示例中,无论是消息发布还是消息消费,我们都使用了 Spring Cloud Stream 中默认提供的通道名“output”和“input”。显然,在有些场景下,为了更好地管理系统中存在的所有通道,为通道进行命名是一项最佳实践,这点对于消息消费的场景尤为重要。
在 Spring Cloud Stream 中,实现一个面向消息消费场景的自定义通道的方法也非常简单,只需要定义一个新的接口,并在该接口中通过 @Input 注解声明一个新的 Channel 即可。
public interface UserChangedChannel {
@Input("UserChangedChannel")
SubscribableChannel userChangedChannel();
}
旦我们完成了自定义的消息通信,就可以在 @StreamListener 注解中设置这个通道。
@EnableBinding(UserChangedChannel.class)
public class UserChangeEventSink {
@StreamListener("UserChangedChannel")
public void handle(UserChangedEvent userChangedEvent) {
System.out.println(userChangedEvent);
}
}
这里我们使用 @EnableBinding 注解绑定了自定义的 通道
修改Source
public interface UserChangedChannel {
@Output("UserChangedChannel")
MessageChannel userChangedChannel();
}
配置Binder(source和sink都需要调整)
spring:
cloud:
stream:
bindings:
UserChangedChannel:
destination: UserChangedTopic
content-type: application/json
kafka:
binder:
brokers: localhost:9092
发送消息
@Component
public class UserChangeSource {
@Autowired
private UserChangedChannel changedChannel;
public void publish(String username) {
UserChangedEvent event = new UserChangedEvent();
event.setType("UserChangedEvent");
event.setOperation("add");
event.setUsername(username);
changedChannel.userChangedChannel().send(MessageBuilder.withPayload(event).build());
}
}
在UserChangedChannel中可以同时定义多个Input,Output
5. 消费分组
Spring Cloud Stream通过消费者组的概念来模拟这种行为。(Spring Cloud Stream消费者组与Kafka的消费者组相似)每个消费者绑定可以使用spring.cloud.stream.bindings.<channelName>.group属性来指定一个组名。
订阅给定destination的所有分组会接收到发布消息的一个副本,但是在每个组中,只有一个成员会从destination接收到这个消息。默认情况下,没有指定组的时候,Spring Cloud Stream会将应用程序分配到一个匿名、独立且单一的消费者组,这个消费者组与所有其他消费者组都出于同一个发布-订阅关系中。
有2个消费服务,当我们不指定组,或者组不同时,服务都会收到消息。当我们指定相同的消费者组时,只有一个服务收到了消息
6. 消费分区
Spring Cloud Stream支持在一个应用程序的多个实例间分区数据。在分区场景中,物理通信媒介(例如:代理topic)被视为是结构化的多个分区。一个或多个生产者应用实例发送消息到多个消费者应用实例,并确保通过共同特征标识的数据由相同的消费者实例处理。
Spring Cloud Stream为统一实现分区处理提供了一个通用抽象。因此,不管代理自己本来是支持分区的(例如:Kafka)或者不支持分区的(例如:RabbitMQ),都能够使用分区。
在source上指定分区
spring:
cloud:
stream:
bindings:
UserChangedChannel:
content-type: application/json
destination: UserChangedTopic
producer:
partitionKeyExpression: payload.user.id % 2
partitionCount: 2
发送消息报错MessageDispatchingException: Dispatcher has no subscribers,还没搞清楚原因
因为在工作中没有用到stream,后面解决了在更新
在Sink上指定分区
spring:
cloud:
stream:
instanceIndex: 0
instanceCount: 2
bindings:
UserChangedChannel:
destination: UserChangedTopic
content-type: application/json
group: userConsumerGroup1
consumer:
partitioned: true
其中 partitioned=true 表示启用消息分区功能,instanceCount=2 表示消息分区的消费者节点数量为 2 个。特别要注意的是 instanceIndex 参数用来设置当前消费者实例的索引号。instanceIndex 是从 0 开始的,我们在这里就把当前服务实例的索引号为 0。显然我们在另外一个 实例中需要将 instanceIndex 设置为 1。
暂时就整理到这里了,如果后面用到了stream再继续整理
7. 参考资料
《Spring Cloud 原理与实战 》
